先思考
- 什么是过拟合和欠拟合?
- 过拟合与欠拟合回带来什么样的后果?
- 如何解决?
过拟合与欠拟合
通常,我们把学习器的实际预测输出与样本的真实输出之间的差异称为“误差(error)”,学习器在训练集上的误差称为“训练误差”或“经验误差”,在新的样本上的误差称为“泛化误差”。显然,我们希望得到泛化误差小的学习器。
在很多情况下,我们可以得到一个训练误差很小,在训练集上表现很好的学习器,甚至精确度为100%。
我们实际希望的是在新的样本上能表现很好的学习器,为了达到这个目的,应该从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”,这样才能在遇到新的样本时做出正确的判别。
然而,当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本的共同特点,这样就会导致泛化性能下降,泛化误差变大。这种现象在机器学习中就成为“过拟合”。与“过拟合”相对的就是“欠拟合”。
进一步通过图例解释过拟合和欠拟合
过拟合就是训练出来的模型在训练集上表现的很好,但是在测试集上表现较差的一种现象!如下图:
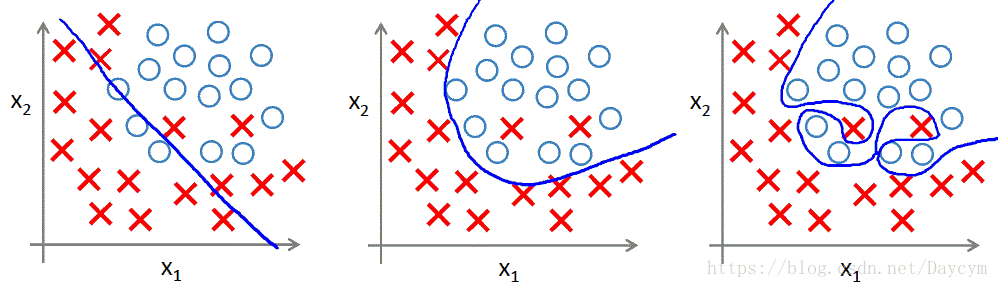
我们将上图中第三个模型解释为出现了过拟合现象,过度拟合了训练数据,而没有考虑到泛化能力。
在训练集上的准确率和在测试集上的准确率变化如下图:
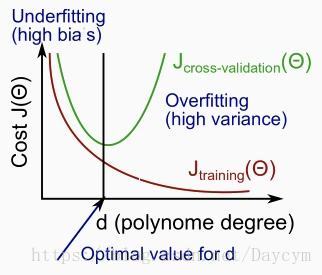
从图中我们可以看出,模型在训练集上表现越来越好,但是在交叉验证集上表现先好后差。这也就是过拟合的特征。
模型出现过拟合的原因
- 学习能力过于强大
- 数据有噪声
- 训练数据不足,有限的训练数据
- 训练模型过度导致模型非常复杂
- …
总结
过拟合的模型具有高方差、低偏差的特点。欠拟合即低方差、高偏差
对于数据的过度关注会导致过拟合,对数据的忽视又会导致欠拟合,那么该怎么办呢?
最理想的方法就是:我们能够用一个模拟测试集对模型进行评估,并且在真实预测之前对模型进行改进。这个模拟测试集被称为验证集
- 过拟合:过度依赖于训练数据
- 欠拟合:无法获取训练数据中存在的关系
- 高方差:一个模型基于训练数据产生了剧烈的变化
- 高偏差:一个忽视了训练数据的模型假设
- 过拟合和欠拟合造成对测试集的低泛化性能
- 使用验证集对模型进行校正可以避免实际过程中造成的过拟合和欠拟合