目录
1、模型的误差和泛化误差
1.1 训练误差
模型在训练数据上的误差
1.2泛化误差(更加关心)
模型在新数据上的误差
1.3 例子
假设一个大学生正在努力准备期末考试。 一个勤奋的学生会努力做好练习,并利用往年的考试题目来测试自己的能力。 尽管如此,在过去的考试题目上取得好成绩并不能保证他会在真正考试时发挥出色。 例如,学生可能试图通过死记硬背考题的答案来做准备。 他甚至可以完全记住过去考试的答案。 另一名学生可能会通过试图理解给出某些答案的原因来做准备。 在大多数情况下,后者会考得更好。
但当这个模型面对从未见过的例子时,它表现的可能比随机猜测好不到哪去。 这是因为输入空间太大了,远远不可能记住每一个可能的输入所对应的答案。
2、训练、验证、测试数据集
2.1 验证数据集
一个用来评估模型好坏的数据集
eg:例如拿出百分之50的训练集
不要跟训练数据混在一起
2.2 测试数据集:
只用一次的数据集。
eg:未来的数据
原则上,在我们确定所有的超参数之前,我们不希望用到测试集。 如果我们在模型选择过程中使用测试数据,可能会有过拟合测试数据的风险,那就麻烦大了。 如果我们过拟合了训练数据,还可以在测试数据上的评估来判断过拟合。 但是如果我们过拟合了测试数据,我们又该怎么知道呢?
因此,我们决不能依靠测试数据进行模型选择。 然而,我们也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
在实际应用中,情况变得更加复杂。 虽然理想情况下我们只会使用测试数据一次, 以评估最好的模型或比较一些模型效果,但现实是测试数据很少在使用一次后被丢弃。 我们很少能有充足的数据来对每一轮实验采用全新测试集。
解决此问题的常见做法是将我们的数据分成三份, 除了训练和测试数据集之外,还增加一个验证数据集(validation dataset), 也叫验证集(validation set)。 但现实是验证数据和测试数据之间的边界模糊得令人担忧。 除非另有明确说明,否则在这本书的实验中, 我们实际上是在使用应该被正确地称为训练数据和验证数据的数据集, 并没有真正的测试数据集。 因此,书中每次实验报告的准确度都是验证集准确度,而不是测试集准确度。
3、K-则交叉验证
前提:在没有足够的数据时使用
算法:
- 原始训练数据被分成K个不重叠的子集
- 执行K次模型训练和验证,每次在K−1个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。
- 通过对K次实验的结果取平均来估计训练和验证误差。
常用:k=5或10
4、过拟合和欠拟合
4.1 过拟合和欠拟合
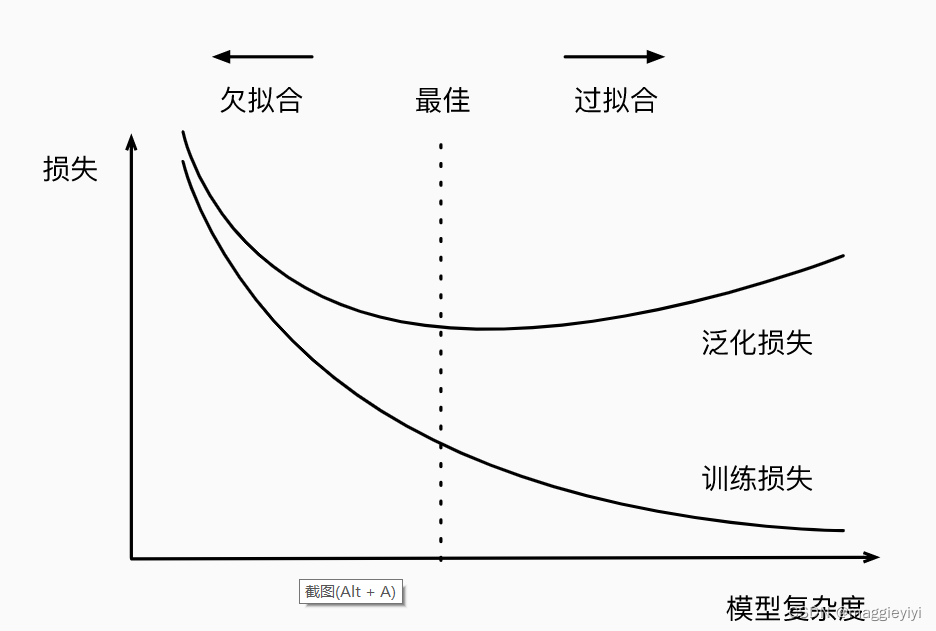
首先,我们要注意这样的情况:训练误差和验证误差都很严重, 但它们之间仅有一点差距。 如果模型不能降低训练误差,这可能意味着模型过于简单(即表达能力不足), 无法捕获试图学习的模式。 此外,由于我们的训练和验证误差之间的泛化误差很小, 我们有理由相信可以用一个更复杂的模型降低训练误差。 这种现象被称为欠拟合(underfitting)。
另一方面,当我们的训练误差明显低于验证误差时要小心, 这表明严重的过拟合(overfitting)。
注意,过拟合并不总是一件坏事。 特别是在深度学习领域,众所周知, 最好的预测模型在训练数据上的表现往往比在保留(验证)数据上好得多。 最终,我们通常更关心验证误差,而不是训练误差和验证误差之间的差距。
4.2 模型容量
拟合各种函数的能力
- 低容量的模型难以拟合训练数据
- 高容量的模型可以记作所有的训练数据
- 难以在不同的种类算法之间比较
- 给定一个模型种类,将有两个主要因素:
- 参数的个数
- 参数的选址范围
4.3 数据复杂度
多个重要因素
- 样本个数
- 每个样本的元素
- 时间、空间结构
- 多样性