一.概述
1.概念:
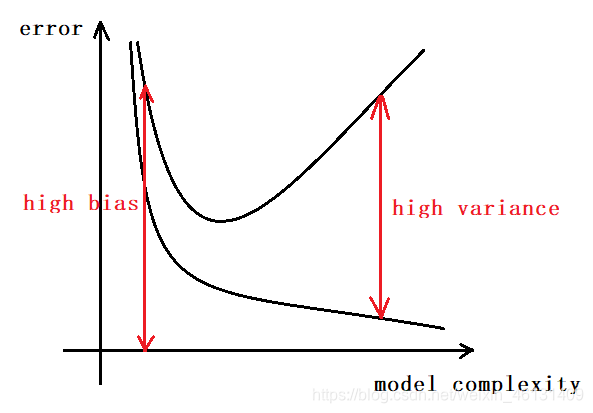
"欠拟合"(Underfitting)是指模型不能在训练集上获得足够低的误差,又称"高偏差"(High Bias)
"过拟合"(Overfitting)是指模型在训练集上表现好,但在测试集上表现差,又称"高方差"(High Variance).即模型对未知样本的预测表现差,"泛化"
(Generalization)能力差
2.原因:
出现过拟合的原因可能是:
①训练集中的样本过于单一
②训练集中的噪声干扰过大
③过度追求与训练集样本的一致性,使模型过于复杂
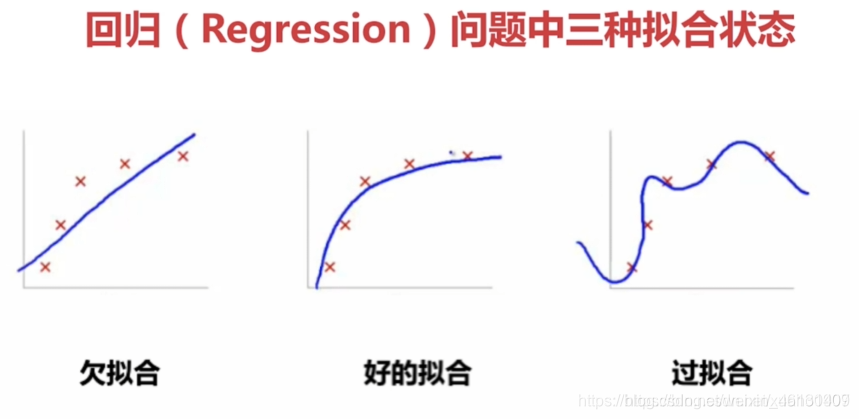
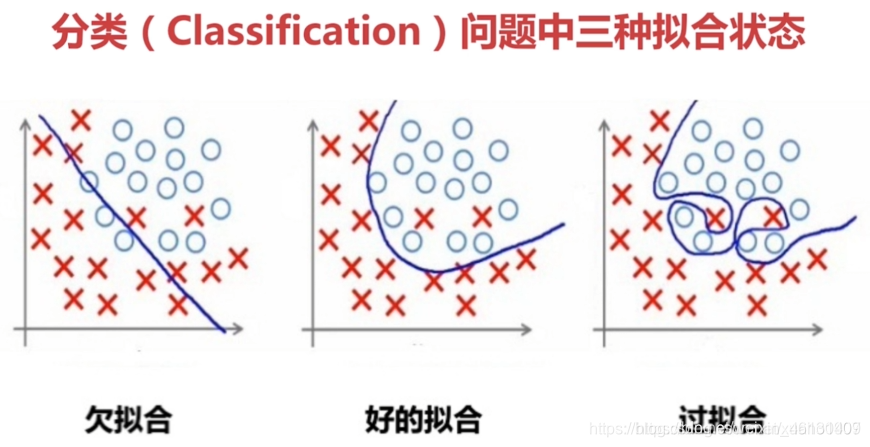
3.学习曲线:
"学习曲线"(Learning Curves)是用于表示样本集大小与训练误差,泛化误差间关系的(2条)曲线
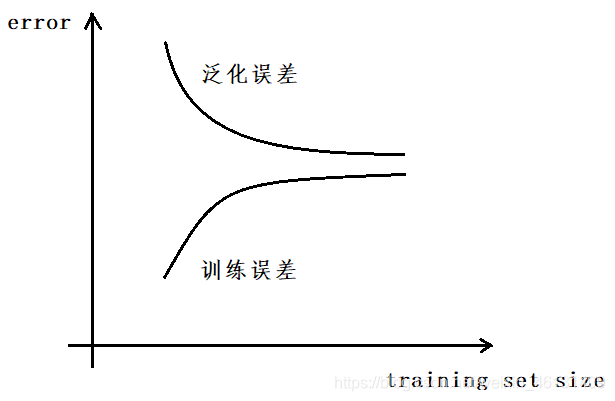
在过拟合的情况下,则不论数据集有多大,泛化误差都不会下降太多;而在欠拟合的情况下,增大数据集可有效降低泛化误差
二.解决方法
欠拟合的解决方法主要为
①增加新特征
②使用更复杂的模型
③降低正则化的惩罚力度
④延长训练时间
过拟合的解决方法主要为:
①减少特征,如PCA
②增大训练集
③增大正则化的惩罚力度
1.正则化
(1)概念:
"正则化"(Regularization)是1种用于避免过拟合的技术.使用正则化时,样本的所有特征都会被保留;但会对指定参数θj进行惩罚,从而减小其值来减小
对应项的影响.如使用多项式进行预测时,常需要减小高次项的影响.这种方法在每个特征都对预测有贡献时比PCA等会丢弃部分特征的方法更有效
(2)实现:
正则化的一般形式为 min 1 2 m { ∑ i = 1 m [ y i − h β ( x i ) ] 2 + r ( β ) } \min{\frac{1}{2m}\{\displaystyle\sum_{i=1}^m[y_i-h_β(x_i)]^2+r(β)}\} min2m1{ i=1∑m[yi−hβ(xi)]2+r(β)}其中 ( x i , y i ) (x_i,y_i) (xi,yi)是第 i i i条数据, h β ( x ) h_β(x) hβ(x)是预测器, r ( β ) r(β) r(β)用于对指定参数进行惩罚.如果特征非常多,不知道应该对哪些参数进行惩罚,则可以通过最优化来确定对各参数的惩罚程度,一般形式为 min 1 2 m { ∑ i = 1 m [ y i − h β ( x i ) ] 2 + λ ∑ j = 1 n β j 2 } \min{\frac{1}{2m}\{\displaystyle\sum_{i=1}^m[y_i-h_β(x_i)]^2+λ\displaystyle\sum_{j=1}^nβ_j^2}\} min2m1{ i=1∑m[yi−hβ(xi)]2+λj=1∑nβj2}其中 λ λ λ称为正则化参数(Regularization Parameter),用于确定对各参数的惩罚程度.另外,根据惯例,不对常数项 β 0 β_0 β0进行惩罚
(3)正则化参数的选择:
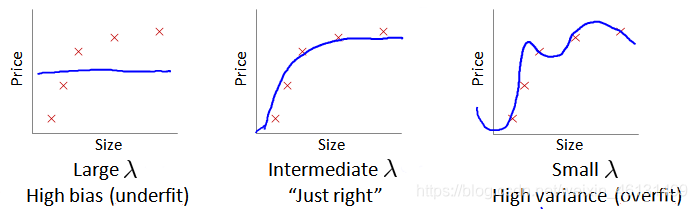
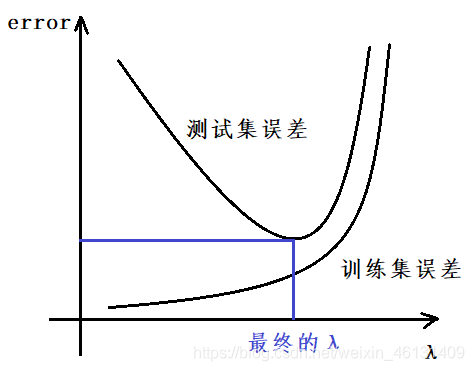
2.丢弃特征
参见 数据分析.数据规约.二 部分