过拟合:
在训练集中表现优越,在验证测试集中表现较差。准确率较低。
在机器学习中,过拟合会使模型的预测边差,通常发生在模型过于复杂的情况下。
如果模型过于专注于特定的训练数据而错过了要点,那么模型就被认为过拟合。
如何防止过拟合:
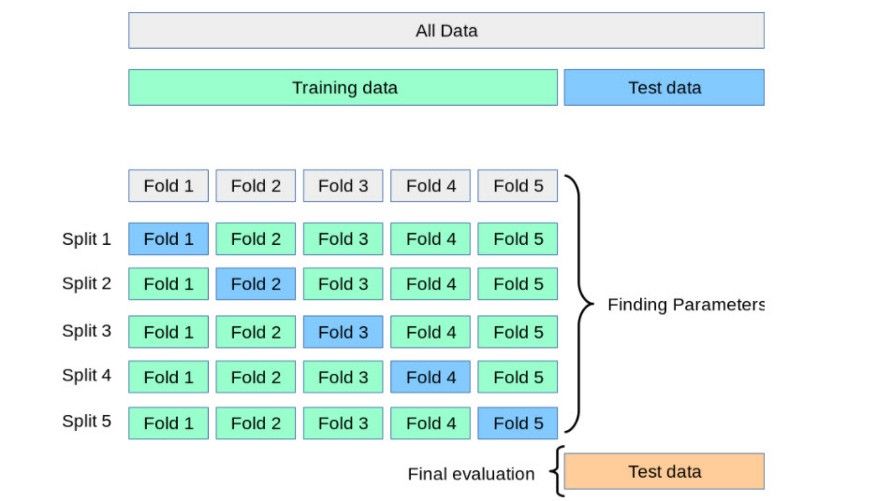
1:交叉验证(K-折验证)
将数据拆分为K份
交叉验证允许调整超参数,性能是所有值的平均值。该方法计算成本较高,但不会浪费太多数据。
增加训练数据
用更多相关数据训练模型有助于更好地识别信号,避免将噪声作为信号干扰。
同时也可以使用数据增强的方式:翻转、平移、旋转、缩放、HSV、透视变换等。
移除特征
减少模型的复杂性,通过移除层或者减少神经元的数量。
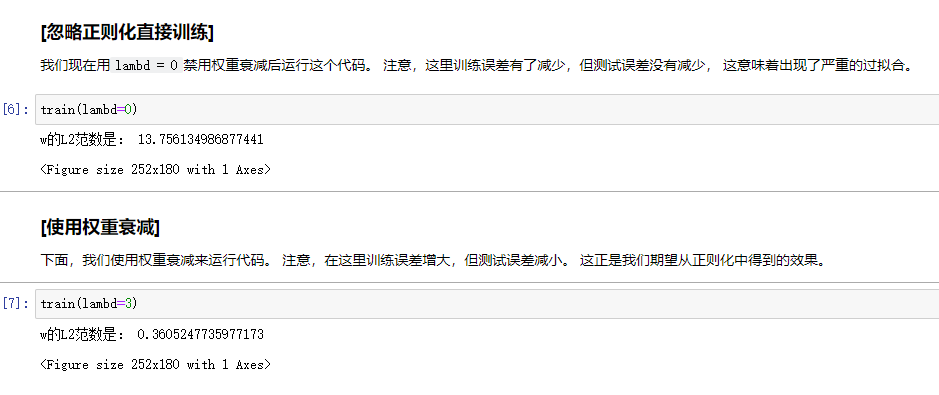
正则化
正则化可用于降低模型的复杂性。这是通过惩罚损失函数完成的,有L1和L2正则化两种方式。
L1正则化:惩罚权重绝对值的总和
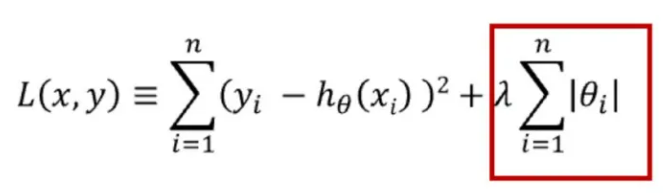
L2正则化:惩罚权重值的平方和
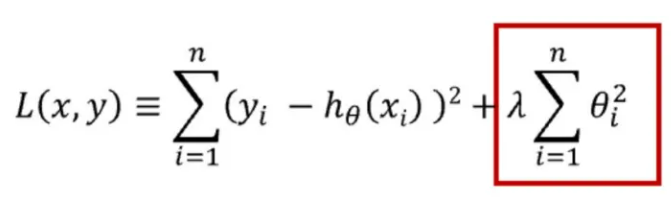
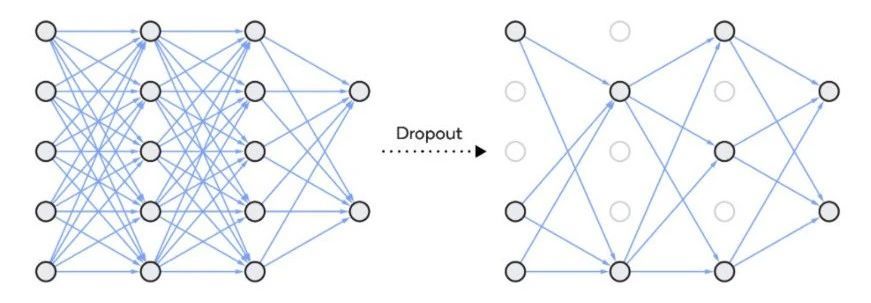
Deopout
Dropout 是一种正则化方法,用于随机禁用神经网络单元。它可以在任何隐藏层或输入层上实现,但不能在输出层上实现。该方法可以免除对其他神经元的依赖,进而使网络学习独立的相关性。该方法能够降低网络的密度,
简单实现


欠拟合
训练误差和验证误差都很大,这种情况称为欠拟合。出现欠拟合的原因是模型尚未学习到数据的真实结构。因此,模拟在训练集和验证集上的性能都很差。
解决办法:
1、做特征工程,添加很多的特征项。如果欠拟合是由于特征项不够,没有足够的信息支持模型做判断。
2、增加模型复杂度。如果模型太简单,不能够应对复杂的任务。可以使用更复杂的模型,减小正则化系数。具体来说可以使用核函数,集成学习方法。
3、 集成学习方法boosting(如GBDT)能有效解决high bias