正则化
正则化意义
正则化用于减少网络过拟合,减少拟合误差。正则化操作是在原先的损失函数后边再加多一项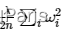 ,可以约束模型的权重,较大的取值将较大程度约束模型权重,反之亦然。通常,我们只对权重w,而不对b进行惩罚,因为w有很多参数,b只有一个,对b进行惩罚对结果的影响微乎其微,因此,通常忽略。
,可以约束模型的权重,较大的取值将较大程度约束模型权重,反之亦然。通常,我们只对权重w,而不对b进行惩罚,因为w有很多参数,b只有一个,对b进行惩罚对结果的影响微乎其微,因此,通常忽略。
正则化公式
正则化公式如下,第一项为交叉熵损失,后一项则为惩罚项,即为正则化操作多加的一项。这个公式也叫做L2正则化,因为惩罚项采用L2范数,L2范数即对所有权重的平方求和。还有L1正则化,即惩罚项采用L1范数,L1范数即对所有权重的求和。目前通常采用L2正则化。
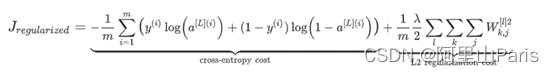
正则化能减少过拟合的原因
假设λ变的无穷大,那么权重w趋向于0,则大部分的神经元相当于不起任何作用,则该神经网络趋向于变成logistics回归,那么深度学习网络由过拟合变成欠拟合,因此,加上合适的惩罚项后,在参数更新时,可以达到权重衰减的目的。权重衰减意味着衰减的神经元对神经网络的影响减小,使得原本复杂的神经网络变得简单,最终可以达到一个最佳的拟合状态。
Dropout正则化
Dropout正则化也能减少过拟合
Dropout正则化也叫随机失活正则化,通常我们用Inverted(反转) Dropout。是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
Dropout正则化中的一个重要参数是keep_drop,如keep_drop=0.8,则需要舍弃20%的结点,只保留80%的结点,keep_drop=1,则全部保留,相当于没有用Dropout正则化。
由于加入Dropout正则化后,不会像L2正则化那样会呈现单调下降趋势,因此,在实际应用过程中,我们通常先将keep_drop设为1,看损失是否单调下降,调好L2正则化之后再改变keep_drop。
Dropout为何能减少过拟合
以下内容引用自:
作者:zzkdev
链接:https://www.jianshu.com/p/257d3da535ab
来源:简书
“由于每次用输入网络的样本进行权值更新时,隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现,这样权值的更新不再依赖于有固定关系隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况,减少神经元之间复杂的共适应性。
由于每一次都会随机地删除节点,下一个节点的输出不再那么依靠上一个节点,也就是说它在分配权重时,不会给上一层的某一结点非配过多的权重,起到了和L2正则化压缩权重差不多的作用。
可以将dropout看作是模型平均的一种,平均一个大量不同的网络。不同的网络在不同的情况下过拟合,虽然不同的网络可能会产生不同程度的过拟合,但是将其公用一个损失函数,相当于对其同时进行了优化,取了平均,因此可以较为有效地防止过拟合的发生。对于每次输入到网络中的样本(可能是一个样本,也可能是一个batch的样本),其对应的网络结构都是不同的,但所有的这些不同的网络结构又同时共享隐含节点的权值,这种平均的架构被发现通常是十分有用的来减少过拟合方法。”
数据扩充
包括翻转、镜像、局部放大、局部缩小、扭曲等
Early stopping(早停机制)
每个epoch结束后(或每N个epoch后): 在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练;将停止之后的权重作为网络的最终参数。一般的做法是,在训练的过程中,记录到目前为止最好的验证集精度,当连续10次Epoch(或者更多次)没达到最佳精度时,则可以认为精度不再提高了。
它的缺点为没有采取不同的方式来解决优化损失函数和降低方差这两个问题,而是用一种方法同时解决两个问题 ,结果就是要考虑的东西变得更复杂。之所以不能独立地处理,因为如果你停止了优化代价函数,你可能会发现代价函数的值不够小,同时你又不希望过拟合。