获取所需数据集:
import os
import pandas as pd
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT="https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH="datasets/housing"
HOUSING_URL=DOWNLOAD_ROOT+HOUSING_PATH+"/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL,housing_path=HOUSING_PATH): #下载数据集
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path=os.path.join(housing_path,"housing.tgz") #拼接路径
urllib.request.urlretrieve(housing_url,tgz_path) #下载为 housing.tgz压缩文件
housing_tgz=tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path) # 解压
housing_tgz.close()
def load_housing_data(housing_path=HOUSING_PATH): #加载数据集
csv_path=os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path) #加载为csv数据类型
快速查看数据结构(属性、特征信息):
fetch_housing_data() housing=load_housing_data() # housing.head() #查看数据集前5行 # housing.info() #查看数据集的简单描述 # housing["ocean_proximity"].value_counts() #查看类型值属性的值的分类情况 # housing.describe() #显示数值属性摘要,不包括类型值属性 # housing.hist(bins=20,figsize=(20,15)) #各属性的直方图,bins参数设置直方个数
纯随机抽样,产生测试数据集,占完整数据集的20%:
# from sklearn.model_selection import train_test_split # train_set,test_set=train_test_split(housing,test_size=0.2,random_state=42) #纯随机抽样,未考虑按照某一属性分层抽样 # print(len(train_set),len(test_set))
纯随机抽样获取测试集会产生偏差。因为纯随机抽样过程没有考虑不同特征值的分布情况。此例中,要预测的房价平均值与数据集中的收入中位数这一特征值有很大的关系,所以,抽样应符合收入中位数的分布情况,即基于收入中位数的分层抽样。
由于收入中位数是连续的数值属性,需要首先创建一个收入类别的属性,然后把每个类别当成一个层,才能分层抽样。
此例中,大多数收入中位数在2-5之间。数据集中,每一层都要有足够多的实例,所以不能将层数划分的太多。
创建收入类别属性:将收入中位数除以1.5(限制收入类别的数量),然后使用ceil函数取整得到离散类别,最后将所有大于5的类别合并为类别5:
import numpy as np housing['income_type']=np.ceil(housing['median_income']/1.5) housing['income_type'].where(housing['income_type']<5,5.0,inplace=True)
根据收入类别进行分层抽样,使用sklearn的StratifiedShuffleSplit方法:
from sklearn.model_selection import StratifiedShuffleSplit
split=StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42)
for train_index,test_index in split.split(housing,housing['income_type']):
strat_train_set=housing.loc[train_index]
strat_test_set=housing.loc[test_index]
housing['income_type'].value_counts()/len(housing) #计算完整数据集中每个类别占的比例
输出为:
3.0 0.350581 2.0 0.318847 4.0 0.176308 5.0 0.114438 1.0 0.039826 Name: income_type, dtype: float64
分层抽样结束后,添加的收入中位数类别属性就用不到了,删除此属性:
for set in (strat_train_set,strat_test_set):
set.drop(['income_type'],axis=1,inplace=True)
至此,数据预处理完成。
从数据探索和可视化中获得洞见
创建训练集的副本用来操作,避免损坏训练集。
housing=strat_train_set.copy()
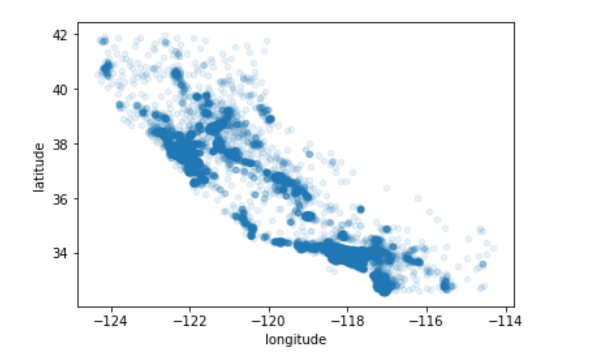
将地理数据可视化,设置alpha参数为0.1,可以清楚的看出高密度数据点的位置。
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1)
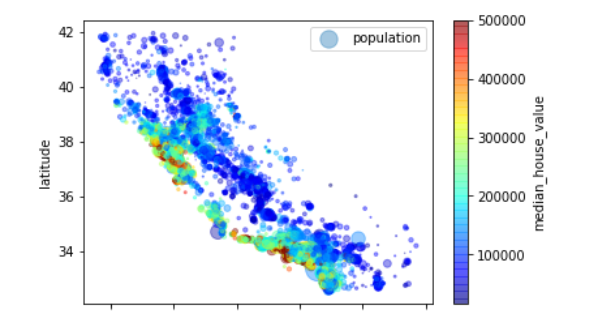
以下代码可以更清楚地可视化信息。每个圆的半径大小代表每个区的人口数量(选项s);颜色代表价格(选项c)。使用一个名为jet的预定义颜色表(选项cmap)来进行可视化,颜色范围从蓝色(价格低)到红色(价格高)。
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.4,s=housing['population']/100,
label="population",c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True) #alpha表示点的透明度
寻找属性之间的相关性
方法1:使用corr()方法计算出每对属性之间的标准相关系数(皮尔逊相关系数):
corr_mat=housing.corr()
查看每个属性与房屋价格中位数之间的相关性:
corr_mat['median_house_value'].sort_values(ascending=False)
输出:
median_house_value 1.000000 median_income 0.687160 total_rooms 0.135097 housing_median_age 0.114110 households 0.064506 total_bedrooms 0.047689 population -0.026920 longitude -0.047432 latitude -0.142724 Name: median_house_value, dtype: float64
可以看出,收入中位数与房屋价格中位数相关性最高。
注意:
1、相关系数只能刻画线性相关性(如果x上升,则y上升/下降),所以它有可能彻底遗漏非线性相关性(例如正弦曲线);
2、相关性大小和斜率大小完全无关。
方法2:使用pandas的scatter_matrix方法可视化每个数值属性相对于其他数值属性的相关性。
此例中有9个数值属性,会产生9*9=81个相关性图像,我们只关注与房屋价格中位数最相关的那些属性。
from pandas.plotting import scatter_matrix attr=['median_house_value','median_income','total_rooms','housing_median_age'] scatter_matrix(housing[attr],figsize=(12,10),color='green',alpha=0.1)
输出:
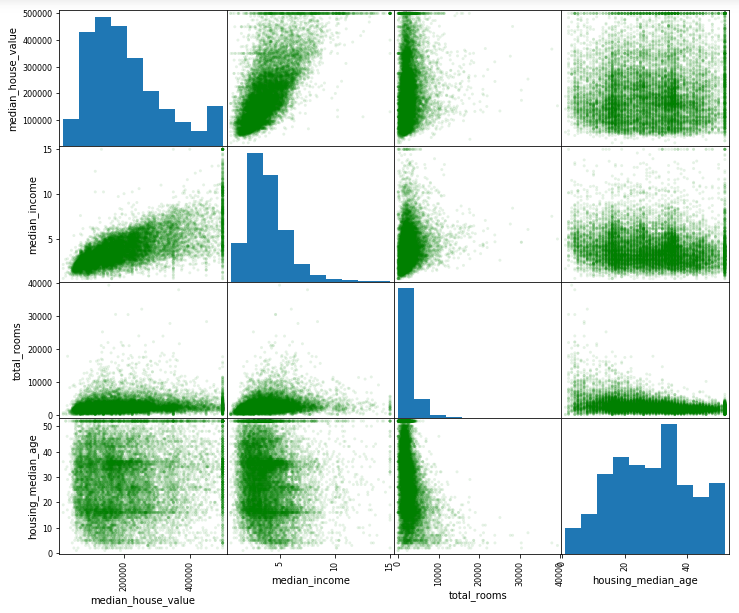
由上图可知,与房屋价格中位数最相关的是收入中位数,放大查看这两个属性的相关性:
housing.plot(kind='scatter',x='median_income',y='median_house_value',alpha=0.1)
输出: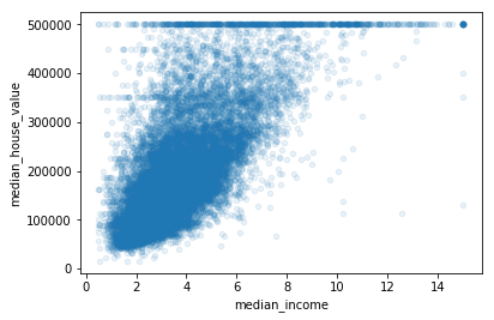
图中有50万美元、45万美元、35万美元三条直线,这些数据可能会影响算法学习效果,应该删除。
试验不同属性的组合