1 训练集ex6data1.mat可视化
绘制训练集函数plotData.m
function plotData(X, y)
% plotData(X, y)绘制数据,
% 输入参数: X 输入特性矩阵,行数为样本数,列数为2,每一行是一个二维点
% y 输出特性向量,行数为样本数,列数为1,每个元素值为0或1.
% 输出结果: 样本的输出特性向量为1的打上‘+’标记,为0的打上‘o'标记
%
% Create New Figure
figure; hold on;
% Find Indices of Positive and Negative Examples
pos = find(y == 1); neg = find(y == 0);
% Plot Examples
plot(X(pos, 1), X(pos, 2), 'k+','LineWidth', 1, 'MarkerSize', 5);
plot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y','MarkerSize', 5);
hold off;
endfunction
训练集可视化脚本LinearSVM.m第一部分代码
%% Initialization
clear ; close all; clc
%% =============== Part 1: 加载并可视化数据 ================
fprintf('Loading and Visualizing Data ...\n')
% 从文件 ex6data1.mat中加载,会发现环境中有X,y变量值:
load('ex6data1.mat');
% 绘制训练集数据
plotData(X, y);
fprintf('Program paused. Press enter to continue.\n');
pause;
执行结果
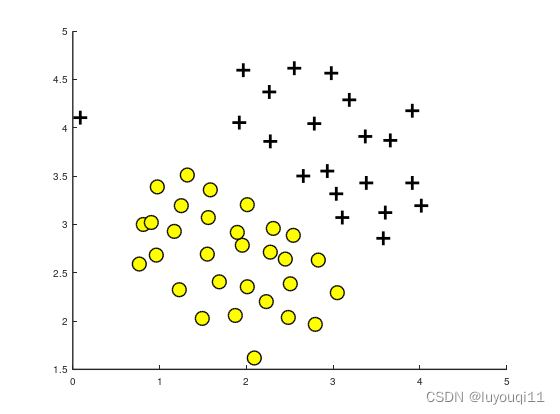
可以看到这里的数据集分两类,其中存在一个异常点(0.1,4.1),因此这个偏离点将影响SVM的决策边界。
2 SVM的线性核linearKernel.m
function sim = linearKernel(x1, x2)
% linearKernel(x1, x2)返回一个在x1和x2之间的线性核,
% 输入参数: x1,x2 列向量。确保x1和x2是维度一致的列向量
% 返 回 值: sim 列向量x1、x2的点积
%
x1 = x1(:); x2 = x2(:);
% Compute the kernel
sim = x1' * x2; % dot product
end
3 训练函数svmTrain.m
function [model] = svmTrain(X, Y, C, kernelFunction, ...
tol, max_passes)
% svmTrain使用SMO算法的简化版本训练SVM分类器。
% 输入: X 训练矩阵,行数为样本数,列数为输入特征数
% y 训练集输出特征向量,是一个包含1和0的列向量,行数为样本数,列数为1
% C 标准的SVM正则化的参数。
% kernelFunction 训练用的核函数
% tol 是一个公差值,用于确定相等浮点数。
% max_passes 控制算法退出之前对数据集的迭代次数(不改变alpha值)。
%返回值:model 训练模型
%
%注:这是用于训练支持向量机的SMO算法的简化版本。
% 在实践中,如果你想训练一个SVM分类器,我们建议使用一个优化的包,例如:
% LIBSVM (http://www.csie.ntu.edu.tw/ ~ cjlin / LIBSVM /)
% SVMLight (http://svmlight.joachims.org/)
%设置默认的tol值和max_passes
if ~exist('tol', 'var') || isempty(tol)
tol = 1e-3;
endif
if ~exist('max_passes', 'var') || isempty(max_passes)
max_passes = 5;
endif
% 训练集的参数
m = size(X, 1); % 样本数
n = size(X, 2); % 输入特征数
% 将输出特征向量中的值为0的元素替换成-1
Y(Y==0) = -1;
% 初始化训练模型中的变量
alphas = zeros(m, 1);
b = 0;
E = zeros(m, 1);
passes = 0;
eta = 0;
L = 0;
H = 0;
% 预计算内核矩阵,因为我们的数据集很小
% (在实践中,使用优化的SVM包,能优雅地处理大数据集,而不是用这个代码)
% 我们在这里实现了优化的向量化kernel版本,使svm训练运行得更快。
if strcmp(func2str(kernelFunction), 'linearKernel')
% 线性核的矢量化计算。
% 这相当于在每一对例子上计算内核
K = X*X';
elseif strfind(func2str(kernelFunction), 'gaussianKernel')
% 矢量化RBF核
% 这相当于在每一对例子上计算内核
X2 = sum(X.^2, 2);
K = bsxfun(@plus, X2, bsxfun(@plus, X2', - 2 * (X * X')));
K = kernelFunction(1, 0) .^ K;
else
% 预计算核矩阵
% 由于缺乏矢量化,下面的操作可能会很慢
K = zeros(m);
for i = 1:m
for j = i:m
K(i,j) = kernelFunction(X(i,:)', X(j,:)');
K(j,i) = K(i,j); %the matrix is symmetric
endfor
endfor
endif
% 训练
fprintf('\nTraining ...');
dots = 12;
while passes < max_passes,
num_changed_alphas = 0;
for i = 1:m,
% 使用(2)计算Ei = f(x(i)) - y(i)。.
% E(i)=b +sum (X(i, :)*(repmat(alphas.*Y,1,n).*X)')- Y(i);
E(i) = b + sum (alphas.*Y.*K(:,i)) - Y(i);
if ((Y(i)*E(i)<-tol && alphas(i)< C) || (Y(i)*E(i)>tol && alphas(i)>0)),
%在实践中,可以使用许多启发式方法来选择i和j。
% 在这个简化的代码中,我们随机选择它们。
j = ceil(m * rand());
while j == i, % Make sure i \neq j
j = ceil(m * rand());
endwhile
% 使用(2)计算Ej = f(x(j)) - y(j)。
E(j) = b + sum (alphas.*Y.*K(:,j)) - Y(j);
% 保存旧alphas
alpha_i_old = alphas(i);
alpha_j_old = alphas(j);
% 通过(10)或(11)计算L和H。
if (Y(i) == Y(j)),
L = max(0, alphas(j) + alphas(i) - C);
H = min(C, alphas(j) + alphas(i));
else
L = max(0, alphas(j) - alphas(i));
H = min(C, C + alphas(j) - alphas(i));
endif
if (L == H),
% continue to next i.
continue;
endif
% 通过(14)计算eta。
eta = 2 * K(i,j) - K(i,i) - K(j,j);
if (eta >= 0),
% continue to next i.
continue;
endif
% 使用(12)和(15)计算并剪辑alphas的新值。
alphas(j) = alphas(j) - (Y(j) * (E(i) - E(j))) / eta;
% 剪辑
alphas(j) = min (H, alphas(j));
alphas(j) = max (L, alphas(j));
% 检查alphas的变化是否显著
if (abs(alphas(j) - alpha_j_old) < tol),
% continue to next i.
% replace anyway
alphas(j) = alpha_j_old;
continue;
endif
% 使用(16)确定alpha i的值。
alphas(i) = alphas(i) + Y(i)*Y(j)*(alpha_j_old - alphas(j));
% 分别使用(17)和式(18)计算b1和b2。
b1 = b - E(i) ...
- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...
- Y(j) * (alphas(j) - alpha_j_old) * K(i,j)';
b2 = b - E(j) ...
- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...
- Y(j) * (alphas(j) - alpha_j_old) * K(j,j)';
% 用(19)计算b。
if (0 < alphas(i) && alphas(i) < C),
b = b1;
elseif (0 < alphas(j) && alphas(j) < C),
b = b2;
else
b = (b1+b2)/2;
endif
num_changed_alphas = num_changed_alphas + 1;
endif
endfor
if (num_changed_alphas == 0),
passes = passes + 1;
else
passes = 0;
endif
fprintf('.');
dots = dots + 1;
if dots > 78
dots = 0;
fprintf('\n');
endif
if exist('OCTAVE_VERSION')
fflush(stdout);
endif
endwhile
fprintf(' Done! \n\n');
% Save the model
idx = alphas > 0;
model.X= X(idx,:);
model.y= Y(idx);
model.kernelFunction = kernelFunction;
model.b= b;
model.alphas= alphas(idx);
model.w = ((alphas.*Y)'*X)';
endfunction
4 可视化线性SVM决策边界函数visualizeBoundaryLinear.m
function visualizeBoundaryLinear(X, y, model)
% visualizeBoundaryLinear绘制支持向量机学习到的线性决策边界
% 输入: X 训练矩阵,行数为样本数,列数为输入特征数
% y 训练集输出特征向量,是一个包含1和0的列向量,行数为样本数,列数为1
% model 由svmTrain函数得出的模型
w = model.w;
b = model.b;
xp = linspace(min(X(:,1)), max(X(:,1)), 100);
yp = - (w(1)*xp + b)/w(2);
plotData(X, y);
hold on;
plot(xp, yp, '-b');
hold off
endfunction
5 线性SVM脚本LinearSVM.m第二部分代码
%% ==================== Part 2: 线性SVM训练 ====================
% 下面的代码将在数据集上训练一个线性支持向量机,并绘制学习到的决策边界
% 从文件 ex6data1.mat中加载,会发现环境中有X,y变量值:
load('ex6data1.mat');
fprintf('\nTraining Linear SVM ...\n')
% 你应该尝试改变下面的C值,看看决策边界是如何变化的(例如,尝试C = 1000)
C = 1;
model = svmTrain(X, y, C, @linearKernel, 1e-3, 20);
visualizeBoundaryLinear(X, y, model);
fprintf('Program paused. Press enter to continue.\n');
pause;
load('ex6data1.mat');
fprintf('\nTraining Linear SVM ...\n')
% 你应该尝试改变下面的C值,看看决策边界是如何变化的(例如,尝试C = 1000)
C = 100;
model = svmTrain(X, y, C, @linearKernel, 1e-3, 20);
visualizeBoundaryLinear(X, y, model);
6 执行LinearSVM.m脚本结果
在这里,脚本先加载C=1时的分类情况,可以看到偏离点位于决策边界下方,效果不好(下图左边),在代码中更改C=100后,输出为下图右边。C=100相当于减小正则项系数λ,增加了代价函数中前半部分特征x的权重,因此可以看到偏离点已经在边界以上。
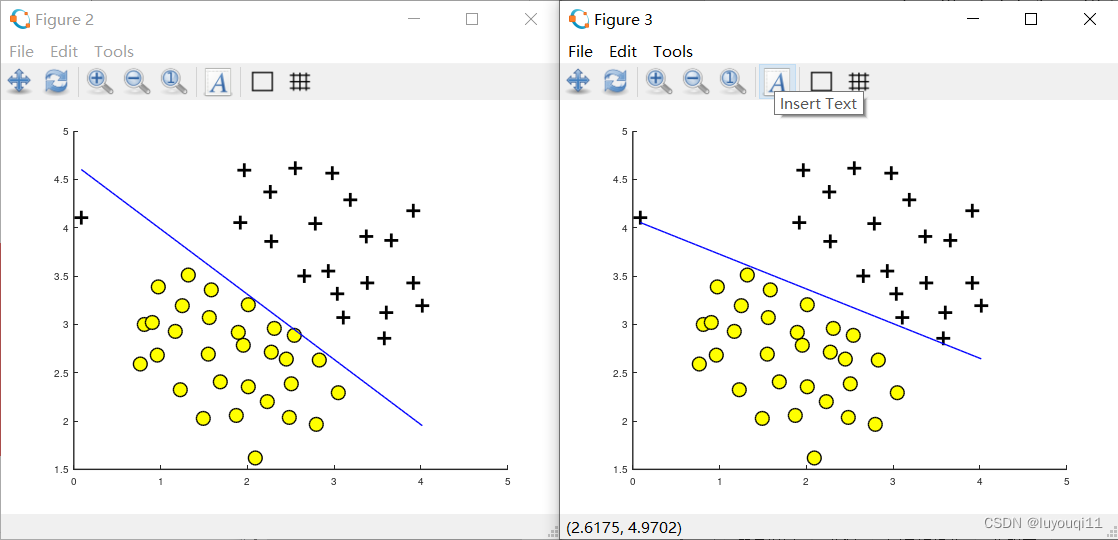
在左图中,C = 1,SVM将决策边界放到了两个数据的间隔之间,并且将左边较远位置的数据点错误的划分了。
在右图中,C = 100,SVM现在将所有样本正确的分类,但是这个决策边界并不能自然的拟合数据。