一.Logistic分类算法
逻辑回归(Logistic Regression, LR)是传统机器学习中的一种分类模型,由于算法的简单和高效,解释性好以及容易扩展等优点,被广泛应用于点击率预估(CTR)、计算广告(CA)以及推荐系统(RS)等任务中。逻辑回归虽然名字叫做回归,但实际上却是一种分类学习方法。主要用于两分类问题,利用Logistic函数(或称为Sigmoid函数),自变量取值范围为(-INF, INF),自变量的取值范围为(0,1),函数形式为:
![]()
由于sigmoid函数的定义域是(-INF, +INF),而值域为(0, 1)。因此最基本的LR分类器适合于对两分类(类0,类1)目标进行分类。Sigmoid 函数是个很漂亮的“S”形,如下图所示:
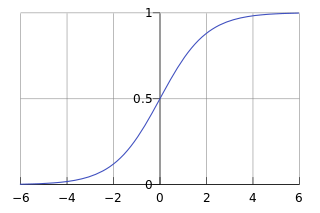
LR分类器目的就是从训练数据特征学习出一个0/1分类模型,这个模型以样本特征的线性组合![]() 作为自变量,使用logistic函数将自变量映射到(0,1)上。因此LR分类器的求解就是求解一组权值
作为自变量,使用logistic函数将自变量映射到(0,1)上。因此LR分类器的求解就是求解一组权值![]() (Θ0是是名义变量--dummy,为常数,实际工程中常另x0=1.0。不管常数项有没有意义,最好保留),并代入Logistic函数构造出一个预测函数:
(Θ0是是名义变量--dummy,为常数,实际工程中常另x0=1.0。不管常数项有没有意义,最好保留),并代入Logistic函数构造出一个预测函数:
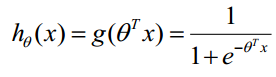
函数的值表示结果为1的概率,就是特征属于y=1的概率。因此对于输入x分类结果为类别1和类别0的概率分别为:
![]()
当我们要判别一个新来的特征属于哪个类时,按照下式求出一个z值: ![]() ,(x1,x2,...,xn是某样本数据的各个特征,维度为n)。进而求出
,(x1,x2,...,xn是某样本数据的各个特征,维度为n)。进而求出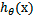 ---若大于0.5就是y=1的类,反之属于y=0类。(注意:这里依然假设统计样本是均匀分布的,所以设阈值为0.5)。LR分类器的这一组权值如何求得的呢?这就需要涉及到极大似然估计MLE和优化算法的概念了,数学中最优化算法常用的就是梯度上升(下降)算法。Logistic回归可以也可以用于多分类的,但是二分类的更为常用也更容易解释。所以实际中最常用的就是二分类的Logistic回归。LR分类器适用数据类型:数值型和标称型数据。其优点是计算代价不高,易于理解和实现;其缺点是容易欠拟合,分类精度可能不高。
---若大于0.5就是y=1的类,反之属于y=0类。(注意:这里依然假设统计样本是均匀分布的,所以设阈值为0.5)。LR分类器的这一组权值如何求得的呢?这就需要涉及到极大似然估计MLE和优化算法的概念了,数学中最优化算法常用的就是梯度上升(下降)算法。Logistic回归可以也可以用于多分类的,但是二分类的更为常用也更容易解释。所以实际中最常用的就是二分类的Logistic回归。LR分类器适用数据类型:数值型和标称型数据。其优点是计算代价不高,易于理解和实现;其缺点是容易欠拟合,分类精度可能不高。
二、梯度下降求解损失函数
逻辑回归的损失函数是根据逻辑回归本身式子中系数的最大似然估计推导而来的,最大似然估计就是通过已知结果去反推最大概率导致该结果的参数。极大似然估计是概率论在统计学中的应用,它提供了一种给定观察数据来评估模型参数的方法,即 “模型已定,参数未知”,通过若干次试验,观察其结果,利用实验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。逻辑回归是一种监督式学习,是有训练标签的,就是有已知结果的,从这个已知结果入手,去推导能获得最大概率的结果参数,只要我们得出了这个参数,那我们的模型就自然可以很准确的预测未知的数据了。
令逻辑回归的模型为![]() ,则可以将其视为类1的后验概率,所以有:
,则可以将其视为类1的后验概率,所以有:
![]()
以上两个式子,可以改写为一般形式:
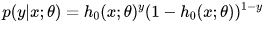
因此根据最大似然估计,可以得到:
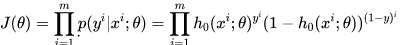
为了简化计算,取对数将得到:
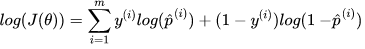
我们希望极大似然越大越好,就是说,对于给定样本数量m,希望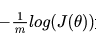 越小越好,得到逻辑回归的损失函数如下:
越小越好,得到逻辑回归的损失函数如下:
![]()
接下来需要找到一组参数,使得上面的损失函数达到最小值。这个损失函数是没有标准方程解的,因此在实际的优化中,我们往往直接使用梯度下降法来不断逼近最优解。
使用梯度下降法,就要求出梯度,对每一个向量中每一个参数,都求出对应的导数:
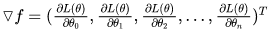
对sigmoid函数进行求导(链式求导法则):
![]()
然后对外层的log函数进行求导:
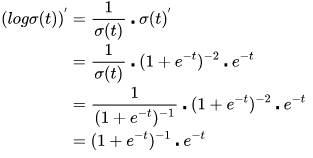
然后进行整理:
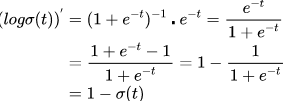
下面就可以对损失函数前半部分的表达式![]() 对Θ进行求导了。带入上面的结果,得到:
对Θ进行求导了。带入上面的结果,得到:
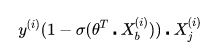
同样地,可以对损失函数的后半部分做求导,跟上面类似。最终求的损失函数L(Θ)对Θ的导数如下,即逻辑回归的损失函数经过梯度下降法对一个参数进行求导,得到结果如下:
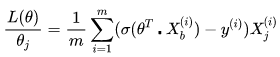
其中![]() 就是逻辑回归模型的预测值。
就是逻辑回归模型的预测值。
在求得对一个参数的导数之后,则可以对所有特征维度上对损失函数进行求导,得到向量化后的结果如下:

三.Python代码实现