介绍
在有监督学习中,主要分成了两类:回归和分类
回归:简单的说,通过给点的数字,最后预测出来一个值
eg:银行贷款是有一个贷款的区间范围的,输入的数据可以是个人的收入情况、年龄等数据;最后输出的值就是银行具体能够贷款的金额
分类:给定一些数据,最后计算出来的是划分到某一个类中间
eg:和上面的例子差不多,只是最后的结果并不是银行能够贷款的具体的金额,而是是否具备由贷款的资格
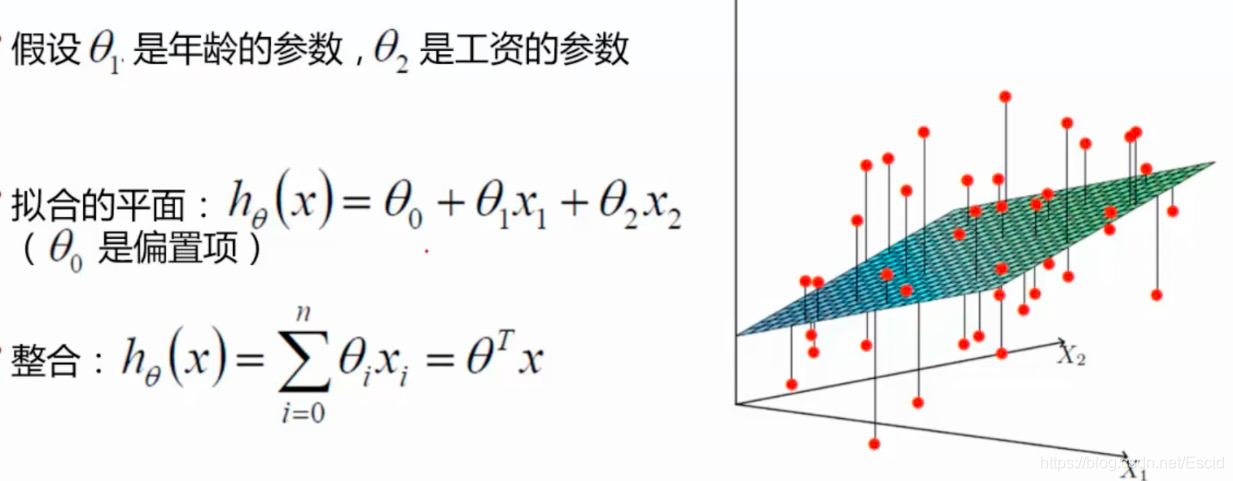
这里注意,在最后整合完成的的式子中间,采用的是矩阵的计算,在机器学习中间一般不会使用一个一个的乘的方式,使用矩阵的方式会更加的高效
误差项分析
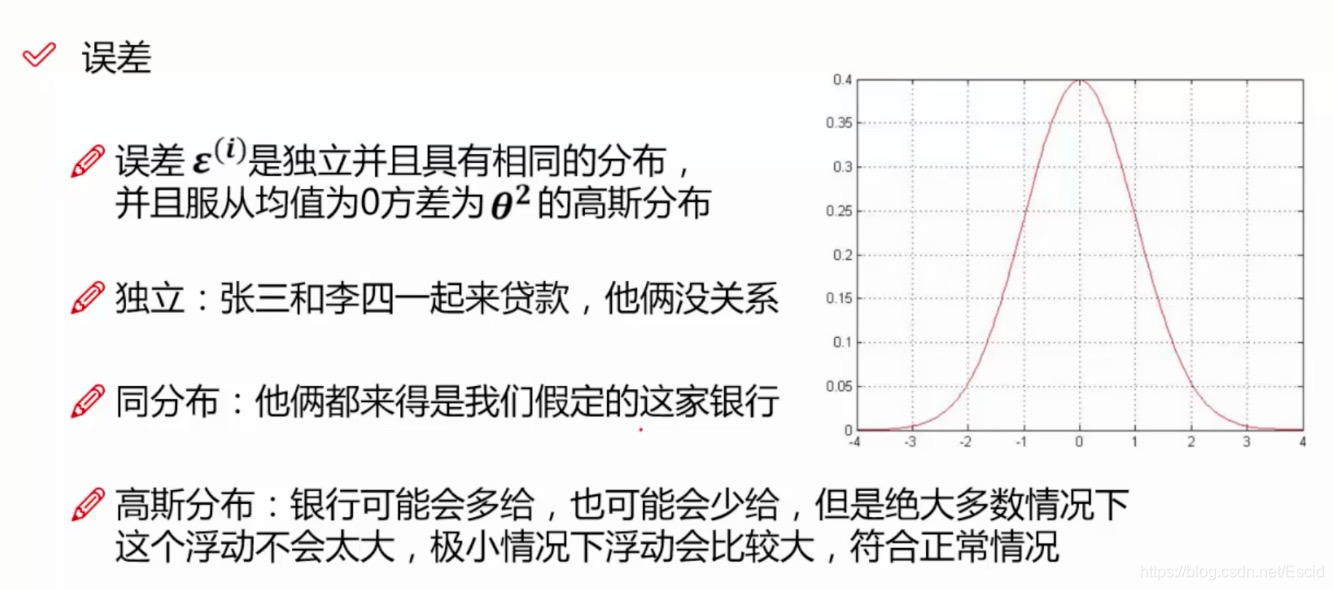
误差:真实值与预测值之间肯定是存在有差异的,使用ε来表示
下面将预测值和误差之间的关系带入到高斯分布中:
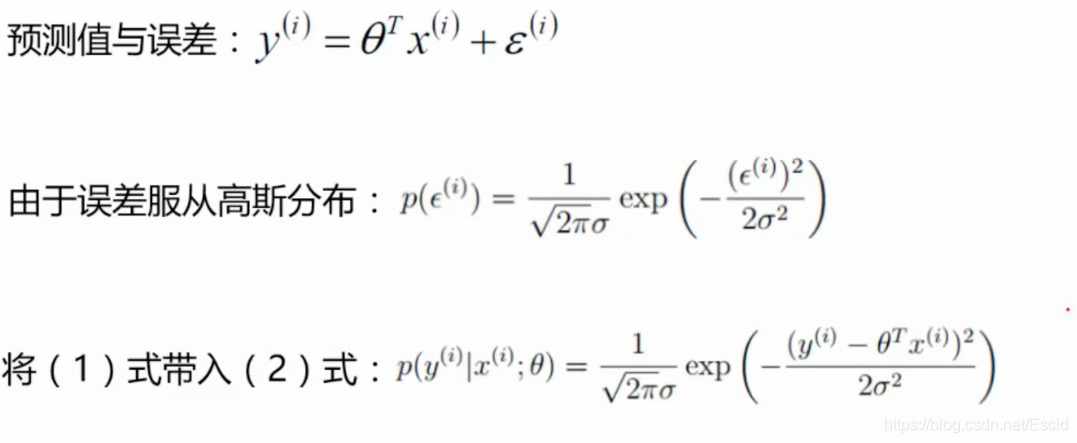

在上面讲到了似然函数,其实就是给定一堆的样本,然后预测出来一个参数,让这个参数和这些样本数据进行整合,最后得出来的值越靠近真实值

在上面化简的时候,因为需要满足一个最大似然函数,则上面式子右边应该是越小越好,而左边的内容是一个常数(对结果没有太大影响,去掉),最后得到了上图中间的最小二乘法
上面已经得到了这个最小二乘法,如果想要将这个目标函数取得最小值(预测值和真实值之间的误差越小越好)
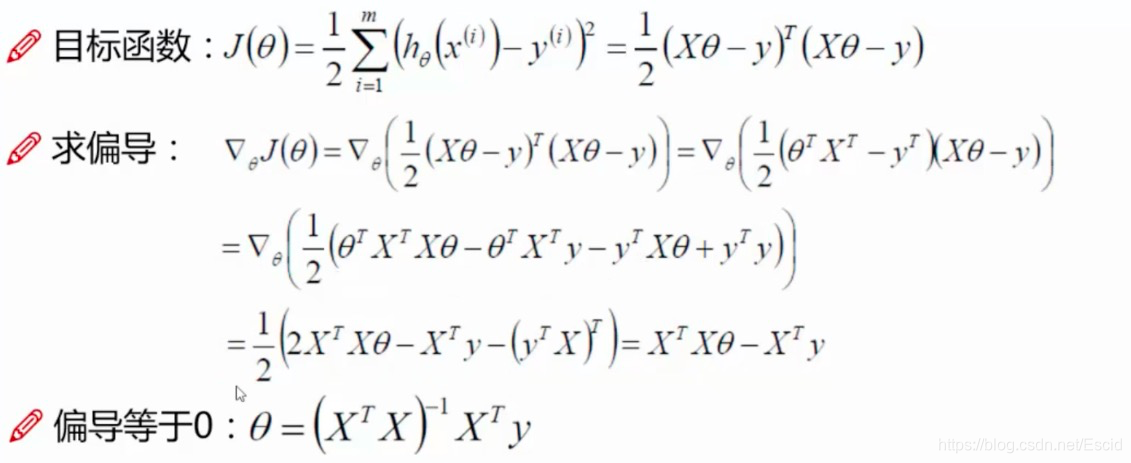
如上图,就会采用求偏导的方式,当偏导等于0的时候,就是一个极小值点,这样就能够知道取值的内容了

残差平方和:预测值和真实值之间差异
小结:R^2的值越靠近1表示越好;越靠近0表示越不好