本文介绍了逻辑回归模型的原理。逻辑回归模型参数估计。逻辑回归模型的评估。逻辑回归模型的评估。因为这门课程偏重于入门,所以对统计学方面的知识,没有进一步深挖。如果一些知识不好理解,先大体看看,留下印象。可以暂时先跳过,只记住结论。循序渐进,以后有这方面的需求再专门去学习相关知识。
文章目录
1. 逻辑回归
1.1 分类变量

注意:在分类问题中常常使用**哑变量(Dummy Coding)**来表示类别,从索引0开始编码,比如有苹果、桃子、西瓜、鸭梨4类,则将这4类编码为0,1,2,3。常用one-hot编码,则返回一个4×4表格,对应类别处为1,其余位置为0。如下图所示:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 0 | 1 |
在机器学习分类算法中,通常会使用one-hot编码将类别编码成哑变量,算法训练完成后,预测输出为类似于上表的概率表(表中的0,1换为概率),然后与设定的阈值比较,输出概率最大的分类,最后,将有实际含义的类别名称与哑变量对应起来作为输出。
1.2 因变量是分类变量

实例:


求解残差的期望:
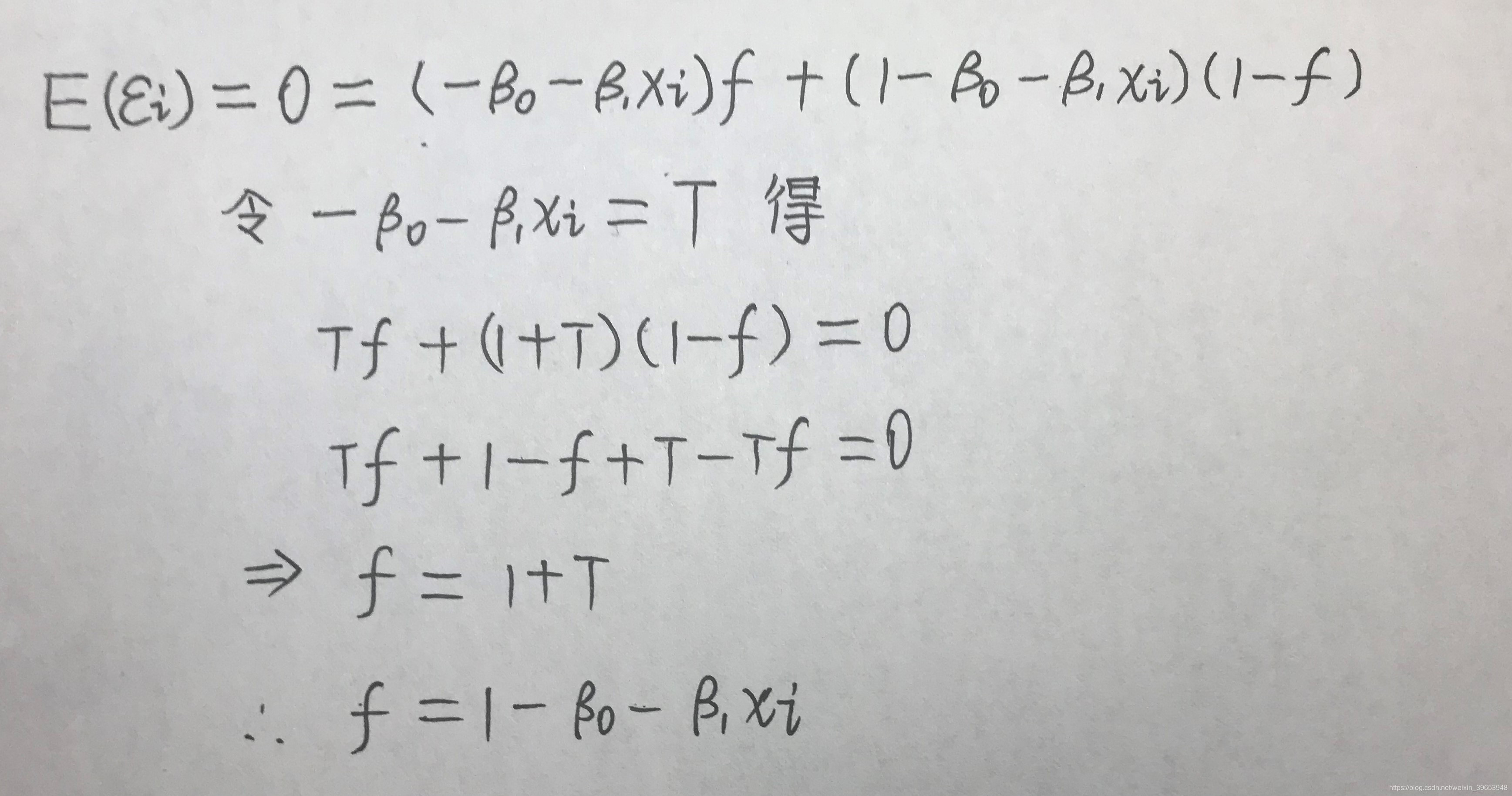
1.3 因变量是分类变量带来的影响

通过以上的概率模型就表达了因变量是分类变量时,线性模型的拟合情况。
2. Logistic(Sigmoid) 函数

使用matplotlib绘图,单极性Sigmoid函数:

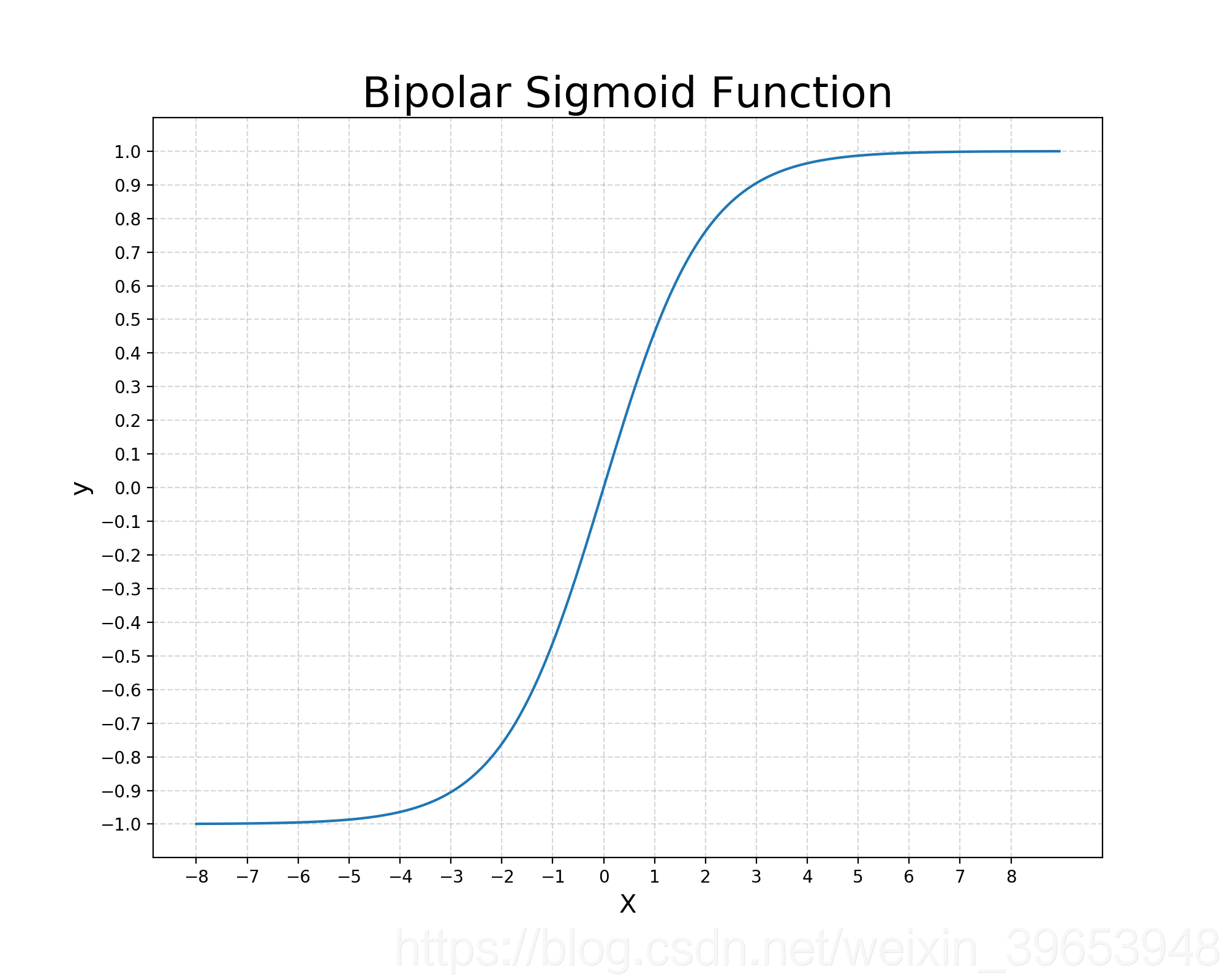
双极性Sigmoid函数:
2.1 Logistic函数由来

2.2 Logistic回归
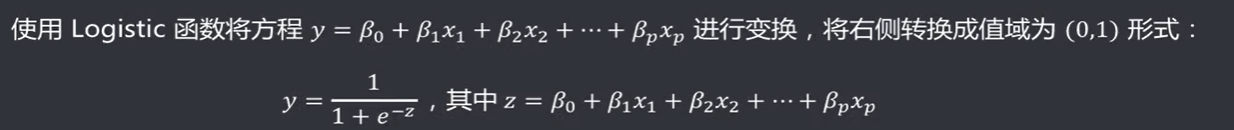
使用Logistic函数
将离散的因变量进行变换,转化为概率形式 ,保证输出是连续值,其中Logistic函数中的
表示原来的因变量。

原来的因变量(分类变量)取值
是离散的值,不满足回归的基本条件假设(回归假设要求输入输出变量是连续值),因此要想使用回归模型,需要对离散变量进行变换,将离散值变为连续值。变换过程中,要求自变量
可以任意取值,因变量
限制在[0,1]范围内并且没有断点(连续)。经过研究找到了
变换,可以满足上述要求,从而满足了回归的基本条件假设。因此,通过Logistic函数变换将离散的因变量(分类变量)取值
变为连续区间[0,1]内的概率取值。
3. 参数估计
3.1 回顾:最大似然估计(MLE)

最大似然估计解决的是“模型已定,参数未知”的问题。即用已知样本的结果,去反推既定模型中的参数最可能的取值。

最大似然估计,“似然”用现代的中文来说即“可能性”。故而,若称之为“最大可能性估计”则更加通俗易懂。就是在某一事件已经发生的情况下,去构造一个概率模型(似然函数,含
个样本值
以及分布参数
)表征这事件发生的可能性,然后通过样本值去求解分布参数如何取值时,才能使得似然函数最大(事件发生的可能性最大),根据这一点去求解分布参数。那么,此时求出的参数是符合使得事件发生概率最大的参数。
最大似然估计的步骤:

3.2 最大似然估计法估计参数值


3.3 迭代法:梯度与梯度法

3.3.1 梯度上升(下降)法



:每次变化的步长,也称学习率( Learning rate)。
循环终止条件经常设置两种,设置阈值和循环次数。保证到达最优,并且在某一局部震荡时停止训练。
3.3.2 常见的梯度上升(下降)法

相应地,有梯度下降算法。
随机梯度上升(下降)算法每次只用一个样本,小批量梯度上升(下降)算法每次使用一个小批次样本。
3.3.3 梯度算法流程

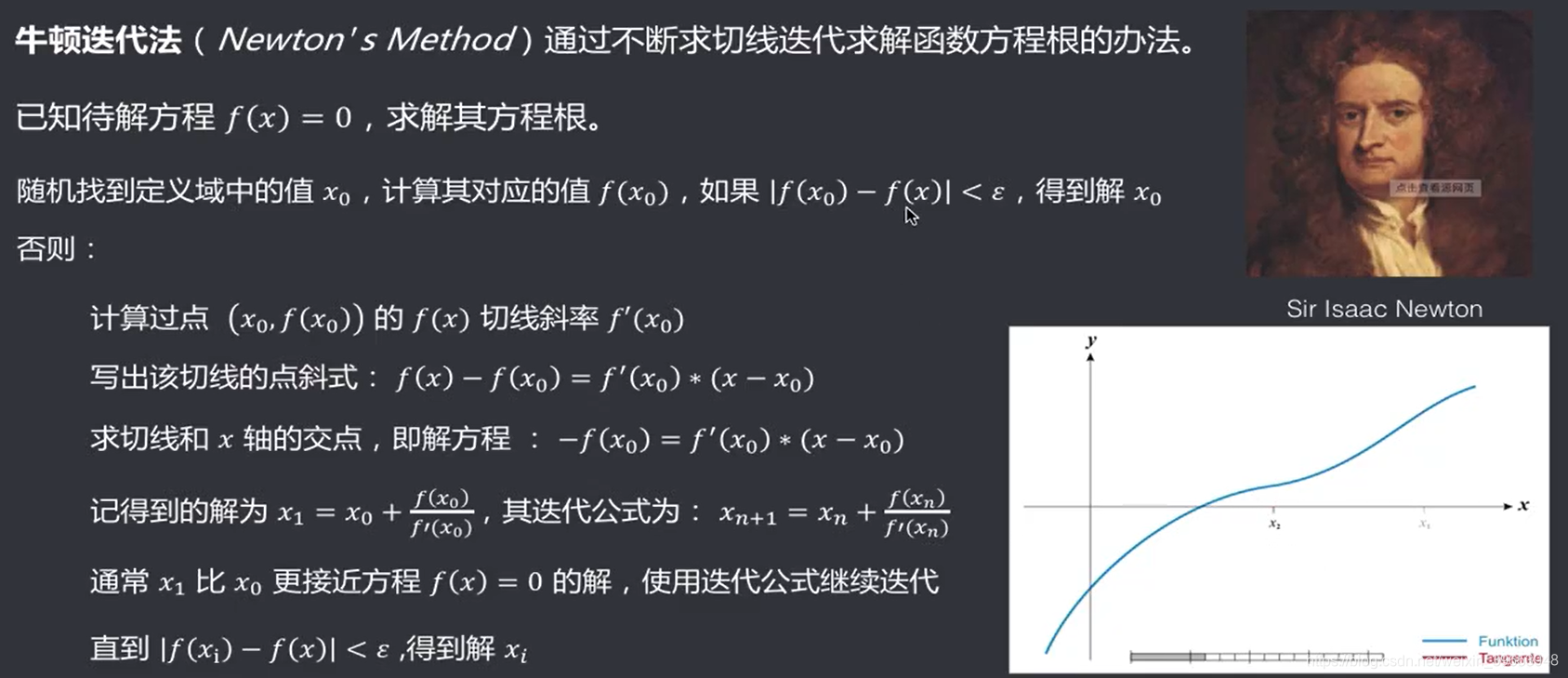
3.4 迭代法:牛顿迭代法
牛顿法是通过不断求切线迭代求解函数方程根的办法。
4. 逻辑回归案例:鸢尾花数据集
4.1 逻辑回归的基本假设

4.2 二分类逻辑回归

由数据集,建立一个可以识别山鸢尾(0)和杂色鸢尾(1)的模型。接下来转换为逻辑回归问题:

由数据集可知由四个自变量(萼长、萼宽、瓣长、瓣宽),再加一个偏差项,所以有五个参数
。
表示类别(该实例中只有两类,因此取值为0或1)。初始化权重(参数)为1,1,1,1,1;学习率
,最大循环次数MaxLoops =10000,当前循环次数currLoop = 1。接下来进行第一次循环:

计算梯度,并更新参数
:

进行第二次循环

再次计算梯度,并更新参数
:

重复以上步骤最大循环次数次,然后退出循环。最终循环终止时的参数为:
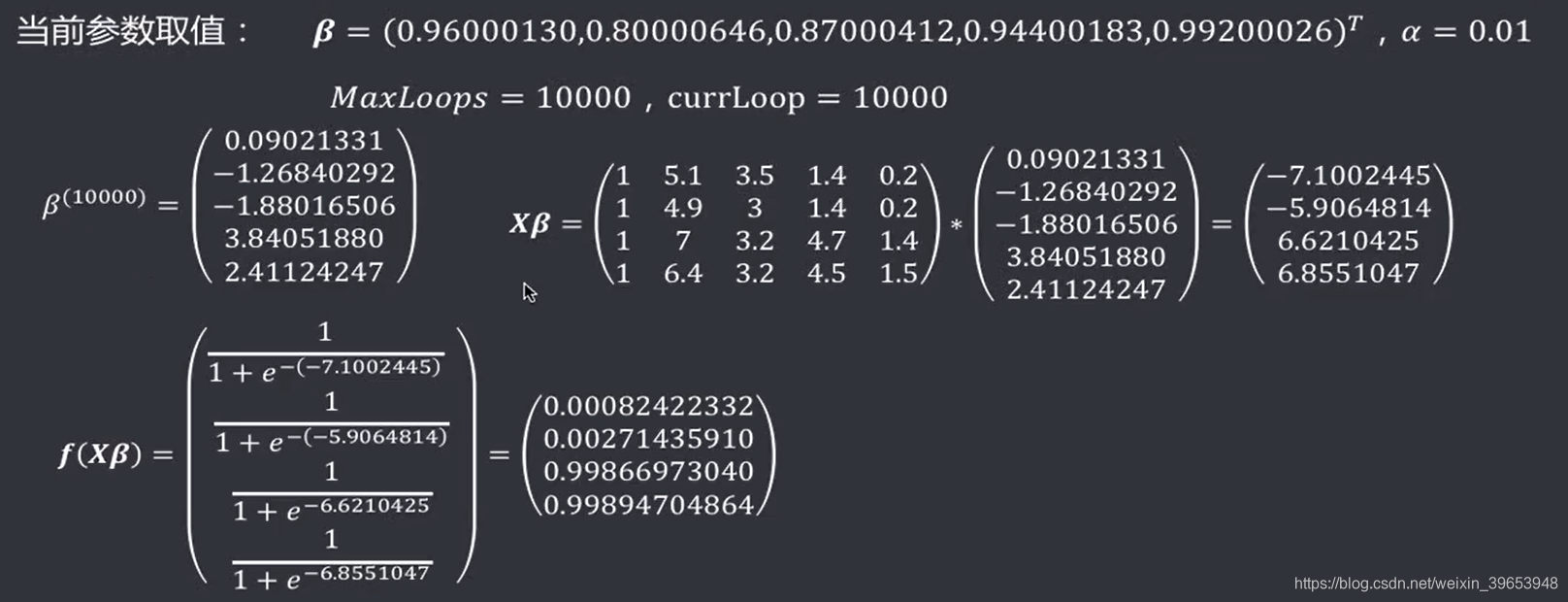
使用训练好的参数做预测,例如:

4.3 多分类逻辑回归
4.3.1 构建多个二分类逻辑回归模型

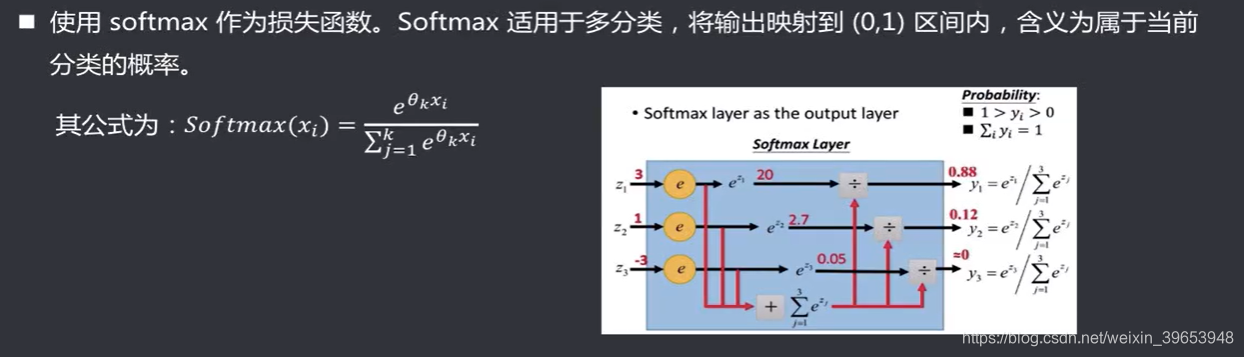
4.3.2 softmax作为损失函数
5. 模型的评估、诊断与调优
5.1 回归系数的假设方案

5.2 回归系数的假设检验

5.3 拟合优度

5.4 常见的分类模型评估方法

在分类问题的论文中,常用混淆矩阵、准确率、查准率、查全率、F-Score进行评估。
5.5 自变量筛选

5.6 其他常见问题

总结
课程纲要

-
逻辑回归模型的原理
逻辑回归实际上是线性回归模型的延展,属于广义线性回归模型(GLM),逻辑回归预测的因变量不再是连续的值,而是离散的值(0或1)。逻辑回归,将离散的因变量(二分类0或1)转化成了连续的概率分布,变换之后因变量的输入是任意值,此时满足了线性回归的假设,可以应用线性回归的相关知识。为了计算方便,选用了Logistic函数,求导之后是原函数的函数,大大简化的运算过程。 -
逻辑回归模型参数估计
因为预测的因变量取值是一个二分类的值,不满足正态分布,只满足二项分布。此时,不能使用最小二乘法进行估计,只能使用最大似然估计法进行估计(MLE)。构造似然函数,然后求参数的值。
- 梯度上升(梯度下降):使用全部样本计算梯度,计算的参数准确但是计算的比较慢
- 随机梯度下降:一次取一个样本计算梯度,计算的速度快,但是计算的参数误差比较大
- 小批量梯度下降:一种折中的方法,随机取一个小批次计算梯度,更新参数。常用!
-
逻辑回归模型的评估
常见的评估方法:准确率、查准率、查全率、ROC曲线、混淆矩阵、F-Score等。 -
逻辑回归模型的优化
建模时,一定要有模型评估与优化的概念。通过一些手段,使模型符合回归的基本假设。
学习目标

思考与练习

课程链接:https://edu.aliyun.com/roadmap/ai?spm=5176.13944111.1409070.1.61cc28fcAV0KvR
