朴素贝叶斯
朴素贝叶斯和其他绝大多数的分类算法都不同。对于大多数的分类算法,比如决策树,KNN,逻辑回归,支持向量机等,他们都是判别方法,也就是直接学习出特征输出Y和特征X之间的关系,要么是决策函数Y=f(X),要么是条件分布P(Y|X)。但是朴素贝叶斯却是生成方法,也就是直接找出特征输出Y和特征X的联合分布P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)得出。
贝叶斯公式:
P(A|B) = P(A,B) / P(B) ---------条件概率:在事件B发生的前提下,A发生的概率
P(B|A) = P(A,B) / P(A)
所以:P(A,B) = P(A|B)P(B) = P(B|A)P(A)
所以贝叶斯公式:P(A|B) = (P(B|A)P(A)) / P(B) = P(A) * (P(B|A) / P(B))
这里:P(A) 为先验概率,即在B事件之前,对A事件概率的一个判断;P(A|B) 为后验概率,即B事件发生后,对事件A概率的重新评估;(P(B|A) / P(B)) 为可能性函数,这是一个调整因子,使得预估概率跟接近真实概率
最后可以将贝叶斯公式总结为:后验概率 = 先验概率 * 调整因子
公式可以理解为:P(A|B) = (P(B|A)P(A)) / P(B) ==> P(A|b1,b2,b3…) = (P(b1,b2,b3…|A)P(A)) / P(b1,b2,b3…)
即:在出现特征b1,b2,b3…的条件下,A事件发生的概率
当b1,b2,b3…事件相互独立的前提下:P(b1,b2,b3…|A) = P(b1|A)P(b2|A)P(b3|A)…
贝叶斯公式的参数估计
在计算后验概率的时,我们只需要计算分子的那两项即可,因为分母都是一样的。
-
1、对于P(A = Ck),比较简单,通过极大似然估计我们很容易得到P(A = Ck)为样本类别Ck出现的频率,即样本类别Ck出现的次数mk除以样本总数m。
-
2、P(bi|A = Ck),这取决于我们的先验条件:
-
a) 如果我们的bi是离散的值,那么我们可以假设bi符合多项式分布,这样得到 P(bi|A = Ck) 是在样本类别Ck中,特征bi出现的频率。即:
P(bi|A = Ck) = m_ki/M_k
其中M_k为样本类别Ck总的特征计数,而m_ki为类别为Ck的样本中,第i维特征bi出现的计数。
某些时候,可能某些类别在样本中没有出现,这样可能导致P(bi|A = Ck)为0,这样会影响后验的估计,为了解决这种情况,我们引入了拉普拉斯平滑,即此时有:
P(bi|A = Ck) = (m_ki+λ) / (M_k+Ojλ)
其中λ为一个大于0的常数,常常取为1。Oj为第j个特征的取值个数。
-
b) 如果我们我们的bi是非常稀疏的离散值,即各个特征出现概率很低,这时我们可以假设bi符合伯努利分布,即特征bi出现记为1,不出现记为0。即只要bi出现即可,我们不关注bi的次数。这样得到P(bi|A = Ck) 是在样本类别Ck中,bi出现的频率。此时有:
P(bi|A = Ck) = P(bi|A = Ck)bi + (1−P(bi|A = Ck))(1−bi)
其中,bi取值为0和1。
-
c)如果我们我们的bi是连续值,我们通常取bi的先验概率为正态分布,即在样本类别Ck中,bi的值符合正态分布。这样P(bi|A = Ck)的概率分布是:
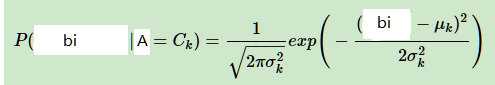
其中μk和σ2k是正态分布的期望和方差,可以通过极大似然估计求得。μk为在样本类别Ck中,所有bi的平均值。σ2k为在样本类别Ck中,所有bi的方差。对于一个连续的样本值,带入正态分布的公式,就可以求出概率分布了。
下面举个数值的例子

拉普拉斯平滑
问题:从上面的例子我们得到娱乐概率为0,这是不合理的,如果词频列表里面有很多出现次数都为0,很可能计算结果都为零

朴素贝叶斯分类优缺点
- 优点:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快
- 缺点:
- 需要知道先验概率P(b1,b2,…|A),因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
- 由于使用了样本属性独立性的假设,所以如果样本属性有关联时,其效果不好
在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。
分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
这三个类适用的分类场景各不相同,一般来说,如果样本特征的分布大部分是连续值,使用GaussianNB会比较好。如果如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适。而如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
sklearn朴素贝叶斯实现API
- sklearn.naive_bayes.MultinomialNB
MultinomialNB
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0) 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
# 朴素贝叶斯进行文本分类
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
news = fetch_20newsgroups()
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.2)
tf = TfidfVectorizer()
# 对数据集进行特征抽取
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test) # 按照x_train的特征进行转换
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
mlt.fit(x_train, y_train)
print(mlt.predict(x_test))
print(mlt.score(x_test, y_test))
[ 9 2 16 ... 11 11 14]
0.8440123729562528