版权声明:点个赞,来个评论(夸我),随便转~ https://blog.csdn.net/qq_28827635/article/details/84481227
一、朴素贝叶斯算法
-
什么是朴素贝叶斯分类方法
属于哪个类别概率大,就判断属于哪个类别
-
概率基础
- 概率定义为一件事情发生的可能性
- P(X) : 取值在[0, 1]
- 联合概率、条件概率与相互独立
- 联合概率:包含多个条件,且所有条件同时成立的概率
- 记作:P(A,B)
- 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
- 记作:P(A|B)
- 相互独立:如果P(A, B) = P(A)P(B),则称事件A与事件B相互独立。
- 联合概率:包含多个条件,且所有条件同时成立的概率
二、朴素贝叶斯公式
朴素贝叶斯:特征之间是相互独立的。
因此当 W 不存在时,可使用相互独立将 W 进行拆分
三、简单案例:
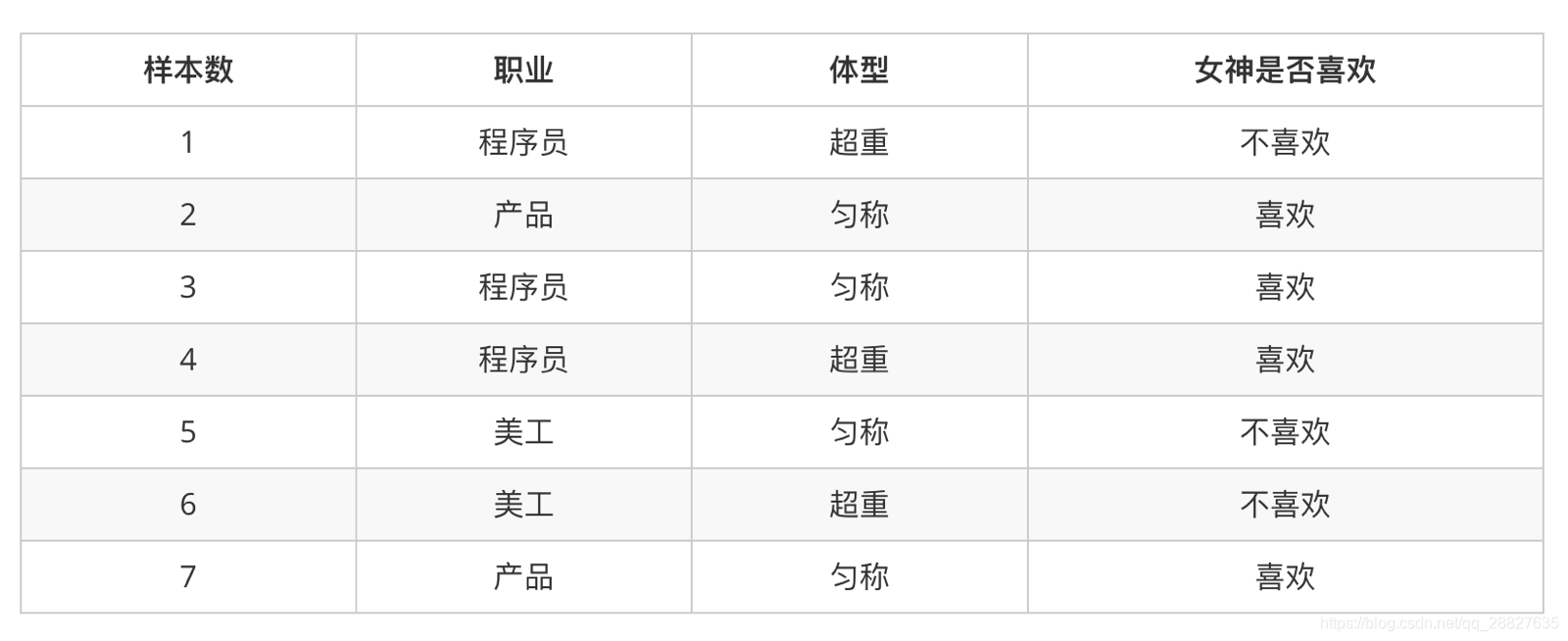
-
计算下面概率
- P(喜欢|产品, 超重) = ?
-
套用公式可得
-
分析
- 上式中,P(产品, 超重|喜欢) 和 P(产品, 超重) 的结果均为0,导致无法计算结果。
- 这是因为我们的样本量太少了,不具有代表性,本来现实生活中,肯定是存在职业是产品经理并且体重超重的人的,P(产品, 超重)不可能为0;而且事件“职业是产品经理”和事件“体重超重”通常被认为是相互独立的事件,
- 但是,根据我们有限的7个样本计算“P(产品, 超重) = P(产品)P(超重)”不成立。
- 而朴素贝叶斯可以帮助我们解决这个问题。
- 朴素贝叶斯,简单理解,就是假定了特征与特征之间相互独立的贝叶斯公式。
- 也就是说,朴素贝叶斯,之所以朴素,就在于假定了特征与特征相互独立。
- 所以,如果按照朴素贝叶斯的思路来解决,就可以是:
四、多个特征的朴素贝叶斯
1. 公式
C 可以是不同类别
2. 公式分为三个部分:
- P©:每个文档类别的概率(某文档类别数/总文档数量)
- P(W│C):给定类别下特征(被预测文档中出现的词)的概率
- 计算方法:P(F1│C)=Ni/N (训练文档中去计算)
- Ni 为该F1词在C类别所有文档中出现的次数
- N为所属类别C下的文档所有词出现的次数和
- 计算方法:P(F1│C)=Ni/N (训练文档中去计算)
- P(F1,F2,…) 预测文档中每个词的概率
如果计算两个类别概率比较:
所以我们只要比较前面的大小就可以,得出谁的概率大
四、案例-朴素贝叶斯-文章分类
-
数据
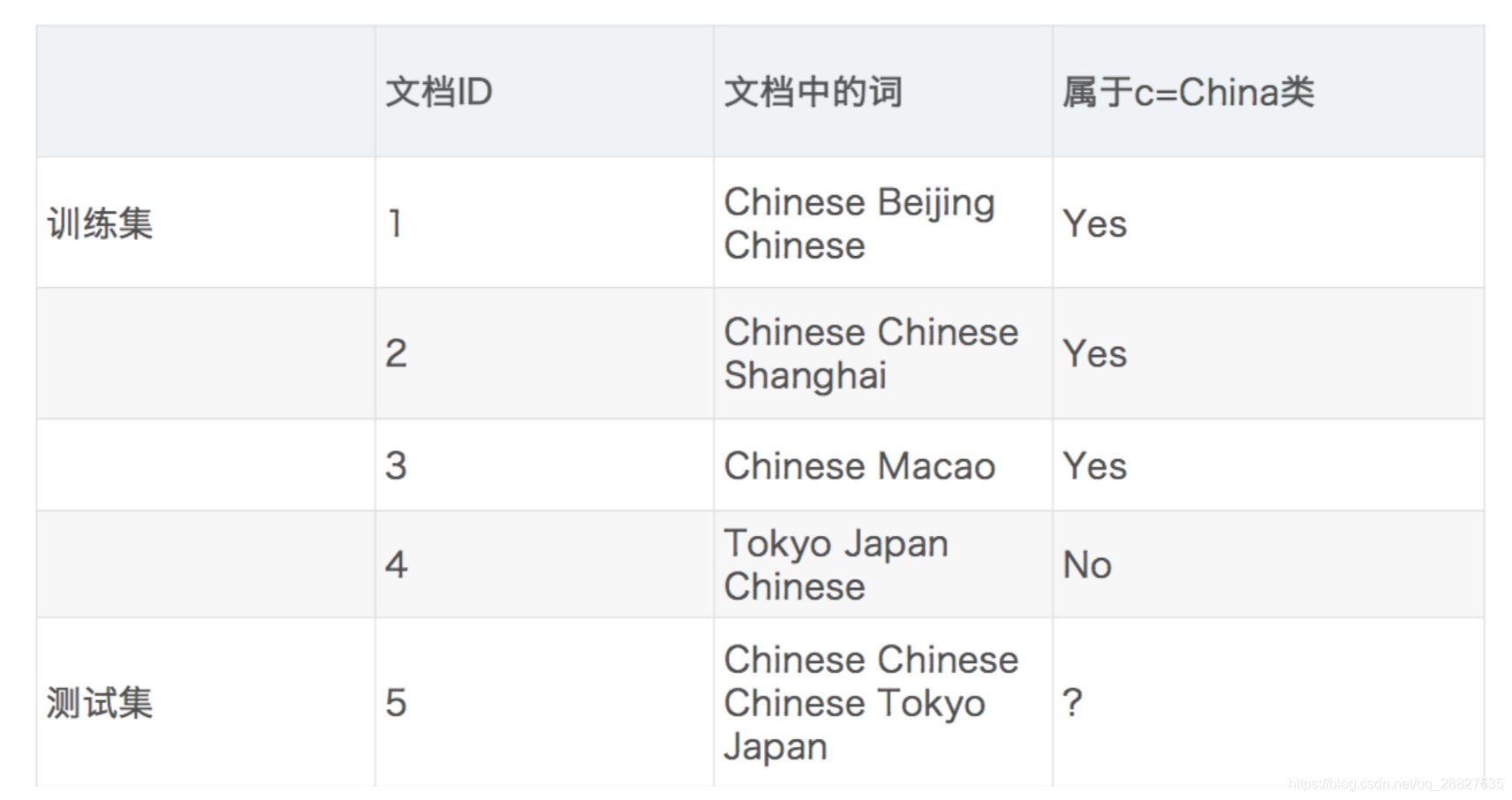
-
分别计算属于两个类的概率
-
计算过程
P(C|Chinese, Chinese, Chinese, Tokyo, Japan) = P(Chinese, Chinese, Chinese, Tokyo, Japan|C) * P(C) = P(Chinese|C)^3 * P(Tokyo|C) * P(Japan|C) * P(C) = 5/8 * 0 * 0 P(notC|Chinese, Chinese, Chinese, Tokyo, Japan) = P(Chinese, Chinese, Chinese, Tokyo, Japan|notC) * P(notC) = P(Chinese|notC)^3 * P(Tokyo|notC) * P(Japan|notC) * P(notC) = 1/9 * 1/3 * 1/3但是我们发现 P(Tokyo|C) 和 P(Japan|C) 都为 0,这是不合理的,如果词频列表里面有很多出现次数都为 0,很可能计算结果都为 0。
我们能够使用拉普拉斯平滑系数解决此问题。
-
拉普拉斯平滑系数
Ni 为该F1词在C类别所有文档中出现的次数。
N为所属类别C下的文档所有词出现的次数和。
为指定的系数,一般为1。
m 为训练集中有多少个特征词种类,如在此案例中 m = 6 。
五、sklearn 朴素贝叶斯 API
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha
- 拉普拉斯平滑系数
六、案例-朴素贝叶斯-20类新闻分类

-
步骤分析
- 进行数据集的分割
- TFIDF进行的特征抽取
- 将文章字符串进行单词抽取
- 朴素贝叶斯预测
-
完整代码
-
这里的转换器不能对测试集进行 fit 操作,因为 tfidf 转换器对于不同的文章来说提取的特征值不同,提取的特征不同,训练出的模型就不同
from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB # 获取数据 news = fetch_20newsgroups() # 划分数据集 x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.3) # 特征抽取 Tfidf # 实例化一个转换器 transfer = TfidfVectorizer() x_train = transfer.fit_transform(x_train) # 必须使用transfrom因为要让测试数据和训练数据的特征值是一样的。 x_test = transfer.transform(x_test) # 模型训练 # 实例化一个估计器 estimator = MultinomialNB() estimator.fit(x_train, y_train) # 模型评估 # 方法一:比较真实值与预测值 y_predict = estimator.predict(x_test) print('预测值为:\n', y_predict) print('比较真实值与预测值结果为:\n', y_predict==y_test) # 方法二:计算模型准确率 print('模型准确率为:\n', estimator.score(x_test, y_test)) -
七、朴素贝叶斯优缺点
- 优点:
- 思想简单、直观
- 有稳定的分类效率,准确度高,速度快
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 缺点:
- 由于假设了特征之间相互独立性,但是往往特征之间会有所关联,所以如果特征之间有相关性,效果不会太好。