import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import preprocessing
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.feature_selection import SelectFromModel
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.metrics import mean_squared_error,r2_score
data = datasets.load_boston()
x,y = data.data,data.target
nx = preprocessing.StandardScaler().fit_transform(x)
x_train,x_test,y_train,y_test = train_test_split(nx,y,test_size=0.2,random_state=1)
clf = DecisionTreeRegressor(criterion='mse',max_depth=4)
clf.fit(x_train,y_train)
predict_train = clf.predict(x_train)
predict_test = clf.predict(x_test)
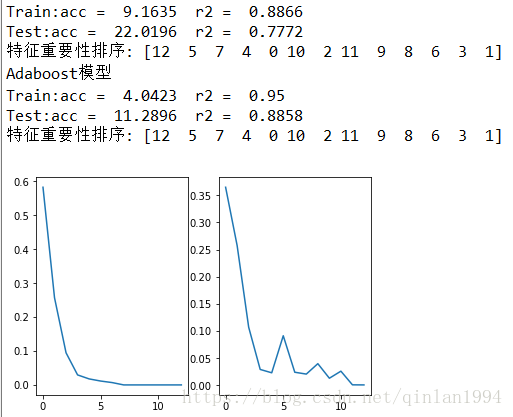
print('决策树模型')
acc,r2 = round(mean_squared_error(y_train,predict_train),4),round(r2_score(y_train,predict_train),4)
print('Train:acc = ',acc,' r2 = ',r2)
acc,r2 = round(mean_squared_error(y_test,predict_test),4),round(r2_score(y_test,predict_test),4)
print('Test:acc = ',acc,' r2 = ',r2)
index = np.flipud(np.argsort(clf.feature_importances_))
score = clf.feature_importances_[index]
print('特征重要性排序:',index)
fig,ax = plt.subplots(1,2)
ax[0].plot(score)
model = AdaBoostRegressor(DecisionTreeRegressor(criterion='mse',max_depth=4),n_estimators=500,random_state=1)
model.fit(x_train,y_train)
predict_train = model.predict(x_train)
predict_test = model.predict(x_test)
print('Adaboost模型')
acc,r2 = round(mean_squared_error(y_train,predict_train),4),round(r2_score(y_train,predict_train),4)
print('Train:acc = ',acc,' r2 = ',r2)
acc,r2 = round(mean_squared_error(y_test,predict_test),4),round(r2_score(y_test,predict_test),4)
print('Test:acc = ',acc,' r2 = ',r2)
score = model.feature_importances_[index]
print('特征重要性排序:',index)
ax[1].plot(score)