注:在读本文之前建议读一下之前的一片文章python_sklearn机器学习算法系列之PCA(主成分分析)------人脸识别(k-NearestNeighbor,KNN)
本文主要目的是通过一个简单的小例子和很短的代码来快速学习python 中的sklearn.ensemble的 AdaBoost这一模块的基本操作和使用,注意不是用python纯粹从头到尾自己构建AdaBoost,既然sklearn提供了现成的我们直接拿来用就可以了,当然其原理十分重要,下面做简单介绍:
其实说到AdaBoost就不得不提到bagging,那么它究竟是什么东东呢?它是一种自举汇聚发,比如现在有一个数据集M,我们每次从中有放回的抽取S个样本生成一个新的数据集合(注意这个集合里面可能包括多个重复的样本,也有可能不包括原数据集中有的样本),那么我们重复K次这样的操作就形成K个数据集对吧即N1,N2,N3……NK。每个数据集里面有S个样本,接下来将某个学习算法分别作用于每个数据集就得到S个分类(回归)器,当我们要对新数据进行分类(回归)时,就可以应用这S个分类(回归)器进行作业,与此同时,选择分类器中投票结果最多的类别作为最后分类结果(对于回归问题则采用S个结果的均值作为结果)(随机森林就是一种高级的bagging)。
注意AdaBoost在分类和回归问题中都可以应运,原理大体相同,下面就都以分类来介绍。
那么什么是boosting呢?它和bagging十分相似,但在其基础上增加了一些权值,即在下一次训练的时候会根据上一次训练结果改变样本的权值,即上一次分对的样本的权重会降低,相反则权重增加。另外它还对每个分类器分配了一个权重值alpha,这些alpha值是根据每个弱分类器(就是那些基本的分类器)的错误率进行计算的。
总之一句话通过引入这些权重来进一步减低错误率,而本文AdaBoost全称是adaptive boosting(自适应boosting)属于boosting的一种,说到这里就要注意一下使用AdaBoost组合的弱分类器必须支持权重计算,小编当时就犯了这个低级错误,为了方便直接用了我上篇文章python_sklearn机器学习算法系列之PCA(主成分分析)------人脸识别(k-NearestNeighbor,KNN),而这篇文章中的弱分类器KNN并不支持权重计算,下面是我第一次运行结果可以看到相关的错误提示:

所以我们下面程序使用决策树这个弱分类,好了这些概念和它们之间的关系我们屡清后,我们看看python 中的sklearn.ensemble的 AdaBoost
它包含两个函数AdaBoostClassifier和AdaBoostRegresso顾名思义分别解决分类和回归问题接下来我们分别介绍
对于AdaBoostClassifier()有几个比较重要的参数:(1) base_estimator就是指定我们要用的弱分类器,(2) algorithm是我们的AdaBoostClassifier选用什么算法,具体的有AMME和SAMME.R两者的主要区别就是后者使用概率作为我们上面介绍的权重,所以如果我们这里选用了SAMME.R算法那么base_estimator也要选有概率预测的弱分类器就是有没有predict_proba这一函数(3)n_estimators就是迭代的次数(4)learning_rate每个弱学习器的权重缩减系数
注意AdaBoostClassifier调参主要就是n_estimators和learning_rate,理论上两者越大越好,但不是绝对要联合调参
对于AdaBoostRegresso (1) base_estimator同上,(2)loss有是三个选项linear、square、exponential三种选择说白了就是对样本的误差处理对应为线性,平方和指数,默认为linear(3)n_estimators同上(4)learning_rate同上
到此知识性的东西差不多讲解完了,接下来就让我们实践一下吧,再次说明:希望先看上一篇文章再来看下面的代码比较容易些,也对后面的对比有比较快的认识。
#PCA
import warnings
from sklearn import tree
from sklearn import metrics
from sklearn.cross_validation import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.ensemble import AdaBoostClassifier
#忽略一些版本不兼容等警告
warnings.filterwarnings("ignore")
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
x=lfw_people.data
n_features=x.shape[1]
y=lfw_people.target
target_names=lfw_people.target_names
#分割训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.6)
#先训练PCA模型
PCA=PCA(n_components=100).fit(x_train)
#返回测试集和训练集降维后的数据集
x_train_pca = PCA.transform(x_train)
x_test_pca = PCA.transform(x_test)
#决策树核心代码
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(x_train_pca, y_train)
#声明使用AdaBoostClassifier
Ada1 = AdaBoostClassifier(tree.DecisionTreeClassifier(criterion='entropy'),
n_estimators=100,algorithm="SAMME", learning_rate=0.2)
Ada1.fit(x_train_pca,y_train) #训练
Ada2 = AdaBoostClassifier(tree.DecisionTreeClassifier(criterion='entropy'),
n_estimators=300,algorithm="SAMME",learning_rate=0.2)
Ada2.fit(x_train_pca,y_train)
#识别测试集中的人脸
y_test_predict1=clf.predict(x_test_pca)
y_test_predict2=Ada1.predict(x_test_pca)
y_test_predict3=Ada2.predict(x_test_pca)
'''
#输出
for i in range(len(y_test_predict)):
print(target_names[y_test_predict[i]])
'''
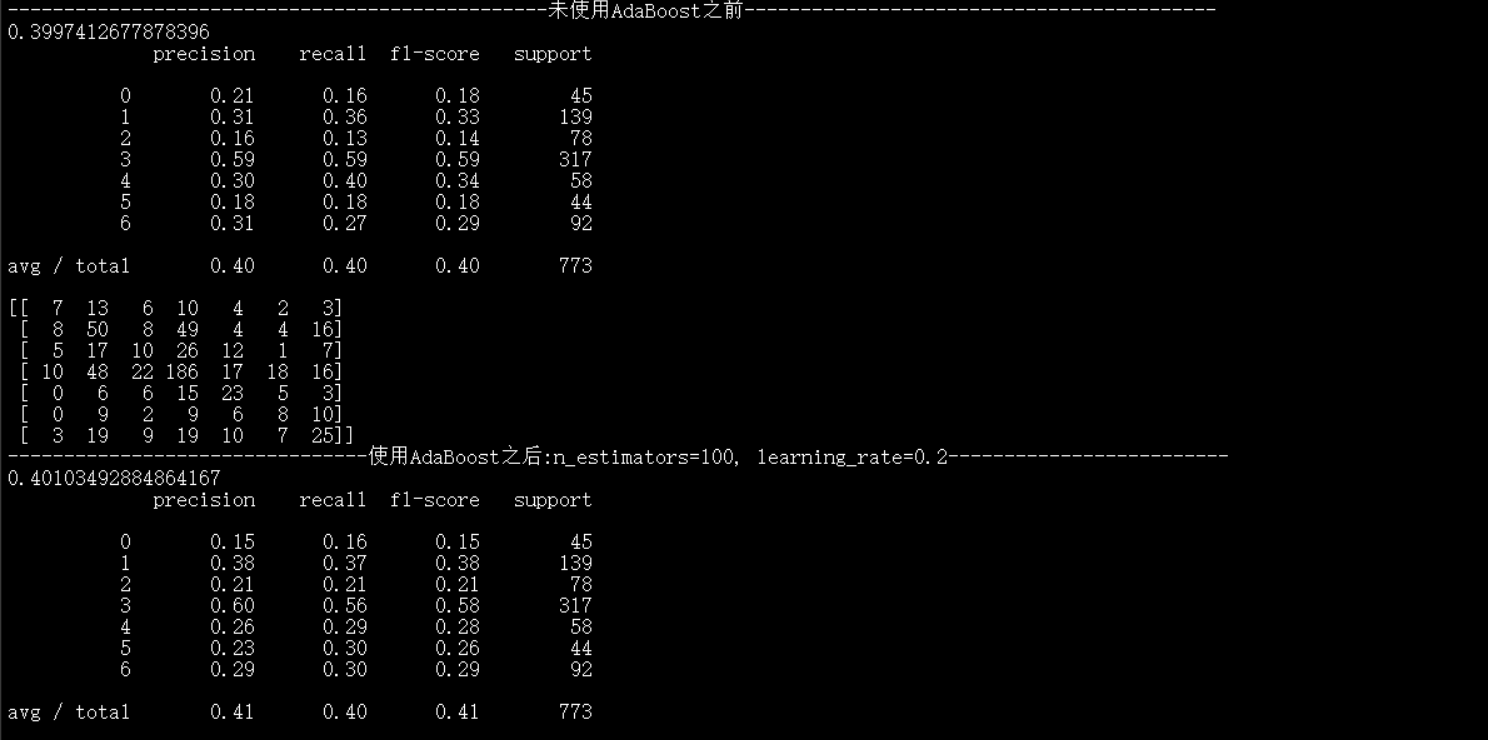
print("------------------------------------------------未使用AdaBoost之前------------------------------------------")
print(clf.score(x_test_pca, y_test)) #预测准确率
print(metrics.classification_report(y_test,y_test_predict1)) #包含准确率,召回率等信息表
print(metrics.confusion_matrix(y_test,y_test_predict1)) #混淆矩阵
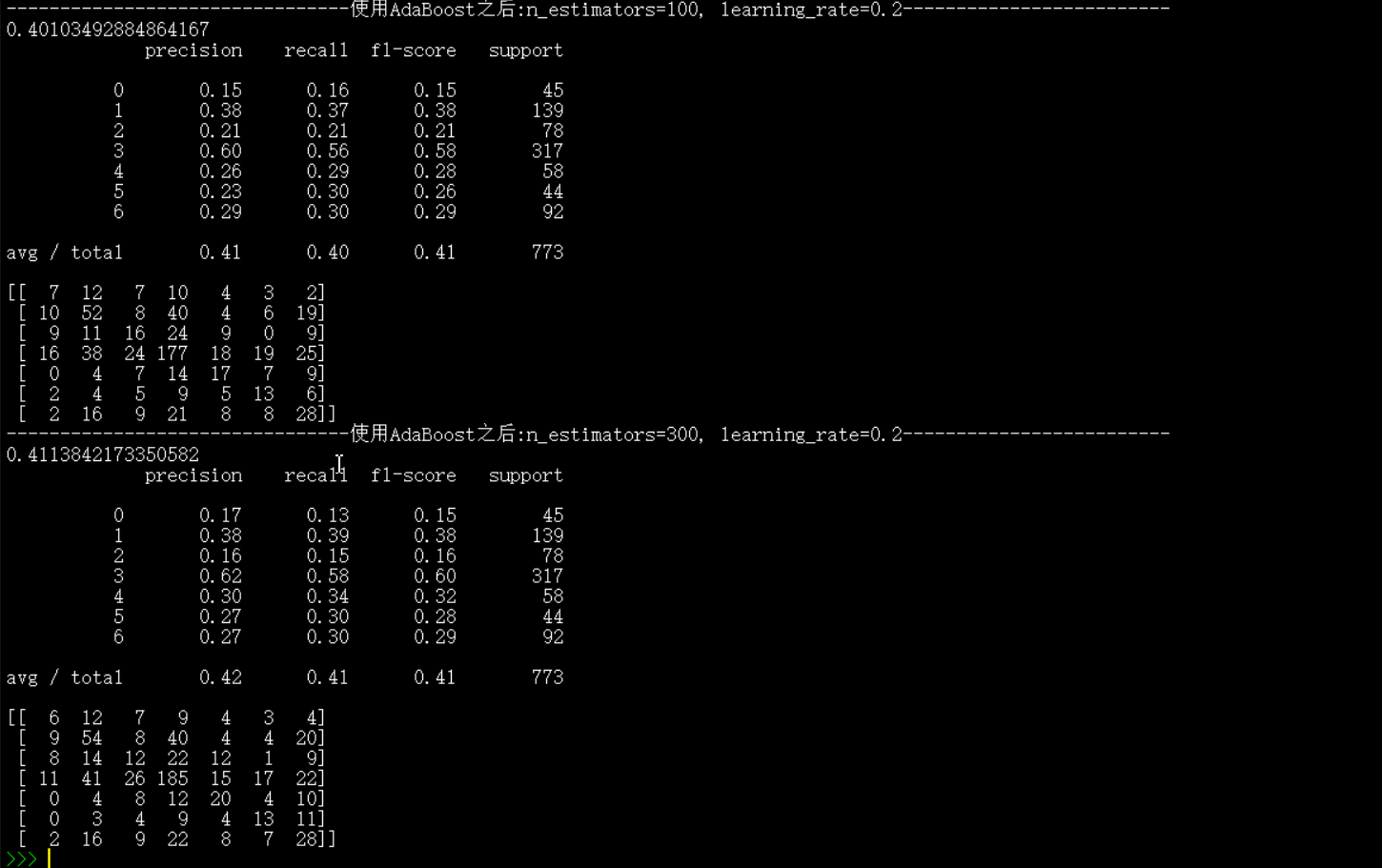
print("--------------------------------使用AdaBoost之后:n_estimators=100, learning_rate=0.2-------------------------")
print(Ada1.score(x_test_pca, y_test)) #预测准确率
print(metrics.classification_report(y_test,y_test_predict2)) #包含准确率,召回率等信息表
print(metrics.confusion_matrix(y_test,y_test_predict2)) #混淆矩阵
print("--------------------------------使用AdaBoost之后:n_estimators=300, learning_rate=0.2-------------------------")
print(Ada2.score(x_test_pca, y_test)) #预测准确率
print(metrics.classification_report(y_test,y_test_predict3)) #包含准确率,召回率等信息表
print(metrics.confusion_matrix(y_test,y_test_predict3)) #混淆矩阵
运行结果: