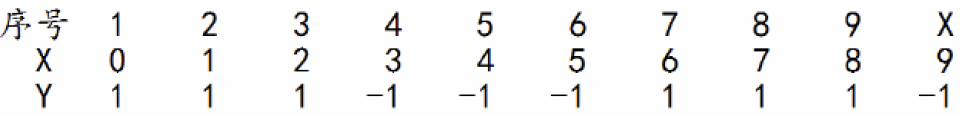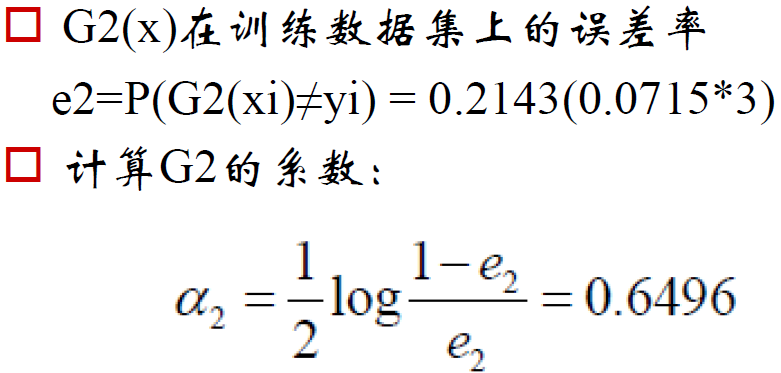

机器学习中决策树的讲解:
熵与互信息的关系:
![]()
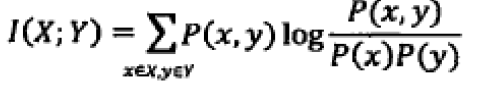
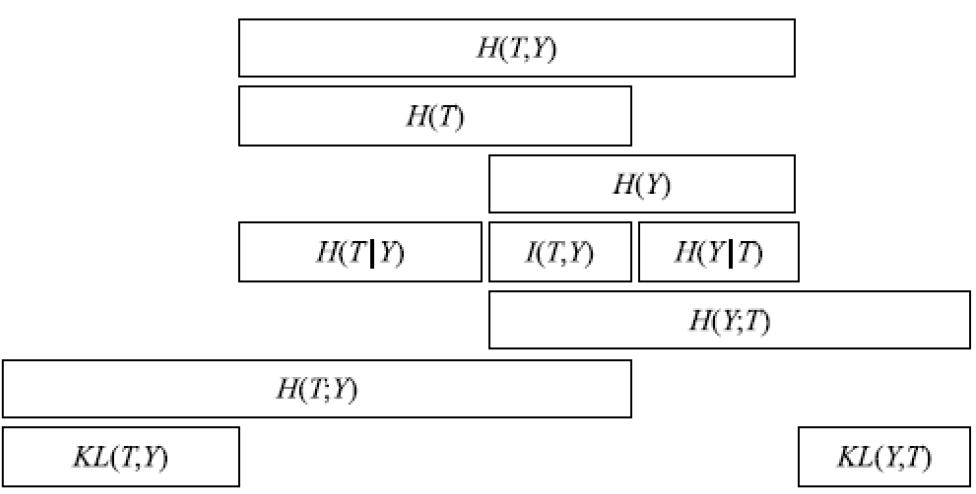
各个熵之间的关系:

决策树:
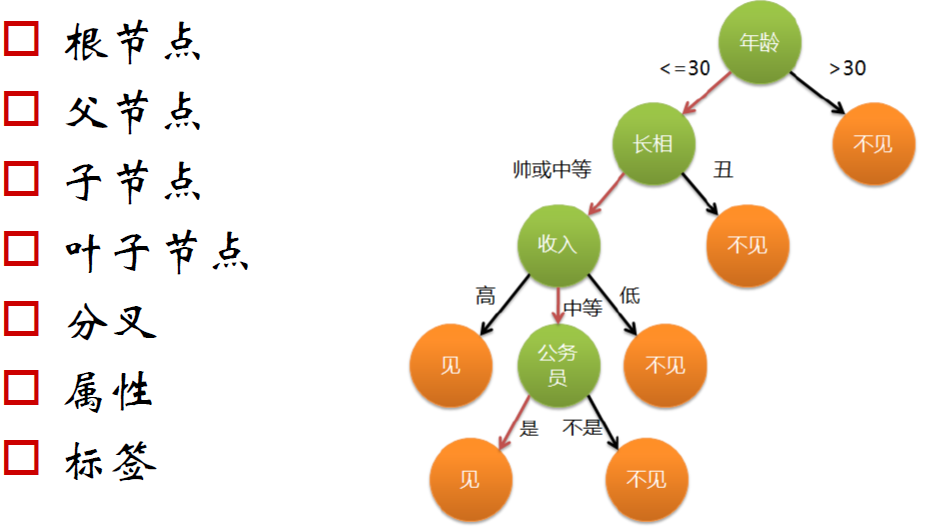
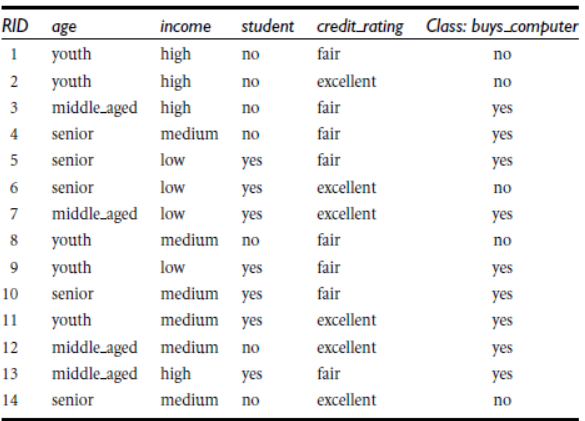
决策树学习采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为零,此时每个叶节点中的实例都属于同一类。
建立决策树的关键,即在当前状态下选择哪个属性作为分类依据。根据不同的目标函数,建立决策树主要有一下三种算法:
1:ID3:取值多的属性,更容易使数据更纯,其信息增益更大。训练得到的是一棵庞大且深度浅的树:不合理。
2:C4.5
3:CART:一个属性的信息增益(率)/gini指数越大,表明属性对样本的熵减少的能力更强,这个属性使得数据由不确定性变成确定性的能力越强

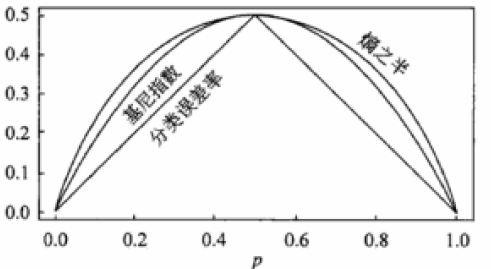
Gini系数的图像、熵、分类误差率三者之间的关系:

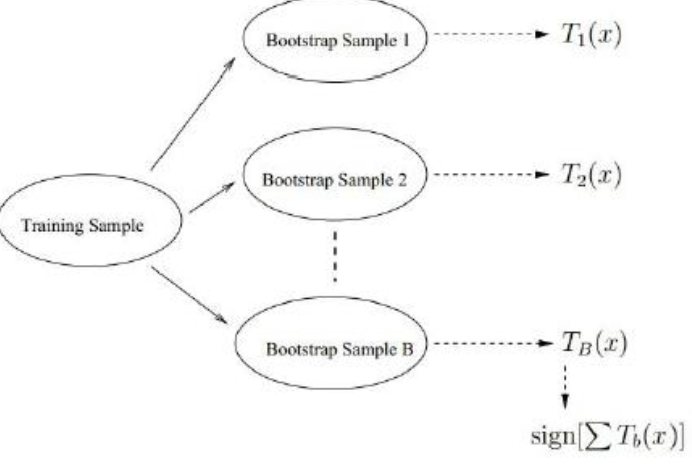
bagging策略:bootstrap aggregation:
从样本集中重采样(有重复的)选出n个样本
在所有属性上,对这n个样本建立分类器(ID3、C4.5、CART、SVM、Logistic回归等)
重复以上两步m次,即获得了m个分类器
将数据放在这m个分类器上,最后根据这m
个分类器的投票结果,决定数据属于哪一类
随机森林:
随机森林在bagging基础上做了修改。
从样本集中用Bootstrap采样选出n个样本;
从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树;
重复以上两步m次,即建立了m棵CART决策树
这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类
adaboost举例: