本文参考《Python数据分析与挖掘实战》一书
决策树在分类、预测、规则提取等领域都有着广泛的应用。关于决策树的算法,有ID3,C4.5,CART分类算法.
ID3算法基于信息熵来选择最佳的测试属性,这句话的意思就是,我们的决策树毕竟要形成一颗由根节点向下的树,每一个叶节点对应一个分类(即标签),每一个非叶节点对应其属性,属性是很多的,我们如何选择那?这就利用了信息论中的信息熵的知识.
下面展示一下利用Python实现决策树与其可视化的过程.
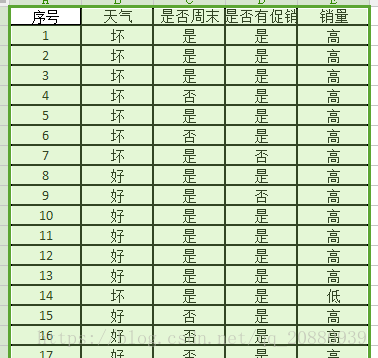
首先展示下数据:
该数据是由三个属性组成,(天气,是否周末,是否促销).一个标签(销量)
在程序具体实现时,我们需要将这些属性进行数字化的转化。而后,在Python的sklearn库中,已经存在处理决策树的包,我们引用即可实现对于决策树的处理.
另外注意的是,我们决策树产生的结果并不是可视化的形式,为了能够将其可视化的展示,有一个graphviz点击打开链接的工具可以将其可视化,注意在使用前需要先配置环境变量,将其bin目录加载到系统环境变量的Path路径下.然后可以将其可视化.
具体在运行Graphviz工具时,可以有两种方式,其一是通过命令行的方式,先找到我们运行完后的文件,然后将其转化为png或者pdf格式,或者在Graphviz的IDE下直接运行.
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 14 09:44:45 2018
@author: Administrator
"""
#使用ID3算法预测销量的高低
import pandas as pd
filename='E:/sales_data.xls'
data = pd.read_excel(filename, index_col = u'序号')
#导入数据,行指标为'列指标是序号的'那列数据
#数据是类别标签,要将它转换为数据,用u' '
#用1来表示“好”、“是”、“高”这三个属性,用-1来表示“坏”、“否”、“低”
data[data == u'好'] = 1
data[data == u'是'] = 1
data[data == u'高'] = 1
data[data != 1] = -1
x = data.iloc[:,:3].astype(int) #选取前三列数据
y = data.iloc[:,3].astype(int) #选取第四列数据,一定要设置x和y的数据类型
from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion='entropy') #建立决策树模型,基于信息熵
dtc.fit(x, y) #训练模型
#导入相关函数,可视化决策树。
#导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
with open("E:/tree.dot", 'w') as f:
f = export_graphviz(dtc, feature_names = x.columns, out_file = f)结果的可视化展示如下:
