一.参考链接
https://arxiv.org/abs/1706.03762
https://github.com/Kyubyong/transformer
http://jalammar.github.io/illustrated-transformer
二.概述
- 模型的整体架构图:

- 将Transform剥离出来其编码器部件,解码器部件及其它们的链接如下图:
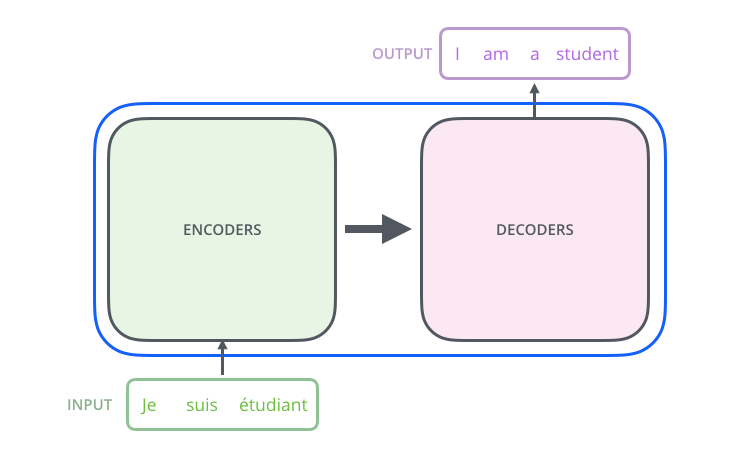
- 编码部件(encoding componen)和解码器部件(decoding component)分别由编码器(encoders)和解码器(decoders)的堆叠而成,论文中使用的是6个编码器(encoders)和解码器(decoders)分别组成编码部件(encoding componen)和解码器部件(decoding component):

- 架构中的6个编码器(encoders)是一样的,但是它们不共享参数;每个编码器由两个子层组成:self-attention layer+ feed-forward neural network layer:

- 架构中的6个解码器(decoders)是一样的;每个编码器由三个子层组成:self-attention layer+encoder-decoder attention+feed-forward neural network layer:

三.编码器
- embeding layer:将输入的词转化为张量,我们设置张量的维度为512。embeding仅仅存在编码器的底部。

- 编码器部件(encoding componen): 在这里,我们开始看到Transformer的一个关键属性,即每个位置的单词在编码器中的流动路径。self-attention layer中的这些路径之间存在依赖关系。然而,feed-forward layer不具有那些依赖性,因此各种路径可以在流过该层时并行执行。
 有这上面这张图片我们可以看出,一个句子中的词向量是一起流过self-attention层的,因为每个词可能与其他词产出关系,但每个词是独立的穿过feed forward neural network的,因为在这一层词与词之间没有关系
有这上面这张图片我们可以看出,一个句子中的词向量是一起流过self-attention层的,因为每个词可能与其他词产出关系,但每个词是独立的穿过feed forward neural network的,因为在这一层词与词之间没有关系
- feed-forward network layer:
- 该层的公式为: 由此可以看出来,该层是两个线性映射:一个是没有激活函数的一个是ReLU激活的。
四.自注意力层
- Self-Attention layer 概述:
- 假设我们要翻译这句话:”The animal didn’t cross the street because it was too tired”,在翻译时it指的是什么呢,是street还是animal呢。当模型在处理it时模型允许it联系词animal。

- 当模型处理每个单词(输入序列中的每个位置)时,self-attention允许该词查看输入序列中的其他位置以寻找可以帮助更好地编码该单词的线索。
- self-attention是Transform用来将其他相关单词的“理解”融入我们当前正在处理的单词中的方法。
- 假设我们要翻译这句话:”The animal didn’t cross the street because it was too tired”,在翻译时it指的是什么呢,是street还是animal呢。当模型在处理it时模型允许it联系词animal。
- Self-Attention layer 向量的计算过程
- 第一步: 我们为每层输入向量(在编码器的最地层就是词的embeding)建立三个向量:Q向量、K向量和V向量。这三个向量由输入向量分别乘以三个矩阵得到(线性映射),这三个矩阵在训练期间是可训练的。其实质这是将输入向量线性映射到三个空间中去得到三个向量。
注意: 这三个向量的维度是更小的,一般为64,而编码器的输出/输入和词的embeding维度都是512.即我们将一个高维空间的向量线性映射到低为的三个空间中去。
- 第二步:计算分数
假设我们计算上面例子中Thinking的self-attention,首先我们需要根据当前词(Thinking)对输入句子的每个单词进行评分.当我们在某个位置编码单词时,分数决定了对输入句子的其他部分放置多少关注度。我们将当前词的q向量与需要打分的词的k向量进行点乘得到这个词的分数。
- 第三/四步:
将上面的分数除以8(k向量维度的平方根),这会使得有更加稳定的梯度。然后再将所有分数穿过softmax层进行正则化。该softmax分数确定每个单词在该位置表达的程度。很明显,这个位置的单词将具有最高的softmax分数,但有时候关注与当前单词相关的另一个单词是有用的。
- 第五步:将句子中的每个词向量的v向量乘以其对应的分数。
- 第六步:将加权的v向量进行求和得到self-attention 层在这个位置的输出。

- 第一步: 我们为每层输入向量(在编码器的最地层就是词的embeding)建立三个向量:Q向量、K向量和V向量。这三个向量由输入向量分别乘以三个矩阵得到(线性映射),这三个矩阵在训练期间是可训练的。其实质这是将输入向量线性映射到三个空间中去得到三个向量。
- Self-Attention layer 矩阵的计算过程
- 第一步: 计算Q,K和V矩阵。我们将输入的词embeding合并到矩阵X中(batch data),我们将X乘以权重矩阵
得到响应的Q,K和V矩阵。

- 第二步: 输出self-attention结果

- 第一步: 计算Q,K和V矩阵。我们将输入的词embeding合并到矩阵X中(batch data),我们将X乘以权重矩阵
得到响应的Q,K和V矩阵。
五、多头自注意力层
- 本文通过增加一种称为multi-headed attention,进一步完善了self-attention layer。在两个方面改善了性能:
- 扩展了模型关注不同位置的能力,
- 为注意层提供了多个“表示子空间”

- 在论文中我们使用8个头,8个头分别经过第四部分的计算可以得到8个Z矩阵。

- 由于我们的feed-forward layer的输入只是一个矩阵,矩阵中每一行代表一个词。所以我们将8个Z进行拼接,再乘以一个
矩阵的将拼接的结果映射到feed-forward layer需要维度的矩阵。
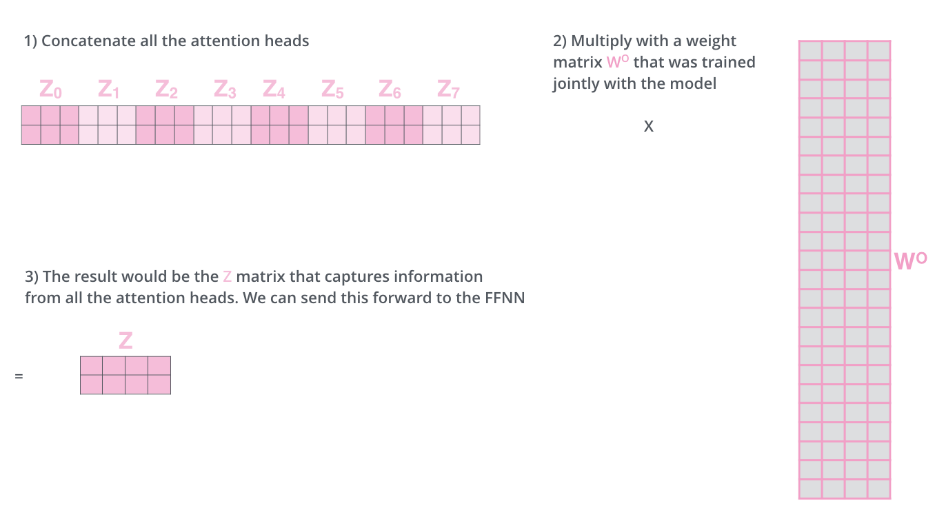
- 总图:

- multi-headed attention 例子图:

六、使用位置编码表示序列的顺序
- 这一部分是为了将词在句子中的位置编码到词的embeding中去。transformer为每个输入词向量添加了一个位置向量。位置向量遵循特定的模式,这有助于确定每个单词的位置,或者序列中不同单词之间的距离。这里的直觉是,将这些值添加到词向量中,一旦它们被投影到Q/K/V向量中和在点积attention期间,就在词向量之间提供有意义的距离。

- 位置向量遵循的模型:
每一行代表一个位置向量,维度为512,值在-1到1之间。你可以看到它在中心区域分成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们连接起来以形成每个位置编码矢量。
- 生成的函数公式:
七、残差连接:
- 图示:

- 每个编码器中的每个子层(self-attention, ffnn)在其后面都有残余连接+正则化层。这也适用于解码器的子层。

八、 解码器
- 编码部件和解码部件的协作如下图,编码部件顶端编码器的输出经过线性变换生成K和V向量,这些成为Encoder-Decoder Attention层中的K/V向量,这有助于解码器关注输入序列中的适当位置:

- 下图的后一张图片表示的是翻译第一个词I的过程:

- 重复上图步骤直至产生句子结束符翻译结束。每个步骤的输出被馈送到底部解码器以产生下一个翻译的词,在解码器的底部我们输入和编码器一样是词向量加位置向量。

- 解码器中self-attention层与编码器中的有点不一样:
- 在解码器中,仅允许自self-attention层关注输出序列中的当前位置的前面位置。这是通过在self-attention中计算分数的softmax时屏蔽后面位置来完成的(设置器为-inf)。
- Encoder-Decoder Attention层就像multiheaded self-attention一样,但有一点不同就是它的K和V向量矩阵是由编码组件顶部输出经过线性变换得到的,而Q向量矩阵是由下一层self-attention输出经过线性变换得到的。
九、 最后的线性映射层
- 解码器组件顶端的解码器的输出是一个浮点型的向量,我们要通过一个线性映射将其投影到词上面去,再经过一个softmax层得到最终的输出。
- 这个线性映射层其实质就是一个全连接神经网络,它将解码组件的最终输出向量投影到一个叫logits向量上去,logits向量的维度等一词汇表的长度。
- Softmax层就是将logits向量中的分数转化为概率。

- 根据softmax层输出向量得出最终预测的方式有两种:
- 贪婪解码(greedy decoding):选择向量中的最大概率作为当前词的预测
- 波束搜索(beam search):假设beam size为2,那么我在第一步的预测中选取两个概率最大的词 和 然后分别作为第二步解码器的输入,这样我们得到两个对应的softmax输出分布 。这样产生(2词汇表长度条)路径,每条路径2个词,计算每条路径的概率,选择从(2词汇表长度条)条路径中选取两条概率最大的路径: ,再用 作为输入重复这个过程,最终得到两路径选取最大概率的那条作为预测。