文章目录
Attention Is All You Need
MLP-RNN-seq2seq/编码器解码器架构-注意力机制-自注意力-transformer
MLP (多层感知器): MLP是一种基本的前馈神经网络架构,它由多个全连接层组成,每个层之间都有激活函数。它在深度学习中扮演了关键角色,用于解决各种问题,包括图像分类和语音识别。
RNN (循环神经网络): RNN是一种递归神经网络,特别适用于处理序列数据,如自然语言文本或时间序列。RNN中的循环结构允许信息在序列中传递,但它也有梯度消失和梯度爆炸等问题。
Seq2Seq (序列到序列): 序列到序列模型是一种将输入序列映射到输出序列的神经网络架构。它通常用于机器翻译和自然语言生成等任务,其中编码器将输入序列编码成上下文向量,解码器根据上下文向量生成输出序列。
编码器-解码器架构: 这是一种常见的神经网络架构,用于序列到序列任务。编码器负责将输入序列编码成一个固定长度的上下文向量,而解码器则根据上下文向量生成输出序列。 这种架构已经成功应用于机器翻译和对话生成等任务。
注意力机制: 注意力机制是一种机制,用于在解码器生成输出序列时关注输入序列的特定部分。它允许模型更好地处理长序列并捕获关键信息。注意力机制在提高翻译和生成质量方面发挥了重要作用。
自注意力 (Transformer): Transformer是一种革命性的神经网络架构,引入了自注意力机制。它摒弃了传统的RNN结构,允许模型并行化处理序列数据。Transformer已经成为自然语言处理中的标准架构,如BERT和GPT系列模型都是基于Transformer的。
这一进程的关键发展是将这些组件相互整合,从MLP和RNN到Seq2Seq和最终的Transformer。Transformer以其出色的性能和能力推动了自然语言处理领域的发展,开创了许多自动化文本处理任务的新标准。自注意力机制的引入使模型能够更好地理解序列中的依赖关系,从而提高了许多NLP任务的性能。
引言
- RNN(LSTM和GNN)仍是sequence modeling(语言建模)和transduction problems(机器翻译)的范式。大量的努力继续推动循环语言模型和编码器-解码器架构的边界
- RNN 特点(缺点):从左往右一步一步计算,对第 t 个状态 ht,由 ht-1(历史信息)和 当前词 t 计算。 这种固有的顺序性质排除了训练示例中的并行化,这在较长的序列长度下变得至关重要,因为内存约束限制了跨示例的批处理。
- Attention 在 RNN 上的应用: attention用在怎么把 encoder 的信息有效的传给 decoder,允许建模 input or output sequence 与距离无关的 dependencies
背景
写出自己论文与别的论文的联系和区别
在CNN中,假设使用3*3的卷积,则要到很深的层,才能学习到大部分的图像(sequential computation),这使得学习距离远的位置的之间的依赖关系变得困难。(如果 2 个像素隔得比较远,需要用很多 3 * 3 的卷积层、一层一层的叠加上去,才能把隔得很远的 2个像素联系起来。)
Transformer 的 attention mechanism 每一次看到所有的像素,一层能够看到整个序列。
多个输出通道,每个通道可以识别不同的模式。
Transformer 的 multi-head self-attention 模拟 CNNs 多通道输出的效果。
不同点:the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution.
模型架构

At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
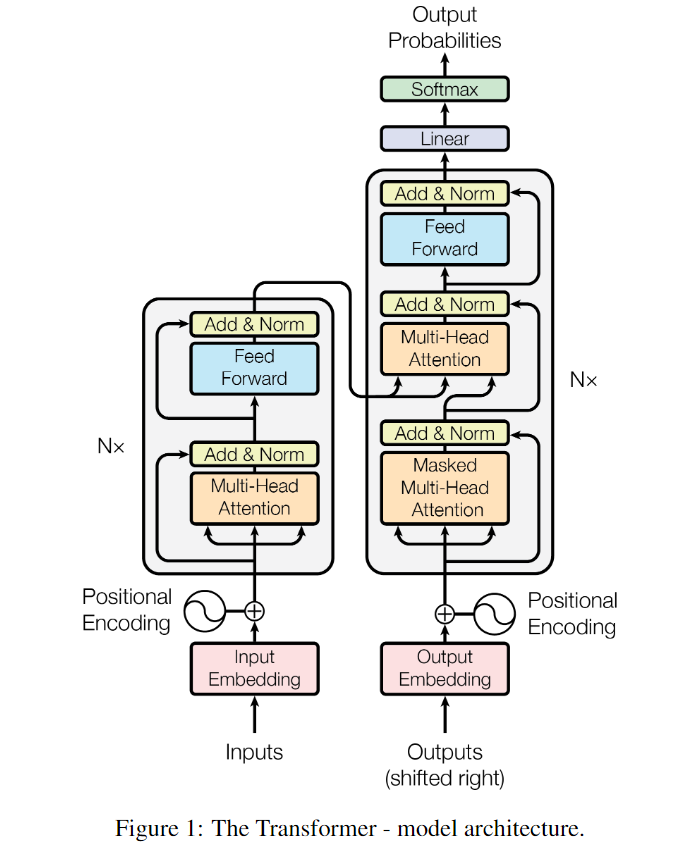
Inputs ---- Input Embedding
输入经过一个 Embedding层, i.e., 一个词进来之后表示成一个向量。得到的向量值和 Positional Encoding (3.5)相加。
Transformer 的block
Multi-Head attention
Add & Norm: 残差连接 + Layernorm
Encoder 的核心架构
N个 Transformer 的 block 叠在一起。
每个 layer 有 2 个 sub-layers。
第一个 sub-layer 是 multi-head self-attention
第二个 sub-layer 是 simple, position-wise fully connected feed-forward network, 简称 MLP
每个 sub-layer 的输出做 残差连接 和 LayerNorm
公式:LayerNorm( x + Sublayer(x) )
Sublayer(x) 指 self-attention 或者 MLP
residual connections 需要输入输出维度一致,不一致需要做投影。简单起见,固定 每一层的输出维度dmodel = 512
简单设计:只需调 2 个参数 dmodel 每层维度有多大 和 N 多少层,影响后续一系列网络的设计,BERT、GPT。
Remark:和 CNN、MLP 不一样。MLP 通常空间维度往下减;CNN 空间维度往下减,channel 维度往上拉。
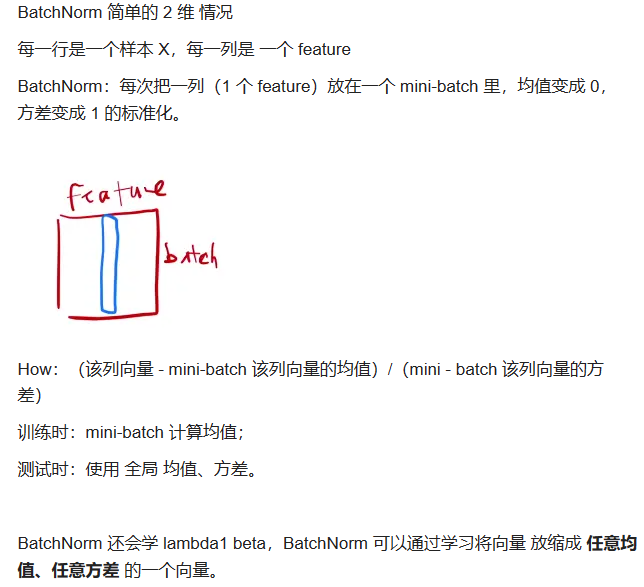
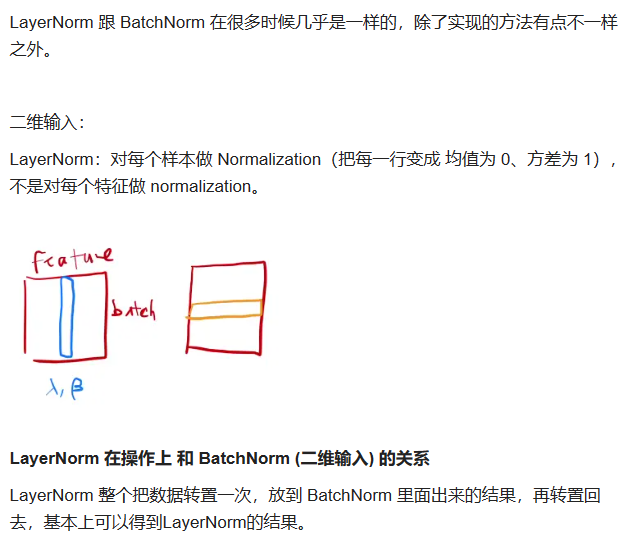
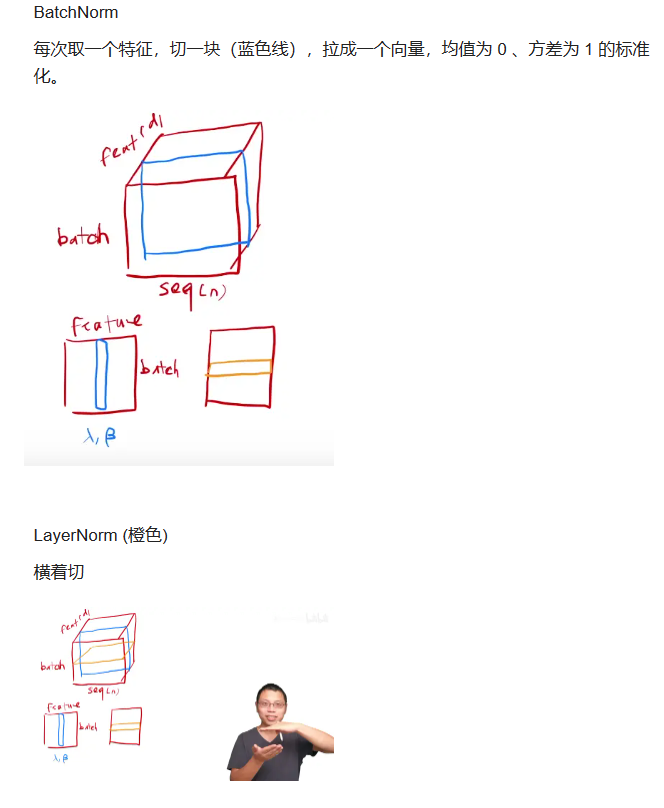
对于二维数据来说:BN相当于对每一个特征做归一化,LN相当于对每一个样本做归一化。

Decoder 的核心架构
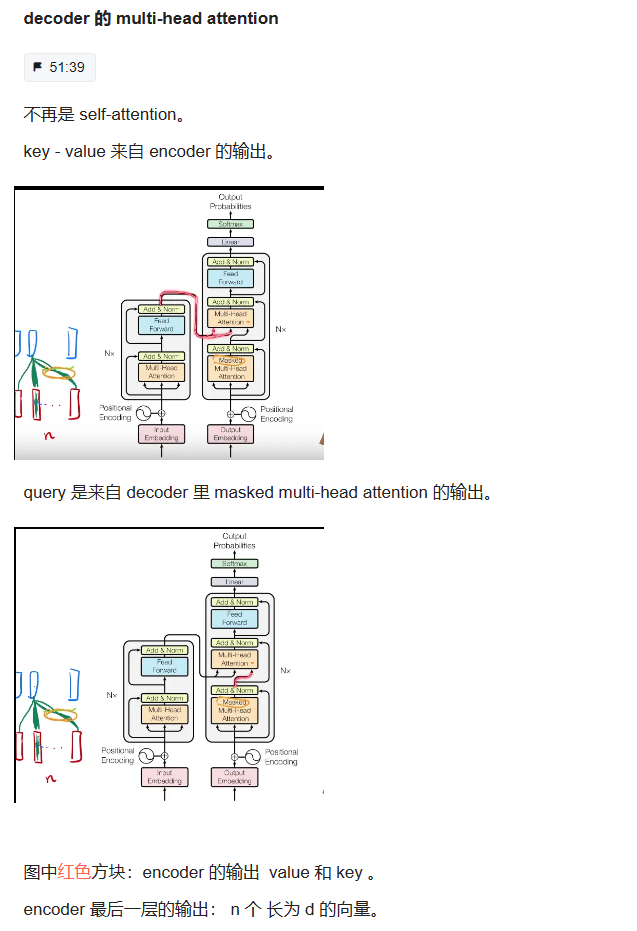
encoder 的输出 作为 decoder 的输入。
多了一个 Masked Multi-Head Attention。

如何做MASK???
decoder的输出进入一个 Linear 层,做一个 softmax,得到输出。
Linear + softmax: 一个标准的神经网络的做法
Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output.
output 是 value 的一个加权和 --> 输出的维度 == value 的维度。 output 中 value 的权重 = 查询 query 和对应的 key 的相似度 or compatibility function 权重等价于 query 和对应的 key 的相似度 虽然 key-value 并没有变,但是随着 query 的改变,因为权重的分配不一样,导致输出会有不一样,这就是注意力机制。
作者:单位年
https://www.bilibili.com/read/cv13759416/?jump_opus=1 出处:bilibili
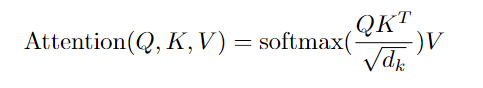





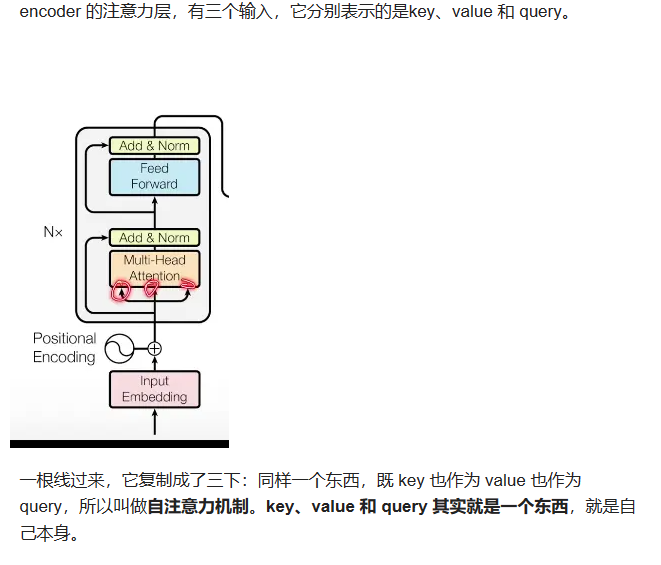
总结:Transformer 是一个比较标准的 encoder - decoder 架构。
区别:encoder、decoder 内部结构不同,encoder 的输出 如何作为 decoder 的输入有一些不一样。
Multi-Head Attention
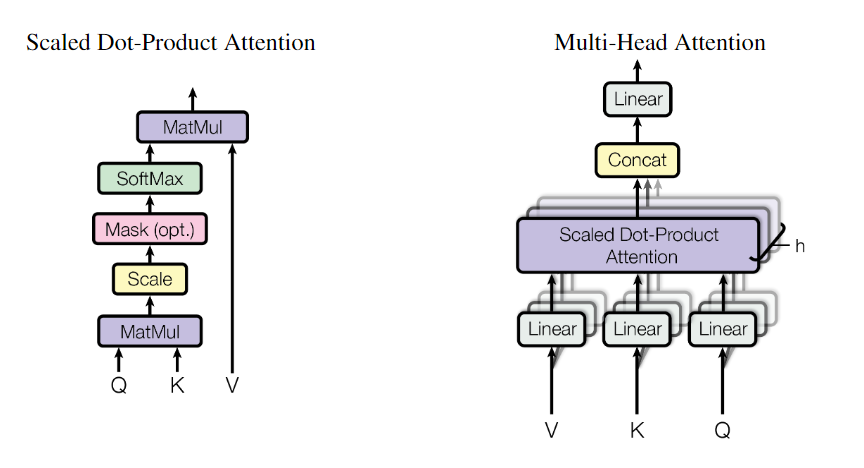
我们发现,与其使用dmodel维度的键、值和查询执行单一的注意力函数,不如将查询、键和值分别以不同的、学习过的线性投影h次线性投影到dk、dk和dv维度,这是有益的。然后,在查询、键和值的每个投影版本上,我们并行执行注意力函数,生成dv维输出值。将它们连接起来并再次进行投影,得到最终值。

多头注意允许模型在不同位置共同注意来自不同表示子空间的信息。对于单一注意力头,平均会抑制这一点。allows the model to jointly attend to information from different representation subspaces at different positions.

multi-head attention 给 h 次机会去学习 不一样的投影的方法,使得在投影进去的度量空间里面能够去匹配不同模式需要的一些相似函数,然后把 h 个 heads 拼接起来,最后再做一次投影。
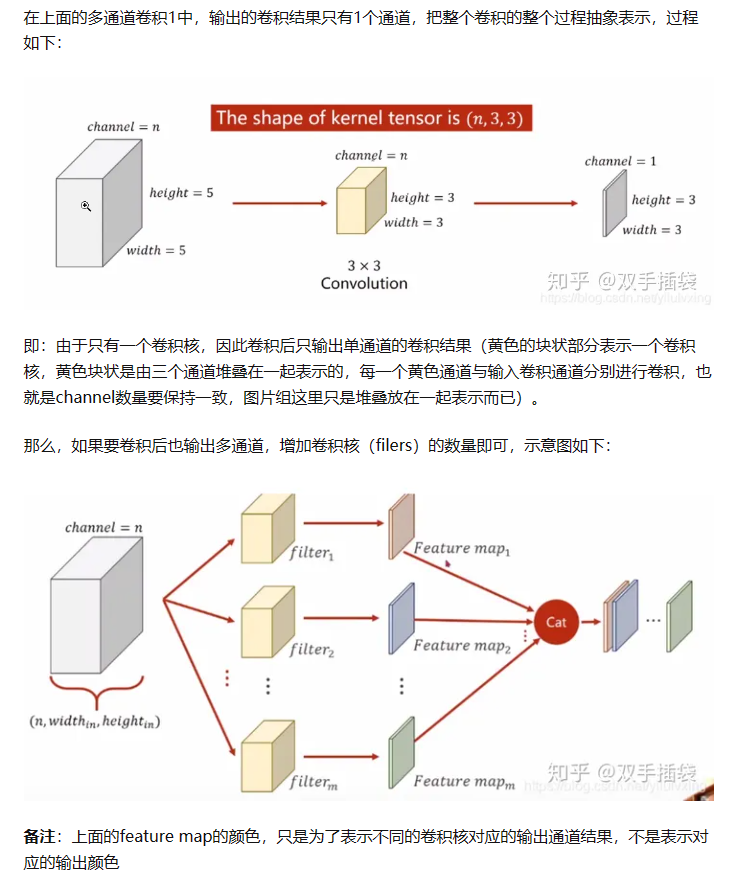
在CNN中,卷积层通常包括多个滤波器或卷积核,每个滤波器都负责检测输入数据的不同特征或模式。每个滤波器都会对输入数据进行卷积操作,生成一个特征图(通道),这些特征图可以捕获输入数据的不同方面的信息。
类似地,在注意力机制中,将查询、键和值分别进行多次线性投影到不同的维度,就像在不同的"通道"中学习不同的特征。每个线性投影都将输入数据映射到一个不同的表示子空间中,这些表示子空间可以捕获输入数据的不同方面或关系。每个子空间可以被视为一个注意力头(attention head),类似于CNN中的不同输出通道。
就像CNN中的多个输出通道可以捕获不同的图像特征一样,注意力机制中的多头注意力可以捕获输入序列中不同方面的信息,从而提高了模型对输入的理解能力。这种并行处理不同子空间的方法也有助于提高模型的泛化能力,因为不同的头可以学习到不同的特征。
Applications of Attention in our Model
Positional Encoding

1.Transformer为何使用多头注意力机制?(为什么不使用一个头)
2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
5.在计算attention score的时候如何对padding做mask操作?
6.为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
7.大概讲一下Transformer的Encoder模块?
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
9.简单介绍一下Transformer的位置编码?有什么意义和优缺点?
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
11.简单讲一下Transformer中的残差结构以及意义。
12.为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
13.简答讲一下BatchNorm技术,以及它的优缺点。
14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
15.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
17.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
19.Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
20解码端的残差结构有没有把后续未被看见的mask信息添加进来,造成信息的泄露。