前言
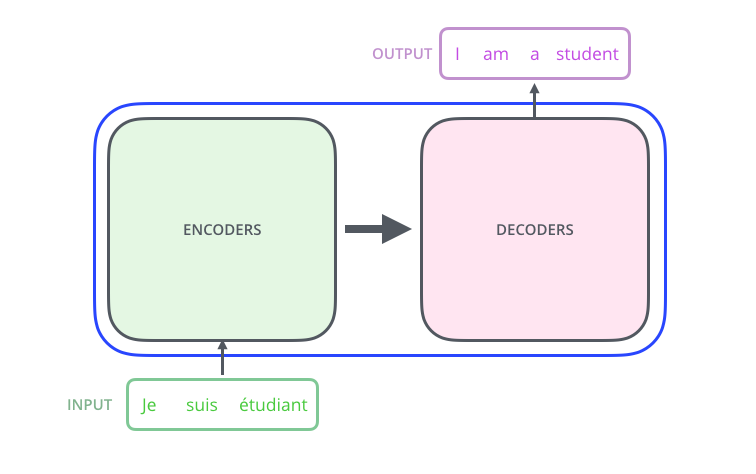
Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的方式映射成(y1, y2 ... ym), 之前的做法是用RNN进行encode-decoder,但是由于RNN在某一时间刻的输入是依赖于上一时间刻的输出,所以RNN不能并行处理,导致效率低效,而Transfomer就避开了RNN,因此encoder-decoder效率高。
Transformer
从一个高的角度来看Transformer,它就是将源语言 转换 成目标语言

打开Transformer单元,我们会发现有两个部分组成,分别是encoders单元和decoders单元
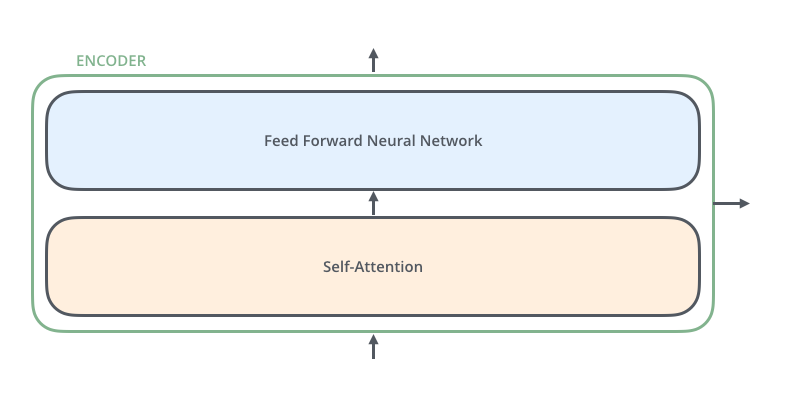
而对于encoders单元,它是由六个encoder组成的,同样decoders单元,它也是由六个decoders组成。

对于每一个encoder,它们结构都一样的,但是权重不共享,每一个encoder的结构都是由两部分组成,分别是self-attention和feed forward neural network。
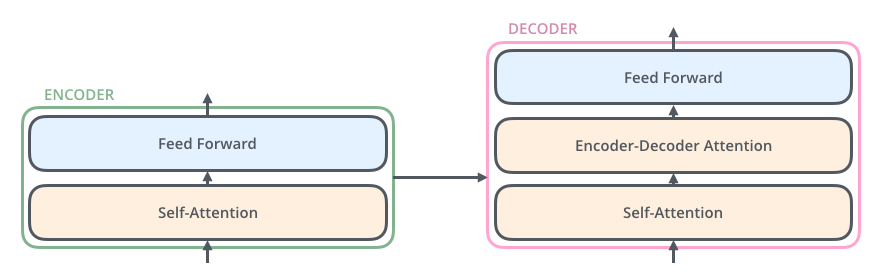
Transformer的处理流程是这样的:输入数据传给self-attention,然后selft-attention计算每一个位置的与其他位置的相关性,从而获得每一个位置的输出结果,该输出结果传给FFNN,得到第一个encoder的输出z1,z1作为第二个encoder的输入,步骤如上,直到最后一个encoder输出 ouput。
该输出ouput,在传给decoder,大致过程和encoder一致,有些许差异,稍后分析。
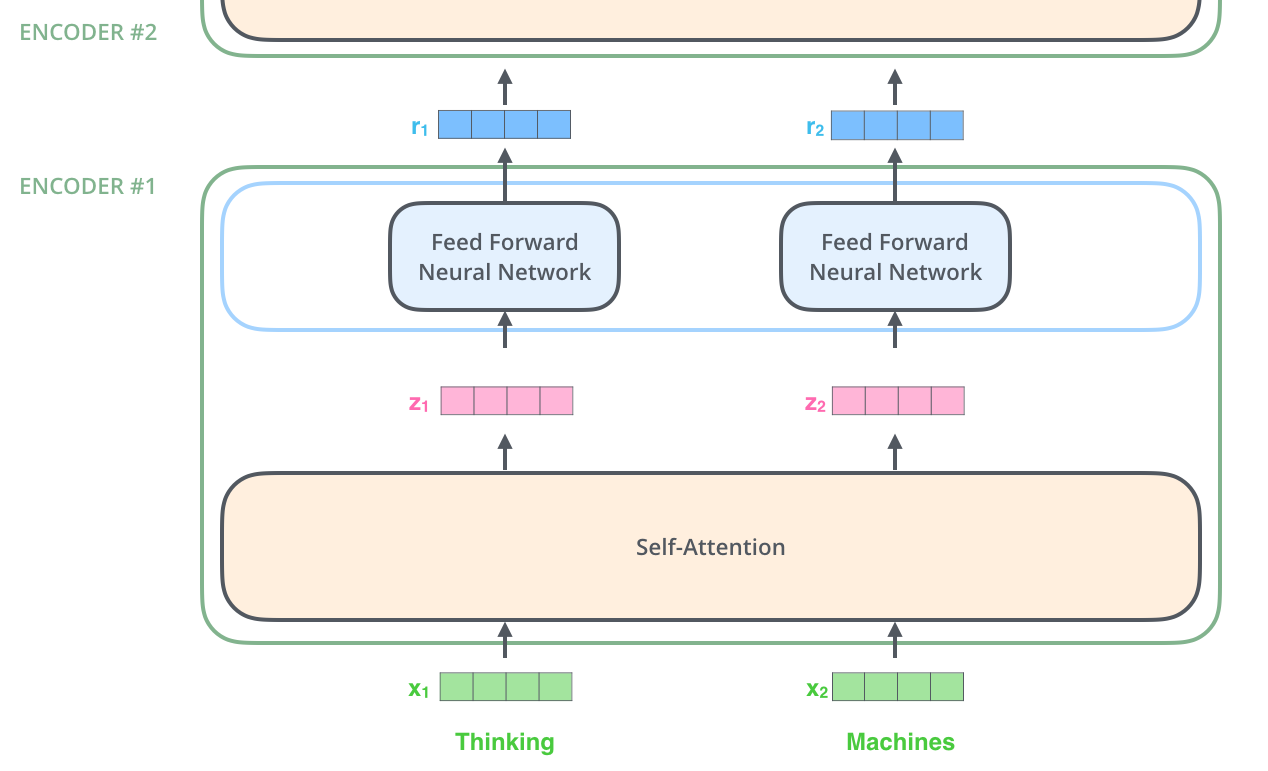
具体示例:
参考: