1 介绍
主流的序列转换模型是基于复杂的循环或卷积神经网络,它们包括一个encoder和一个decoder。表现最好的模型也是用attention 机制连接encoder和decoder。我们提出了一个新的简单网络模型,即Transformer,该模型仅仅依靠attention机制,不用循环或卷积网络。实验结果显示该模型不仅质量很好,而且可以并行,需要较少的时间训练。
循环网络模型主要是输入和输出序列的符号位置的因子计算。位置对齐计算时,需要序列的hidden state 、上一步的hidden state和输入的位置。这些序列内在性质阻扰了训练时的并行训练。
Transformer是第一个只依靠self-attention来计算输入和输出的转换模型,没有使用RNN或者卷积网络。
Transformer相比于循环或卷积结构的网络训练更快,而且也取得了更好的效果。
2. 模型结构
Encoder匹配输入序列(x1,x2…xn)到一个连续序列z=(z1,z2…zn)。
给定z下,decoder 生成输出序列(y1,y2…ym),一次生成一个元素。
在每一步,模型是自动回归的,当生成下一个符号(symbol)时,会采用上一步生成的符合作为附加的输入。
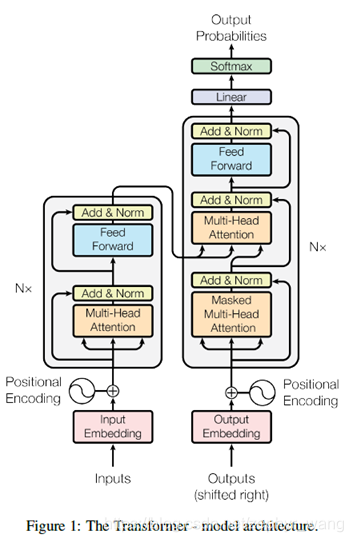
如上图,transformer 包括一堆self-attention、逐点方式,以及encoder和decoder间的全连接层。
2.1 Encoder and Decoder Stacks
Encoder:encoder采用N=6个相同层的堆叠。每个层有两个子层,第一个是multi-head self-attention,第二个是一个简单的、位置方面的全连接feed-forward network。在这两个子层,我们会采用残差连接。也就是说,每个子层的输出是LayerNorm(x+Sublayer(x)),其中Sublayer(x)是子层自己的实施函数。为了便于残差连接,所有子层,包括embedding 层,都会产生d_model=512维的输出。
Decoder:decoder也是采用N=6个相同层的堆叠。decoder除了上面说的两个子层外,还有第三个层,它是在每个encoder stack的输出上进行multi-head attention。Decoder也是采用残差连接。我们修改其中的self-attention 子层为masked,阻止位置信息参加后续的位置。因为output embedding 是一个位置的offset,这个mask确保了位置i的预测仅仅依靠位置i之前的输出。
2.2 Attention
一个attention函数可以描述成将query vector和kye-value vector 映射到输出。输出是 values vector的权重相加,其中权重的值是通过query和相应key的兼容方程计算得到。
2.2.1 Scaled Dot-Product Attention


2.2.2 Multi-Head Attention

2.2.3 Applications of Attention in our Model
Transformer使用multi-head attention有三种不同的方式,如下:
1.在"encoder-decoder attention"层,queries来自前面的decoder层,keys和values来自于encoder的输出。这样容许decoder中的每个位置关注输入序列的所有位置。
2.Encoder 包含self-attention。在一个self-attention中,所有的keys、values和queries来自相同的地方。在encoder中的每个位置会关注encoder上一层的所有位置。
3.相似的,decoder中的self-attention容许decoder每个位置关注decoder的所有位置。我们需要阻止左侧的decoder信息流,来保持自回归。在scaled dot-product attention中,mask 非法链接对应的softmax的输入为负无穷。
2.2.4 Position-wise Feed-Forward Networks
Feed-forward 网络独立的、相同的应用于每一个位置。这包括两个线性转换,它们之间是ReLu激活函数。
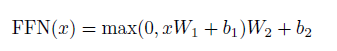
线性转换是相同的通过不同的位置,它们从层到层使用不同的参数。另一种说法是,这是两个kernel size=1的两个卷积。输入和输出的维度都d_model=512,内层的维度是d_ff=2048。
2.2.5 Embeddings and Softmax
我们使用embedding将输入和输出转换成d_model维的vector。我们也使用线性转换和softmax函数将decoder的输出转换成下一个的期望概率。在模型中,我们在两个embedding 层和pre-softmax 线性转换之间共享相同的权重矩阵。在embedding层,我们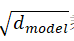 乘以这些权重。
乘以这些权重。
2.2.6 Positional Encoding
因为我们的模型没有使用循环和卷积,为了让模型利用序列的顺序,我们必须在序列中注入一些相对或者绝对的位置信息。为此,我们在encoder和decoder 堆叠的底部对于输入的embedding增加“positional encoding”。positional encoding和embedding拥有相同的维度d_model,以便这两个可以相加。
我们使用不同频率的sine和cosine函数。Pos是位置position,i是维度。
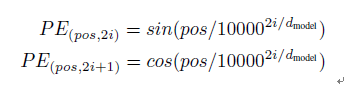
positional encoding的每一个维度对应着一个正弦。波长形成一个从2π到10000*2π的几何序列。我们选择这个函数是因为我们假设它会使模型容许学习关注相对位置,对于任何一个偏远k,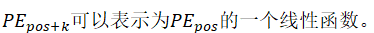 。
。
positional encoding可以用固定的(如上面公式),也可以用可以学习的。发现这两种方式产生的效果相同。我们选择正弦版本,是因为它容许模型推断的序列长度更长。
3. 什么使用Attention

1.每层的计算复杂度。如上表第二列。
2.如上表第三列。可以并行计算的计算量,可以通过sequential operations的最小数量来衡量。
3.如上表最后一列。网络中远距离依赖关系之间的路径长度。学习远距离依赖在许多序列转换任务中是一个关键挑战。
4 训练结果
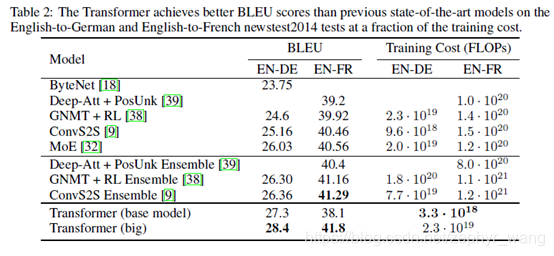
进行了English-German、English-French的训练。可以看见transformer的BLEU较高。
BLEU((其全称为Bilingual Evaluation Understudy), 其意思是双语评估替补), 它是用于评估模型生成的句子(candidate)和实际句子(reference)的差异的指标。BLEU方法的实现是分别计算candidate句和reference句的N-grams模型。