Transformer
1 前言
谷歌团队2018提出的用于生成词向量的BERT算法在NLP的11项任务中取得了非常出色的效果,堪称2018年深度学习领域最振奋人心的消息。而BERT算法又是基于Transformer,Transformer又是基于attention机制。
2 Encoder-Decoder
2.1Encoder-Decoder简介
目前大部分attention模型都是依附于Encoder-Decoder框架进行实现,在NLP中Encoder-Decoder框架主要被用来处理序列-序列问题。
- 文本摘要,输入一篇文章(序列数据),生成文章的摘要(序列数据)
- 文本翻译,输入一句或一篇英文(序列数据),生成翻译后的中文(序列数据)
- 问答系统,输入一个question(序列数据),生成一个answer(序列数据)
2.2Encoder-Decoder结构原理
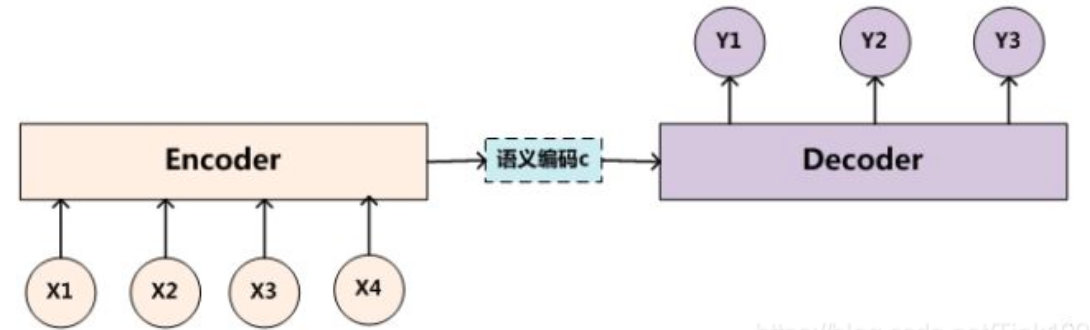
Encoder:编码器,对于输入的序列<x1,x2,x3…xn>进行编码,使其转化为一个语义编码C,这个C中就储存了序列<x1,x2,x3…xn>的信息,Encoder编码方式,RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU
Decoder:解码器,根据输入的语义编码C,然后将其解码成序列数据,解码方式也可以采用RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU。
3 Attention Model
3.1Attention 注意力机制简介
同一张图片,不同的人观察注意到的可能是不同的地方,这就是人的注意力机制。attention 就是模仿人的注意力机制设计地。
3.2Attention 原理
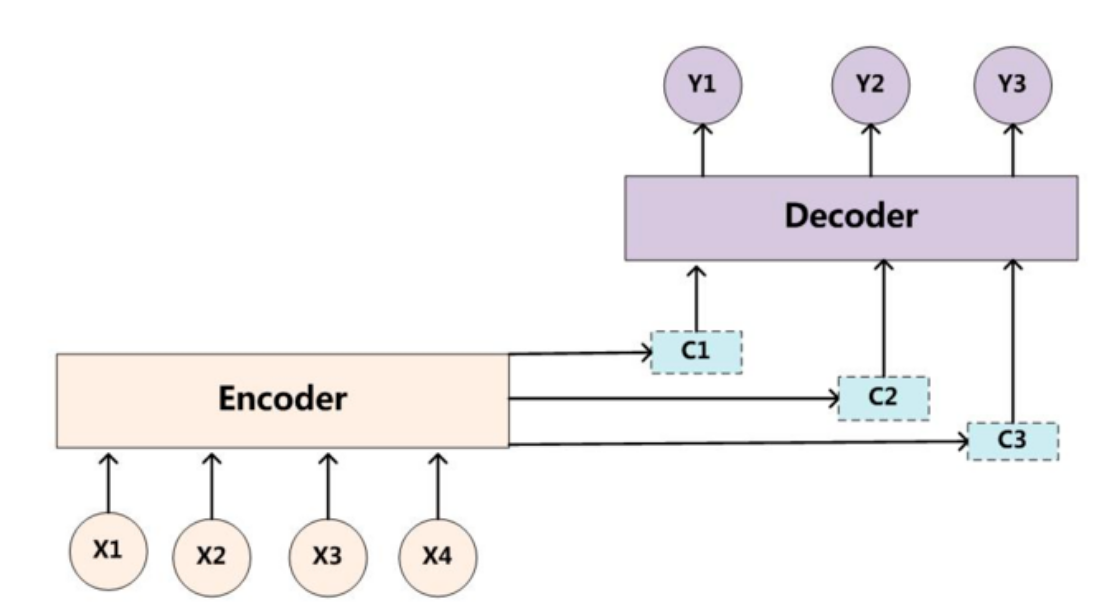
上图就是引入了Attention 机制的Encoder-Decoder框架。咱们一眼就能看出上图不再只有一个单一的语义编码C,而是有多个C1,C2,C3这样的编码。当我们在预测Y1时,可能Y1的注意力是放在C1上,那咱们就用C1作为语义编码,当预测Y2时,Y2的注意力集中在C2上,那咱们就用C2作为语义编码,以此类推,就模拟了人类的注意力机制。
由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。
g函数就是加权求和。αi表示权值分布。
C i = ∑ j = 1 n α i j h j C_{i}=\sum_{j=1}^{n} \alpha_{i j} h_{j} Ci=∑j=1nαijhj
3.3Attention 机制的本质思想
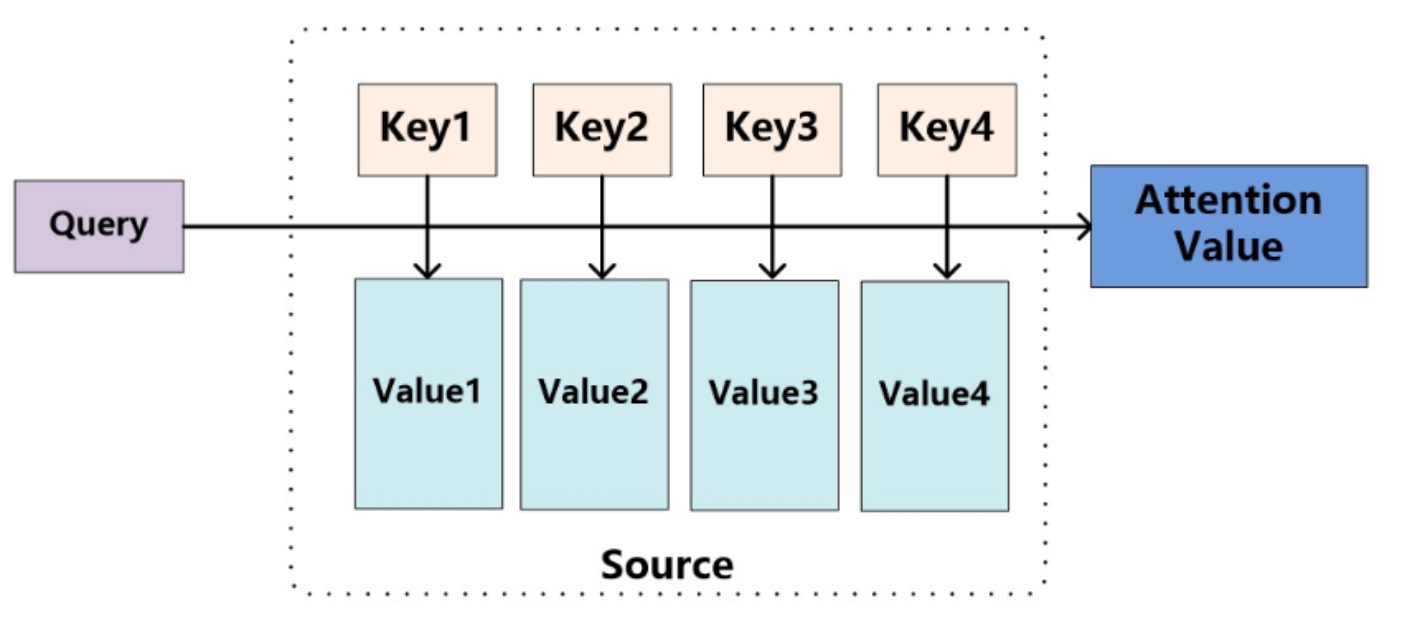
参照上图可以这么来理解Attention,将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成(对应到咱们上里面的例子,key和value是相等地,都是encoder的输出值h),此时给定Target中的某个元素Query(对应到上面的例子也就是decoder中的hi),通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
Attention ( Query, Source ) = ∑ i = 1 L x Similarity ( Query , Key i ) ∗ Value i \operatorname{Attention}(\text { Query, Source })=\sum_{i=1}^{L_{x}} \operatorname{Similarity}\left(\text { Query }, \text { Key }_{i}\right) * \text { Value }_{i} Attention( Query, Source )=∑i=1LxSimilarity( Query , Key i)∗ Value i
Lx表示source的长度,Similarity(Q,Ki)计算如下:

点积:就是将Query和Keyi进行点积,Transformer中就是用的这种方法。
Cosine相似性-余弦相似度:
分子就是两个向量Query与Key的点积
分母就是两个向量的L2范数,(L2范数:指向量各元素的平方和然后求平方根)
计算出Query和Keyi的相似性后,第二阶段引入类似SoftMax的计算方式对第一阶段的相似性得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
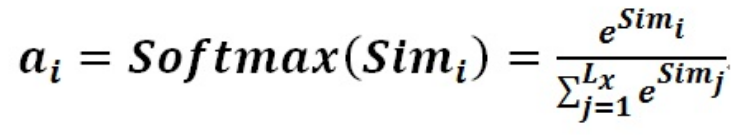
第二阶段的计算结果 ai 即为 Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:
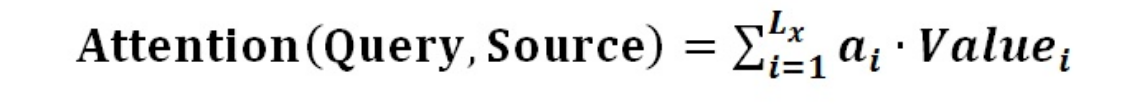
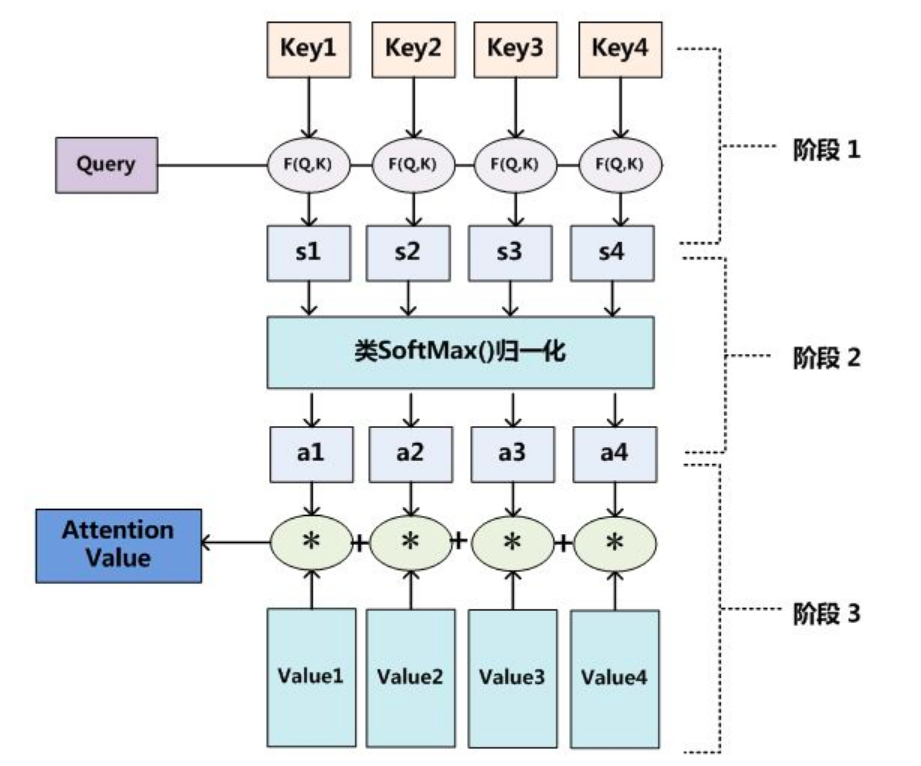
阶段1:Query与每一个Key计算相似性得到相似性评分s
阶段2:将s评分进行softmax转换成[0,1]之间的概率分布
阶段3:将[a1,a2,a3…an]作为权值矩阵对Value进行加权求和得到最后的Attention值
3.4Attention优缺点
优点:
- 速度快。Attention机制不再依赖于RNN,解决了RNN不能并行计算的问题。
- 效果好。效果好主要就是因为注意力机制,能够获取到局部的重要信息,能够抓住重点。
缺点:
- 只能在Decoder阶段实现并行运算,Encoder部分依旧采用的是RNN,LSTM这些按照顺序编码的模型,Encoder部分还是无法实现并行运算,不够完美。
- 就是因为Encoder部分目前仍旧依赖于RNN,所以对于中长距离之间,两个词相互之间的关系没有办法很好的获取。
4 Self-Attention
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,相当于是Query=Key=Value,计算过程与attention一样.

如此引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此之外,Self Attention对于增加计算的并行性也有直接帮助作用。正好弥补了attention机制的两个缺点,这就是为何Self Attention逐渐被广泛使用的主要原因。