本文是对Google2017年发表于NIPS上的论文"Attention is all you need"的阅读笔记.
对于深度学习中NLP问题,通常是将句子分词后,转化词向量序列,转为seq2seq问题.
-
RNN方案
采用RNN模型,通常是递归地进行
yt=f(yt−1,xt),优点在于结构简单,十分适合序列建模;缺点在于需要前一个输出作为后一个的输入参与运算,因此无法并行计算,速度很慢,且单向RNN只能获取前向序列关系,需要采用双向RNN才可以获取完整的全局信息.
-
CNN方案
采用CNN模型,则是通过一个窗口(卷积核)来对整个序列进行遍历,
yt=f(xt−1,xt,xt+1)只能获取到局部信息,需要层叠来增大感受野.
本文提出了一种Transformer注意力机制,完全替代了RNN、CNN.
yt=f(xt,A,B)
将A、B都取为X时,则称为Self-Attention,即通过
xt和整个
X进行关系运算最后得到
yt.
Attention层
Google给出了如下的Attention结构
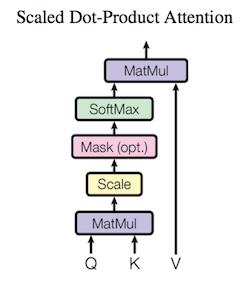
Attention(Q,K,V)=softmax(dk
QKT)V
其中,
dk时
key的维数,
dv是
value的维数,
Q∈Rn×dk,K∈Rm×dk,V∈Rm×dv
当
dk较小时,采用点积和加法注意力机制的效果时相同的,当
dk较大时,点积的效果会下降很多,这是由于
dk较大时,点积产生的值会很大导致
softmax陷入了饱和区,因此这里除以了
dk
.
Yself=Attention(V,V,V)
通过self-attention,可以无视词之间距离直接计算远距离的两个词的依赖关系,从而能学习到整个句子的内部结构,并且相当于进行了句法分析.
Multi-Head Attention
多头注意力机制就是重复进行
h次(参数不共享),即采用不同的参数进行
h次,捕获不同子空间上的相关信息,将最后的结果拼接起来,会产生更好的效果.
MultiHead(Q,K,V)=Concat(head1,…,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)
其中,
WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,WO∈Rhdv×dmodel
Feed-Forward Networks
在encoder和decoder中,除了注意力子层之外还包含一个全连接的前馈网络,含有两个线性变换,并且在两者之间有一个
ReLU激活函数.
FFN(x)=max(0,xW1+b1)W2+b2
相当于两个卷积核大小为1的卷积层.
Positional Encoding
很容易发现,对于两个顺序不同词相同的句子,通过自注意力层最后得到的输出相同的,即这里的自注意力机制并不能捕捉到词之间的顺序关系,仅仅相当于一个词袋模型.
因此Google提出了Position Encoding,为每个词添加位置编码,与词序列作为共同输入.
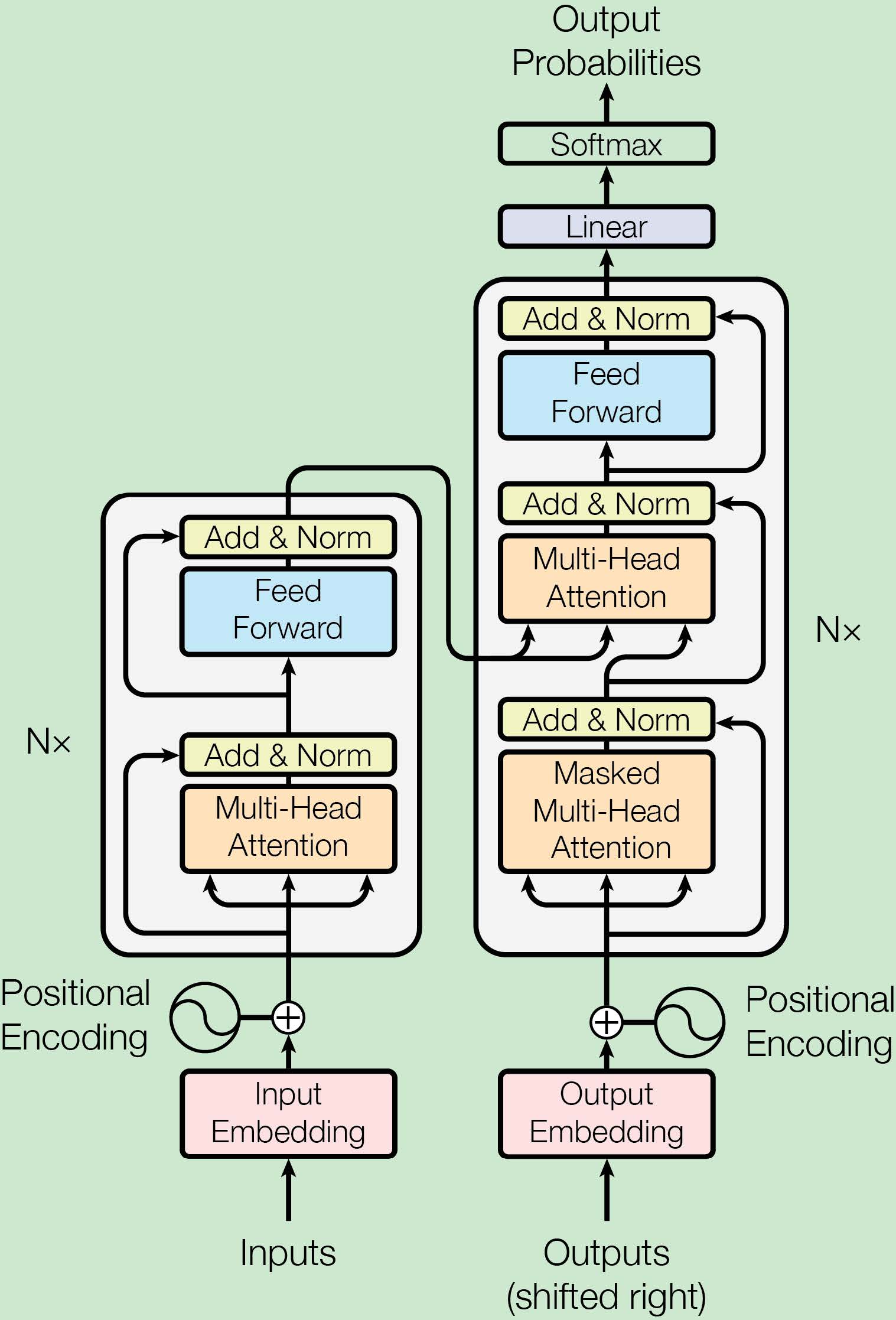
这里采用的运算关系如下:
PE(pos,2i)=sin(100002i/dmodelpos)PE(pos,2i+1)=cos(100002i/dmodelcos)
pos是位置,
i是维度,采用sin函数,对于任意的偏移
k,
PEpos+k都可以描述为
PEpos的线性函数.
自注意力的优势
- 计算复杂度/layer
- 并行计算数量
- 计算远距离依赖关系的路径长度
正则化
- 对于每一子层都采取dropout操作
- 对词序列和位置编码的和进行dropout
其他
- 根据实验结果推测,可能存在一个更复杂的函数要比点积的效果更优.
- 实验验证,学习过的位置嵌入与sin曲线效果相同.
Beam search
在test集上,通过beam search 集束搜索来寻找解. 集束搜索是一种贪心算法,相当于一个约束优化的广度优先搜索,并不能保证一定可以找到最优解.
大致思路如下:
每一次都只寻找代价最低即可能性最大的前
m(称为beams size)个解,直到遇到终止符位置.
参考文献
苏剑林-Attention is all you need 浅读