文章目录
更多源码介绍详见 姊妹篇
1.为什么是attention
正如论文的题目所说的,Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。论文中给出Transformer的定义是:
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
原文有些细节解释的并不是很清楚,但是The Illustrated Transformer 给出了详细的解释,可参阅~
2.分层详解Transformer
下面我们自上而下的对transformer进行分析,这样可以让整体更加清晰~(不至于发出我在哪,我在做了什么,接下来我又要做什么的疑问)
先看一下官方给出的模型结构:
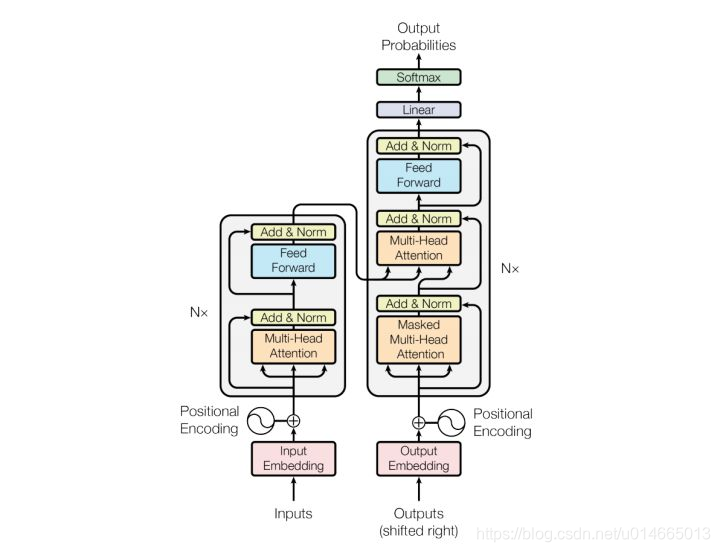
论文中的验证Transformer的实验室基于机器翻译的,下面我们就以机器翻译为例子详细剖析Transformer的结构,在机器翻译中,Transformer可概括为如图1:

其内部的实现Encoder-Decoder结构:
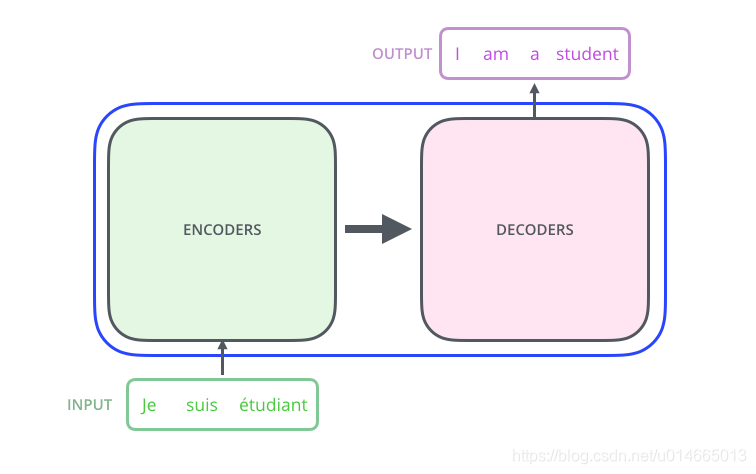
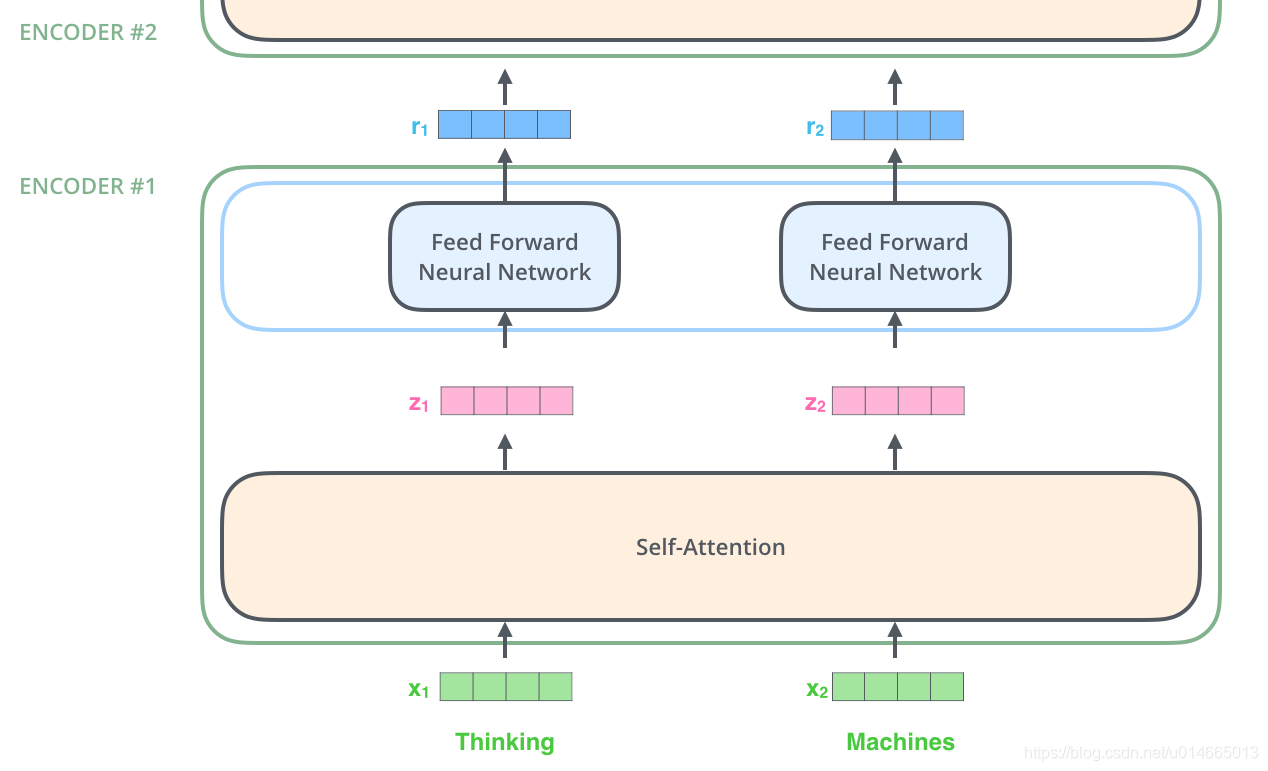
如论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入,这里需要注意的是,encoder的结果作为decoder stack里面每一层的输入:
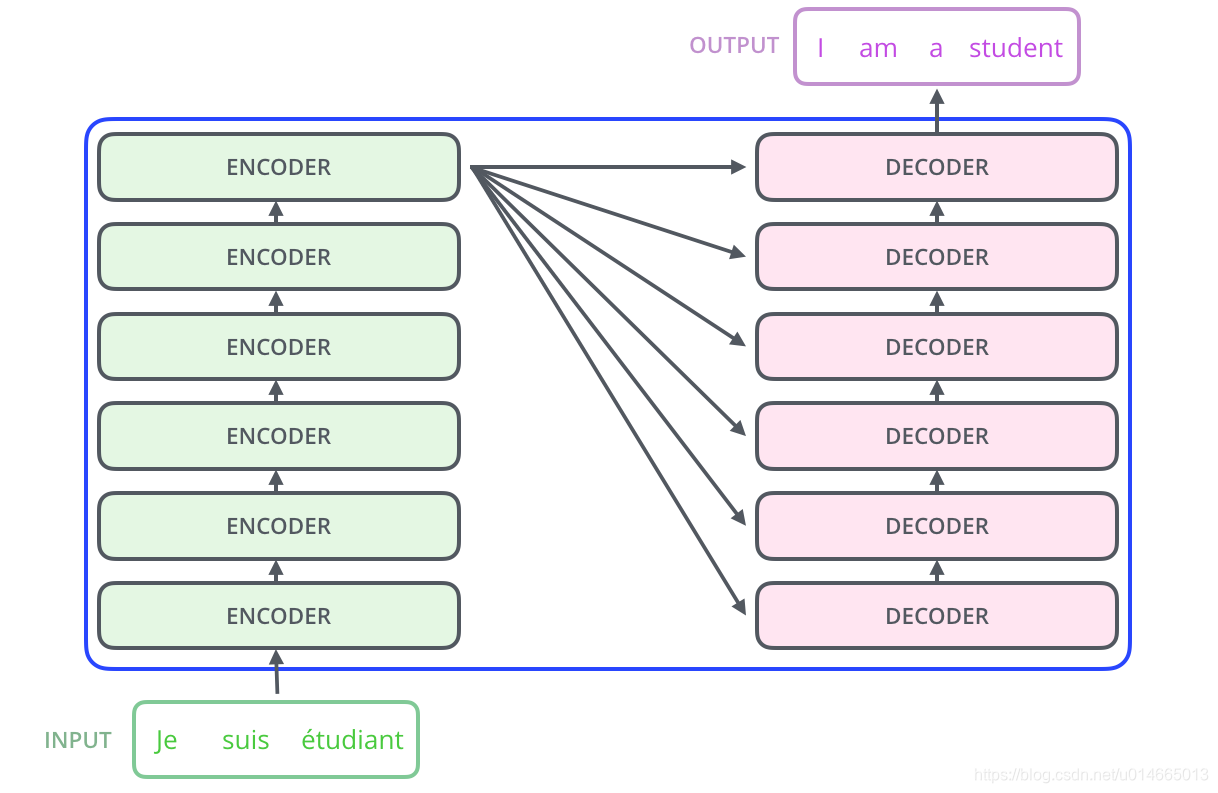
其中encoder的结构如下图所示,这里的Encoder Stack里面的每个Encoder是不共享变量的:
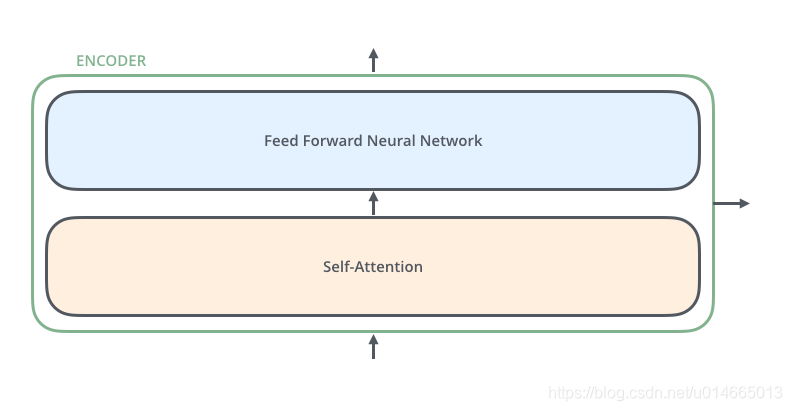
Decoder的结构和encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值:
Self-Attention:当前翻译和已经翻译的前文之间的关系;
Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
最后我们在详细说下Encoder和Decoder的内部细节:
- self-attention:通过该模块得到一个加权之后的特征向量
,这个
便是论文公式1中的
,后面会详解:
- Feed Forward Neural Network,这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
3.向量详解Transformer
3.1.输入向量
上面介绍了Model的各个模块,接下来我们再从Vectors/tensors的角度来详细分解各个模块,明白从输入到输出所经过的各种操作。
首先通过Word2Vec等词嵌入方法将输入语料转化成特征向量,论文中使用的词嵌入的维度为
:

在最底层的block中, x 将直接作为Transformer的输入,而在其他层中,输入则是上一个block的输出。为了画图更简单,我们使用更简单的例子来表示接下来的过程:
3.2.self attention
Self-Attention是Transformer最核心的内容,然而作者并没有详细讲解,下面我们来补充一下作者遗漏的地方。回想Bahdanau等人提出的用Attention[2],其核心内容是为输入向量的每个单词学习一个权重,例如在下面的例子中我们判断it代指的内容:
The animal didn’t cross the street because it was too tired
这里的it指的是什么意思,street还是animal,self-attention 通过查看其他位置的单词,最终得出结论:it指的是animals.
通过加权之后可以得到类似下图的加权情况,在讲解self-attention的时候我们也会使用图8类似的表示方式:

在self-attention中,需要算出每个单词
对应的3个不同的向量,它们分别是Query向量
,Key向量
和Value向量
,长度均是64。那他们是怎么算出来的呢?是由嵌入向量 X 乘以三个不同的权值矩阵
,
,
得到的,其中三个矩阵的尺寸也是相同的,均是
,这样的最后得到的Q K V的维度为sequence_length*64 。
其中
.

这里图片中
,
同理
那么Query,Key,Value是什么意思呢?它们在Attention的计算中扮演着什么角色呢?我们先看一下Attention的计算方法,整个过程可以分成7步:
- 如上文,将输入单词转化成嵌入向量 ;
- 根据嵌入向量得到 三个向量;
- 为每个向量计算一个 向量: ;
- 为了梯度的稳定,Transformer使用了 归一化,即除以 ;
- 对 施以softmax激活函数;
- softmax点乘Value值 v ,得到加权的每个输入向量的评分 v ;
- 相加之后得到最终的输出结果 : (假设句子长度为n)。
可表示如下:
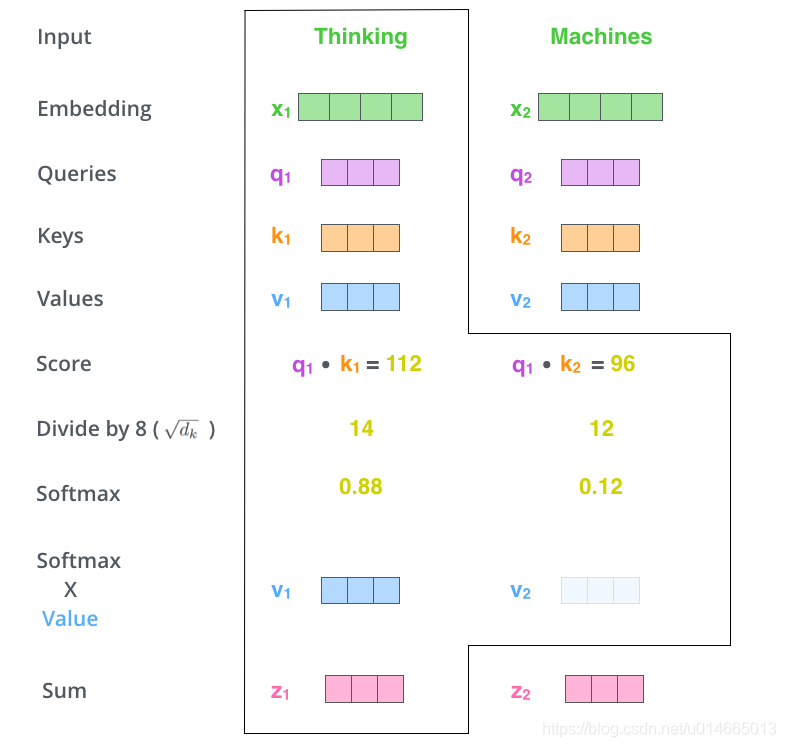
实际计算过程中是采用基于矩阵的计算方式,那么论文中的
,
,
的计算方式如图:

最后self-attention 的公式可以写成如下直观表示:

3.3.Multi-Head Attention
Multi-Head Attention相当于 h 个不同的self-attention的集成(ensemble),该trick提高了模型的效果,主要表现在如下两方面:
- multi head增强了模型focus on不同位置的能力。在上面的例子中,it可能受这个单词本身主导,但是很明显通过多头的方式,可以pay attention to其他的单词(例如animals),从而推断出it代表的意思。
- 通过多头,可以帮助attention layer把输入embedding映射到多个表示空间。

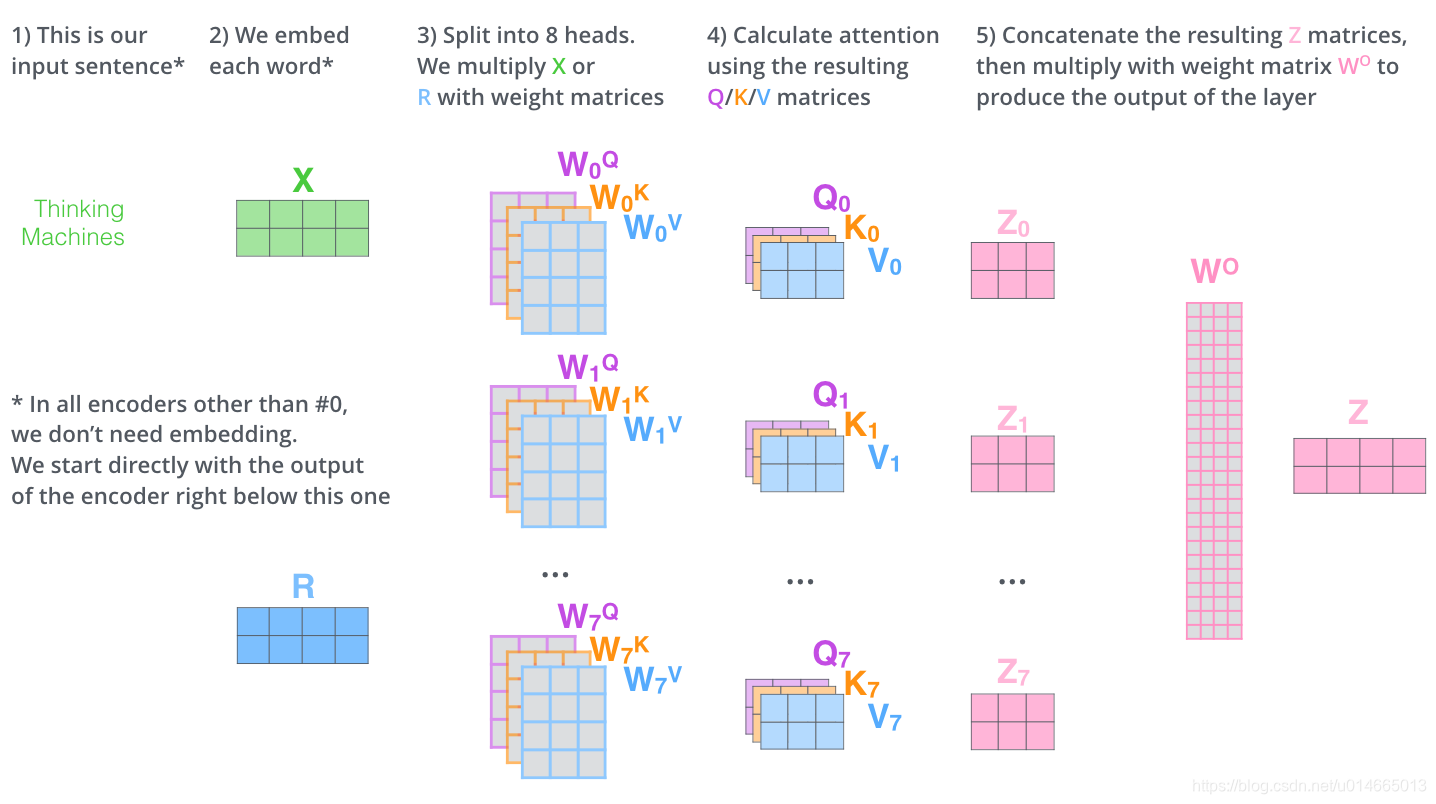
在实际操作的时候,只不过把self-attention操作按照相同的方式重复8遍罢了(原文代码中采用的是8 head):

但是这里的feed-forward layer不希望处理8个matrics,因此解决方法就是先把
…
concat 起来,然后再project一下,最终得到
,如下图:

综上所述,multi head的操作流程可视化如下:
按照multi head的方式,我们再来看之前的例子的attention表示:

As we encode the word “it”, one attention head is focusing most on “the animal”, while another is focusing on “tired” – in a sense, the model’s representation of the word “it” bakes in some of the representation of both “animal” and “tired”.
如果把所有的head都画出来,可能对于人来说,直观上可能已经很难解释了:

3.4.position embedding
到目前为止,因为是翻译的模型,但是模型缺少了words再句子中的位置信息,所以模型增加了position编码,从而提供位置信息。
假如embedding的维度是4,那么可表示如下:

那么我们来看一下如果是长度为20的句子,512的hidden size的position embedding是什么样子的:

再上图中我们可以看到从中间分开了,这是因为左面的value是通过一种函数生成的(sin),而右面的是通过另外一个函数生成的(cos),最后再将他们concat起来,这也是论文code中的实现方案,和论文中的
那作者又为什么要选择这样的函数呢?
- 作者这么设计的原因是考虑到在NLP任务重,除了单词的绝对位置,单词的相对位置也非常重要。根据公式 以及 ,这表明位置 k+p 的位置向量可以表示为位置 k 的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
- 如果是学习到的positional embedding,(个人认为,没看论文)会像词向量一样受限于词典大小。也就是只能学习到“位置2对应的向量是(1,1,1,2)”这样的表示。所以用三角公式明显不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。
3.5.Residuals layer
Transformer中另外一个特点就是在每个sub-layer(self-attention+ffn)之后,都会有一个残差网络,而这个残差是sub-layer前面的一层的输出结果:

到这里,我们可以详细地描述Transformer的结构了:

这里Encoder的最终结果(Encoder_outputs)会传播到Decoder中,在Decoder的self-attention之后(得到Decoder_inputs),再做attention,这次Attention的Q=decoder_outputs(上一层decoders输出,或者target sequence编码),K和V=encoder_outputs
3.6. Decoder中的特点
上面所说的多是针对于Encoder端的,虽然在Decoder端很多操作都与Encoder相同,但是还是有如下的几点不同:
- self-attention:与encoder里面的self-attention略有不同,就是在对output sequence做attention之前只允许看到output sequence的前面位置的信息,具体操作就是在self attention计算之前masking后面的位置。
- Decoder-encoder-attention:Decoder端在self-attention后,还会将该输出和Encoder的输出进行attention
3.7.Final Linear and Softmax Layer
最终的decoder stack输出的是浮点型的向量,那怎么把它变为一个翻译的目标单词呢?这就需要最后的Linear layer以及后面的Softmax Layer了。
假如模型的输出词表大小为10000,那么通过全连接之后,会得到每个单词的相关分数,最后通过softmax,从而得出当前的分值最大的output word:

至此,我们的模型已经讲解的比较详细了,我们来整体动态看一下:

4.源码解读
transformer发布了官方的版本,但是其借助了tensor2tensor的框架,因此其可读性很差,为了增强其扩展性,往往看一个模型,需要深入好多层才能看到真正想看的code,因此这里我详解的是github中tensorflow中的代码,链接:transformer,另外增加了大量注释的小博git
常规trick:
- layernorm
- word embedding 和 layer 中dropout
本篇淫巧
- 对word embedding和position embedding做scale,本文中的具体操作是:
embeddings *= self.hidden_size ** 0.5 - 过dense layer时去除padding的vector,这样可以增大batch size,具体代码详见:详情
- decode时前项mask(不可见),详情
- 在ffn-layer时,采用的是双层dense layer,并且第一层是先将维度扩大,且经过激活函数,然后第二层在将维数还原到原来的维数,且无激活函数。
4.总结
4.1.优点
- 虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
- Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
- Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
- 算法的并行性非常好,符合目前的硬件(主要指GPU)环境
- Attention 虽然跟 CNN 没有直接联系,但事实上充分借鉴了 CNN 的思想,比如 Multi-Head Attention 就是 Attention 做多次然后拼接,这跟 CNN 中的多个卷积核的思想是一致的;还有论文用到了残差结构,这也源于 CNN 网络。
4.2.缺点
- 粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
- Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
参考文献: