目标检测中的Anchor
default box
- SSD 预测 bbox 的做法本质上和 RPN 相同,但它在多个layer(lower and up layer)上进行预测,以更好地在多尺度上检测物体
在多层上预测 bbox
- SSD300
conv4 ==> 38 x 38
conv7 ==> 19 x 19
conv8 ==> 10 x 10
conv9 ==> 5 x 5
conv10 ==> 3 x 3
conv11 ==> 1 x 1
size of reference box
- 每一层都有一个特定大小的 reference box,根据这个 reference box 计算出当前层的 default box(anchor)。reference box 是一个正方形的 box, 大小由 scale 参数决定
- m 为负责预测的layer数量, 是 0.2,最低层(conv4)的 reference box 的 ; 是0.9,表示最高层(conv11)的 eference box 的
- 训练时,输入图片都被 resize 到 300 * 300,这样的话,conv4 上的 reference box 是一个边长为 300 * 0.2 = 60 的正方形
aspect ratios for default boxes
- 得到一个 layer 上的 reference box 大小后,根据该层配置的 aspect ratios,可得到多个不同的 aspect ratio 的 default box(anchor)
faster R-CNN 中的 anchor
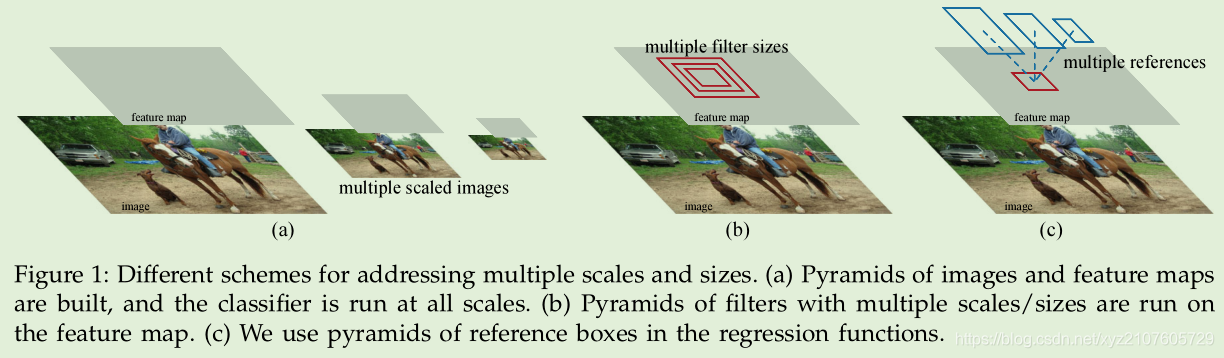
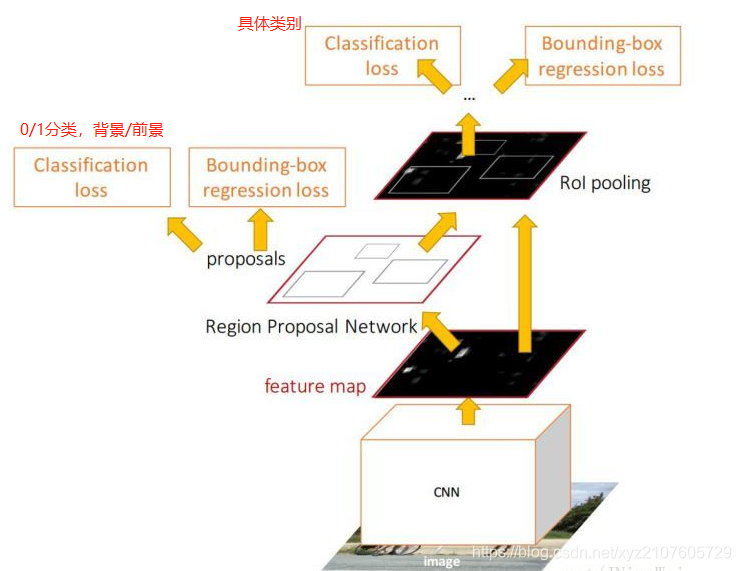
- 以 feature map 的每个cell 为中心,映射到原图中,生成 3 * 3 个不同面积和 比例的 anchor (3 scale,3 ratio) (128,256,512,1:1,1:2,2:1)
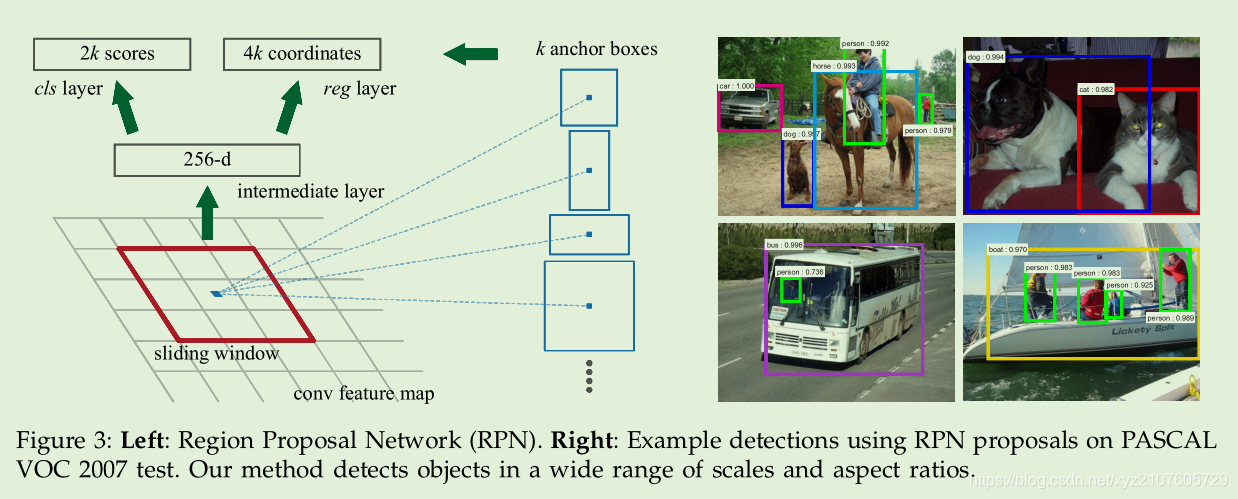
- For a convolutional feature map of a size W × H (typically ∼2,400), there are WHk anchors in total.
- 但是如果只在最后一层 feature map 上映射回原图像,且初始产生的anchor被限定了尺寸下限,那么低于最小anchor尺寸的小目标虽然被anchor圈入,在后面的过程中依然容易被漏检。
[1] : https://blog.csdn.net/u014380165/article/details/72824889 ssd
[2] : https://blog.csdn.net/weixin_35653315/article/details/72288395 default box scale
[3] : https://zhuanlan.zhihu.com/p/55824651 目标检测中的Anchor