——CNN based Anchor-Free Detectors
所有论文综述均保持如下格式:
1、一页PPT内容总结一篇论文
2、标题格式一致:出处 年份 《标题》
3、内容格式一致:针对XX问题;提出了XX方法;本文证明了XXX
4、把握核心创新点,言简意赅
5、开源代码链接
强烈推荐:目标检测论文资源列表(各目标检测网络性能对比、论文链接、官方/非官方代码链接)
https://github.com/hoya012/deep_learning_object_detection#2014
针对Anchor的缺点:
1、对feature map上每一像素点去定义很多的锚点框,导致anchor boxes数量大,正负样本不均衡
2、anchor boxes的使用引入了许多超参数和设计选择,包括多少个box、大小和高宽比,这些超参数使得网络调优变得困难,增加网络复杂度,增大计算量
一、CVPR 2015《DenseBox:Unifying Landmark Localization with End to End Object Detection》
- 针对:将FCN应用到目标检测,人脸检测,车辆检测,密集预测对每个pixel预测
- 提出了:1.直接预测目标框和目标类别;2.通过多任务引入landmark localization,进一步提升性能
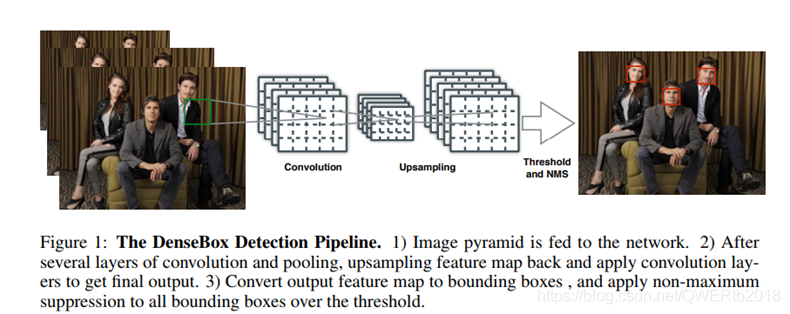
单个FCN同时产生多个预测bbox和置信分数的输出。测试时,整个系统将图片作为输入,输出5个通道的feature map。每个pixel的输出feature map得到5维的向量,包括一个置信分数和bbox边界到该pixel距离的4个值。最后输出feature map的每个pixel转化为带分数的bbox,然后经过NMS后处理。
缺点:使用embeddings进行角点匹配效果不好,导致某个物体左上角匹配到另一个物体右下角
二、ECCV 2018《CornerNet:Detecting Objects as Paired Keypoints》
- 针对:anchor-boxes的缺点:数量大,正负样本不均衡;2.超参数过多
- 提出了:关键点检测,引入corner pooling帮助网络定位角点
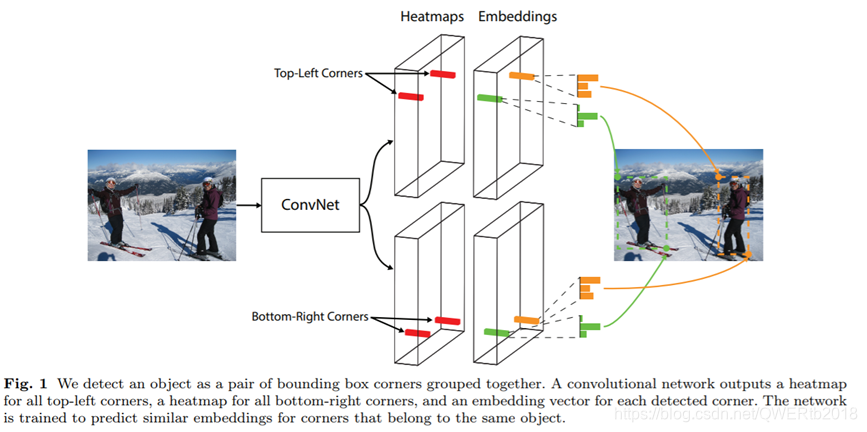
左上角和右下角分别输出三个结果:heatmaps某位置是角点的概率、offsets实际角点相对于该位置的偏移、embeddings嵌入向量,角点配对 - 本文证明了:基于关键点检测的方法是有效的,但物体的特征一般集中在物体内部,左上、右下两个点的特征并不明显,不容易确定位置。
三、CVPR 2019《CenterNet:Keypoint Triplets for Object Detection》
- 针对:CornerNet的角点配准问题
- 提出了:引入“cascade corner pooling”和“center pooling”,从左上角和右下角收集的信息并在中心区域提供更多可识别的信息
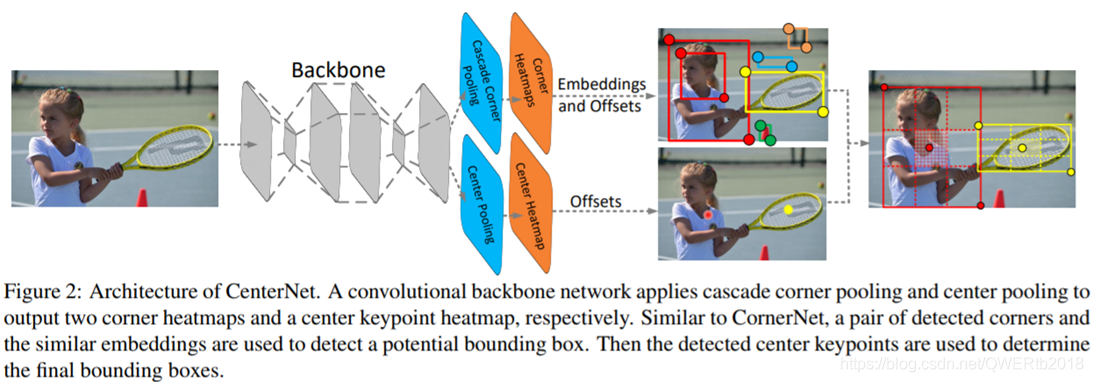
- 本文证明了:通过CornerNet中一对角点生成一个proposal后,通过检验是否有一个具有相同类别的中心点落在中心区域,来判定这个proposal是否真的是一个对象。
四、CVPR 2019《ExtremeNet:Bottom-up Object Detection by Grouping Extreme and Center Points》
- 针对:矩形表示目标会产生干扰背景信息,破坏物体本身信息(形状、姿态)
- 提出了:关键点估计,包括目标的4个极值点和1个中心点组成目标框

检测流程:通过预测每个对象类别的4个heatmaps,得到4个极值点,再利用center heatmap检测中心极值点,匹配算法对所有极值点进行组合,并验证组合中是否存在中心极值点。 - 本文证明了:关键点组合方式:CornerNet使用associative embedding将属于同一物体的两点组合,本文通过暴力枚举,利用几何分布组合。不同于CornerNet角点形成bounding box的生成方式,角点通常在真正物体的外部,没有很强的外观特征;而本文选取的中心点和物体边界极值点,存在于物体表面表面,更容易检测。
五、2019《CenterNet:Objects as Points》
- 针对:大多目标检测器枚举所有可能的目标位置并分类是低效、浪费的、需额外后处理;cornernet角点匹配不准
- 提出了:将目标视为一个点(目标bounding box中心点)2.CenterNet基于关键点估计网络,端到端的较bounding box更优,找到目标中心,然后回归到其他属性:尺寸、3D位置、方向、姿态。无需任何后处理(NMS)。3.将图像传入网络,得到一热力图,热力图峰值点即中心点,每个特征图的峰值点位置预测了目标的宽高信息

创新点:1.分配的锚点仅在位置上,无尺寸框,无手动设置的阈值做前后景分类(像Faster RCNN将GT IOU>0.7作为前景,<0.3作为背景)
2.每个目标仅一个锚点,无需NMS,提取关键点特征图上的局部峰值点
3.CenterNet相较传统目标检测,缩放16倍,使用更大分辨率的输出特征图(缩放4倍),无需多重特征图锚点
3D bbox检测:直接回归得到目标的深度信息,3D框的尺寸,目标朝向(中)
人体姿态估计:将2D point位置作为中心点的偏移量,直接在中心点位置回归出偏移量的值(下)
- 本文证明了:NMS通过计算bbox间的IOU来删除同个目标的重复检测框,这种后处理很难区分和训练,因此现有大多检测器都非端到端可训练的。
六、ICCV 2019《FCOS: Fully Convolutional One-Stage Object Detection》
- 针对:全卷积网络用语义分割的思想来解决像素点的检测问题
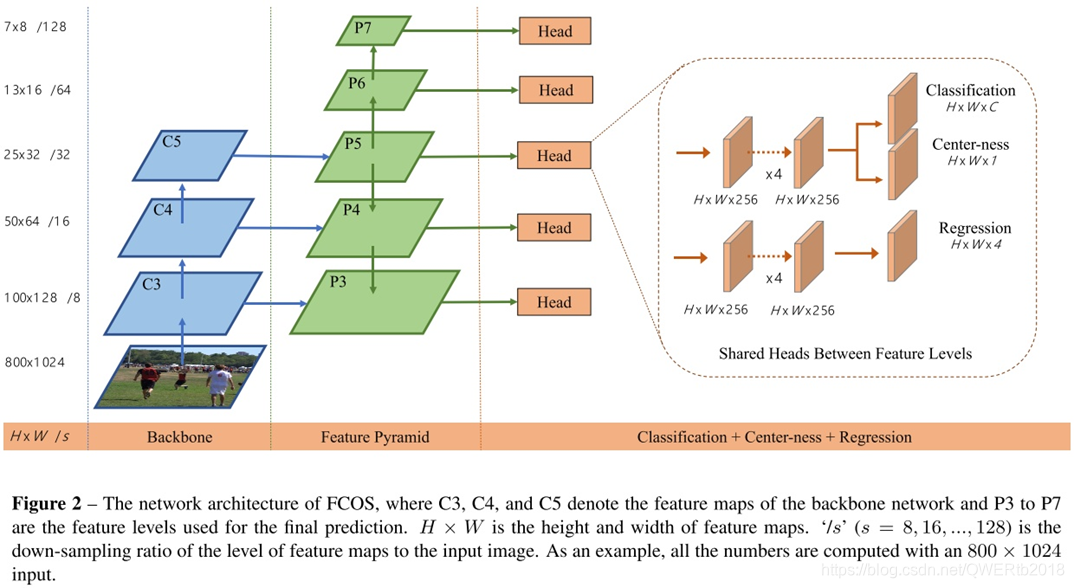
- 提出了:远离目标中心的低质量预测bbox,提出添加center-ness分支,和分类分支并行

GitHub官方源码(PyTorch)
七、2019《FoveaBox: Beyond Anchor-based Object Detector》
- 针对:视觉系统在识别物体和确定边界时,通过眼球中对物体中心感应最敏锐的中央凹(Fovea)结构确定物体位置
- 提出了:预测对象中心区域可能存在的位置以及每个有效位置的边界框,目标中央凹(fovea)只编码目标对象存在的概率,为确定位置,模型要预测每个潜在实例的边界框
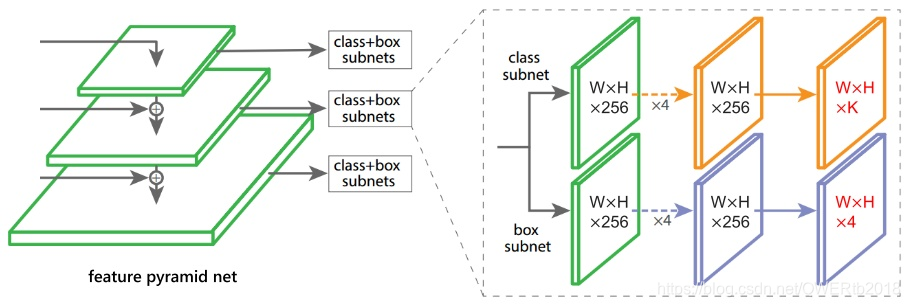
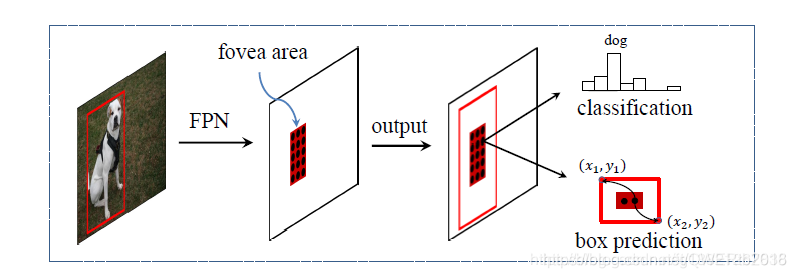
- 本文证明了:FoveaBox借鉴语义分割思想,对物体上的每个点都预测一个分类结果,物体边框通过预测偏移量得到
推荐商汤和香港中文开源的 mmdetection 目标检测工具箱,这也是很多目标检测竞赛首选框架,当前版本也包含了fcos、foveabox配置模块。
八、CVPR 2019《Feature Selective Anchor-Free Module for Single-Shot Object Detection》
- 针对:模型自动学习选择合适的feature去做预测
- 提出了:FSAF模块
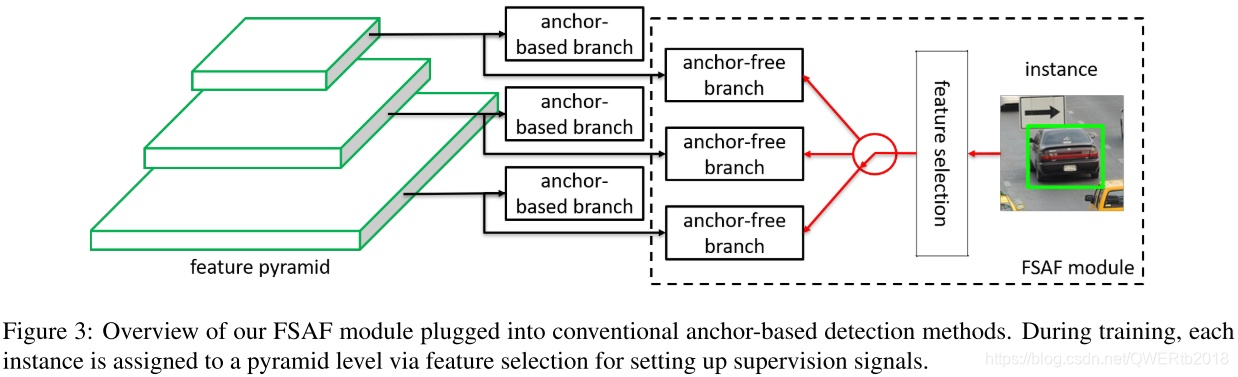
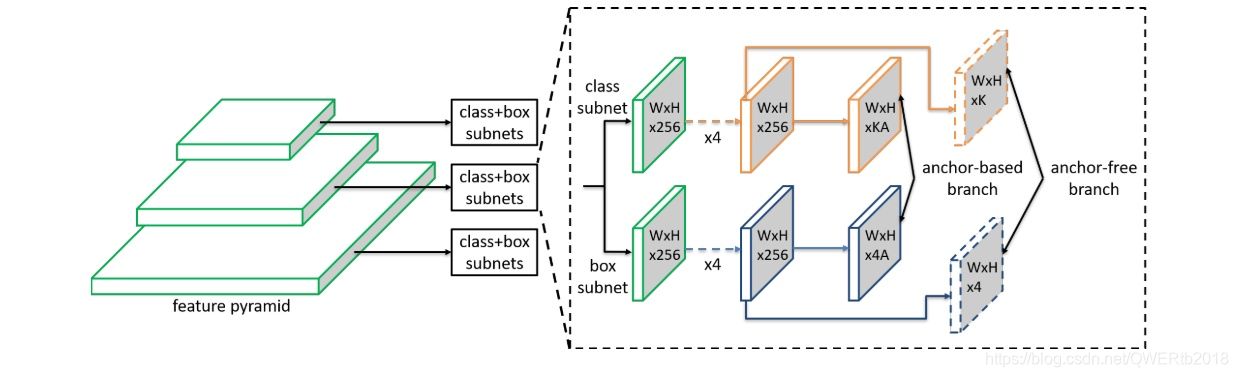
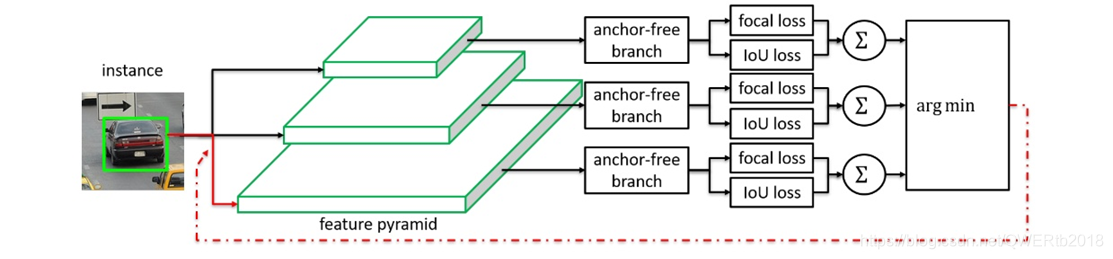
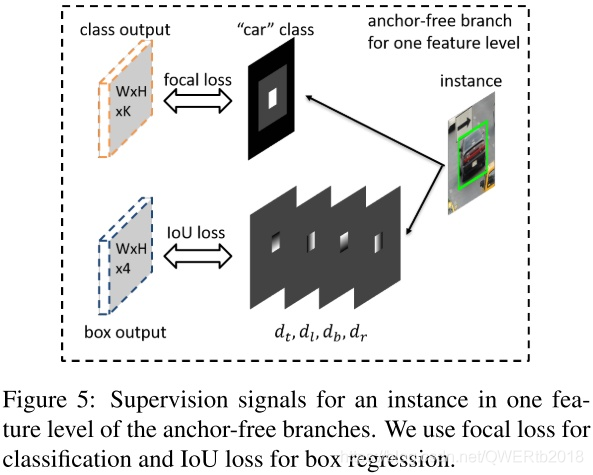
- 本文证明了:自动选择最佳feature的目的,由各个feature level共同决定,计算focal loss和IoU loss的和选择loss和最小的特征层学习。
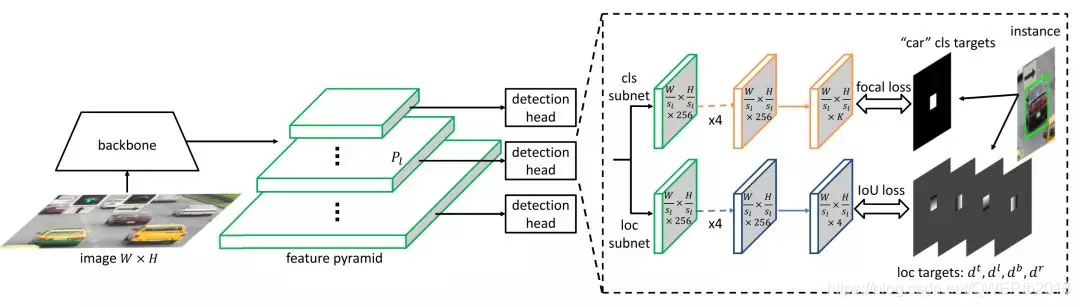
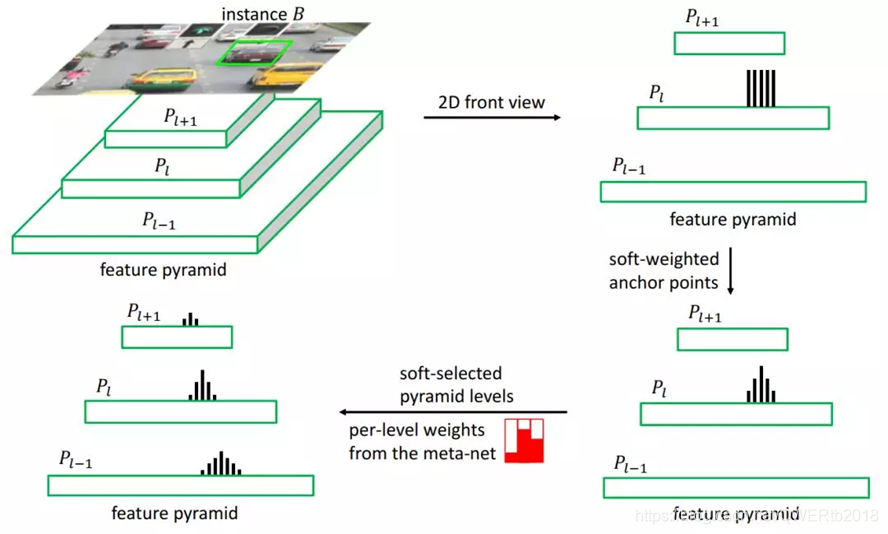
九、2019.11《SAPD:Soft Anchor-Point Object Detection》
-
针对:为anchor-free检测器寻找FPS和mAP的trade-off
-
提出了:1.如何使目标检测的head更好;2.如何更好地利用特征金字塔的特征
-
本文证明了:针对以上问题(注意力偏差attention bais和特征选择)提出一新的训练策略来解决这些问题,该策略有两种soften优化方法:soft-weighted anchor points和soft-selected pyramid levels
-
基于关键点估计的目标检测方法总结
相同点:CornerNet、CenterNet、ExtremeNet对Ground Truth都定义为关键点,区别在于:
1.CornerNet将bbox的两个角点作为关键点
2.ExtremeNet检测所有目标的四个极值点(最顶部、最左侧、最底部、最右侧)和一个中心点;均需经一关键点grouping阶段,降低算法速度
3.CenterNet仅提取目标中心点,无需对关键点进行grouping或后处理。 -
FCOS、FSAF、FoveaBox方法总结
相同点:都利用FPN进行多尺度目标检测;都将分类和回归解耦成两个子网络来处理;都是通过密集预测进行分类和回归的
不同点:FSAF和FCOS的回归预测的是到4个边界的距离,而FoveaBox的回归预测的是一个坐标转换
FSAF通过在线特征选择的方式,选择更加合适的特征来提升性能;FCOS通过center-ness分支剔除掉低质量bbox来提升性能;FoveaBox通过只预测目标中心区域来提升性能。
二、说明
- 博客内容只是总结每篇论文的主要创新点,针对什么问题,提出了什么方法,没有翻译论文,也没有详细阐述论文中提出的网络结构,实验方法。原因在于:网上有很多关于各种论文的详细翻译、理解,但读者很难集中时间去消化理解每一篇论文内容,往往都是看完一篇过几天就忘记了,所以本文采用这种总结方式,简洁明了,使其对基于Anchor-Free的目标检测网络有一整体的认识。
- 以上内容均基于本人看论文的理解,可能在某些总结上存在错误或者理解不够,恳请大家能在留言提出来,我会及时修改,我希望通过写博客的方式,加深对论文的理解,并期望得到提高,谢谢大家!
