Bridng the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
发表于CVPR 2020
The paper is https://arxiv.org/abs/1912.02424
The code is available at https://github.com/sfzhang15/ATSS
摘要:
first point out that the essential difference between anchor-based and anchor-free detection is actually how to define positive and negative training samples, which leads to the performance gap between them.
propose an Adaptive Training Sample Selection (ATSS) to automatically select positive and negative samples according to statistical characteristics of object. It significantly improves the performance of anchor-based and anchor-free detectors and bridges the gap between them.
Extensive experiments conducted on MS COCO support our aforementioned analysis and conclusions. With the newly introduced ATSS, we improve stateof-the-art detectors by a large margin to 50.7% AP without introducing any overhead.
2. Related work
Anchor-based Detector
一阶段方法。随着SSD的出现[36],基于锚的单级检测器由于其高计算效率而备受关注。 SSD在ConvNet的多尺度层上分布锚框,以直接预测对象类别和锚框偏移。此后,提出了许多工作来提高其在不同方面的性能,例如融合来自不同层的上下文信息[24、12、69],从头开始训练[50、73],引入新的损失函数[33、6],锚点细化和匹配[66,67],架构重新设计[21,22],特征丰富和对齐[35,68,60,42,29]。目前,基于一级锚的方法可以以更快的推理速度与基于二级锚的方法实现非常接近的性能。
两阶段方法。 Faster R-CNN [47]的出现确立了两阶段基于锚的探测器的主导地位。更快的R-CNN由一个单独的区域提议网络(RPN)和一个区域预测网络(R-CNN)[14、13]组成,用于检测物体。之后,提出了许多算法来提高其性能,包括体系结构重新设计和改革[4、9、5、28、30],上下文和注意力机制[2、51、38、7、44],多尺度训练和测试。 [54,41],训练策略和损失函数[40,52,61,17],特征融合和增强[25,32],更好的建议和平衡[55,43]。时至今日,仍通过两阶段基于锚的方法在标准检测基准上保持最先进的结果。
Anchor-free Detector
基于关键点的方法。这种无锚方法首先定位几个预定义或自学习的关键点,然后生成边界框以检测对象。 CornerNet [26]将对象边界框检测为一对关键点(左上角和右下角),CornerNet-Lite [27]引入了CornerNet-Saccade和CornerNet-Squeeze以提高其速度。网格R-CNN的第二阶段[39]通过预测具有FCN位置敏感性优点的网格点,然后确定由网格引导的边界框来定位对象。 ExtremeNet [71]检测四个极端点(最顶部,最左侧,最底部,最右侧)和一个中心点以生成对象边界框。朱等[70]使用关键点估计来找到对象的中心点,并回归到所有其他属性,包括大小,3D位置,方向和姿势。 CenterNet [11]将CornetNet扩展为三元组而不是一对关键点,以提高准确性和召回率。 RepPoints [65]将对象表示为一组采样点,并学习以限制对象空间范围并指示语义上重要的局部区域的方式安排自身。
基于中心的方法。这种无锚方法将对象的中心(例如中心点或部分)作为前景来定义正值,然后预测从正值到对象边界框的四个侧面的距离以进行检测。 YOLO [45]将图像划分为S×S网格,并且包含对象中心的网格单元负责检测该对象。 DenseBox [20]使用位于对象中心的实心圆定义正值,然后预测从正值到对象边界框边界的四个距离。 GA-RPN [59]将对象中心区域中的像素定义为正数,以预测Faster R-CNN的对象建议的位置,宽度和高度。 FSAF [72]将具有在线功能选择的无锚分支附加到RetinaNet。新添加的分支将对象的中心区域定义为正值,以通过预测到其边界的四个距离来定位该对象。 FCOS [56]将物体边界框内的所有位置视为具有四个距离的正值,并以新颖的中心度得分检测物体。 CSP [37]仅将对象框的中心点定义为正,以检测具有固定长宽比的行人。 FoveaBox [23]将物体中间的位置视为具有四个距离的正值进行检测。
3. Difference Analysis of Anchor-based and Anchor-free Detection
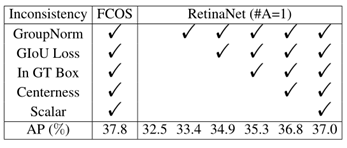
在不失一般性的前提下,采用具有代表性的基于锚的RetinaNet [33]和无锚的FCOS [56]来剖析它们之间的差异。在本节中,关注最后两个差异:正/负样本定义和回归开始状态。剩下的一个区别是:每个位置平铺的锚点数量,将在后续部分中讨论。因此,只需为RetinaNet每个位置平铺一个方形锚,这与FCOS非常相似。接着,先介绍实验设置,然后排除所有实现上的不一致之处,最后指出基于锚点的检测器与免锚检测器之间的本质区别。
数据集。所有实验都是在MS COCO [34]数据集上进行的,该数据集包括80个对象类。
训练细节。使用 ImageNet 上预训练的 ResNet-50 作为主干网络,它有5个层级的特征金字塔结构。对于RetinaNet,5个特征金字塔中的每一个网络层都有1个正方形 anchor,它有 8S个尺度,S是总共的步长大小。在训练时,将输入图片重新缩放,保证短边长度为800,长边小于或等于1333。整个网络通过 SGD 来训练,momentum 为0.9,weight decay 为0.0001,batch size 为16,9万次迭代。初始学习率为0.01,在6万次和8万次迭代时分别除以10。
推理细节。在推理阶段,以与训练阶段相同的方式调整输入图像的大小,然后将其转发到整个网络,以输出具有预测类的预测边界框。之后,使用预设分数0.05过滤掉大量背景边界框,然后输出每个要素金字塔的前1000个检测结果。最后,对非最大抑制(NMS)应用每个类的IoU阈值0.6,以生成每个图像最终的前100个置信检测。
Inconsistency Removal
Essential Difference
基于锚点的RetinaNet(#A = 1)和无锚点FCOS之间的两个区别。一种是关于检测中的分类子任务,即定义正样本和负样本的方法。另一个与回归子任务有关,即,从锚点框或锚点开始的回归。
分类:
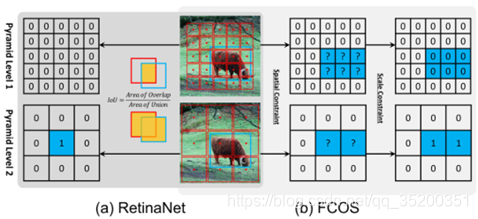
正(1)和负(0)的定义。蓝框,红框和红点是GT,锚点框和锚点。(a)RetinaNet使用IoU同时选择空间和尺度维度上的正数(1)。(b)FCOS首先在空间维度上找到候选正值,然后在比例维度上选择最终的正值(1)。
RetinaNet使用IoU阈值(theta_p,theta_n)来区分正负anchor box,处于中间的全部忽略。FCOS使用空间尺寸和尺寸限制来区分正负anchor point,正样本首先必须在GT内,其次需要是GT尺寸对应的层,其余均为负样本。
回归:
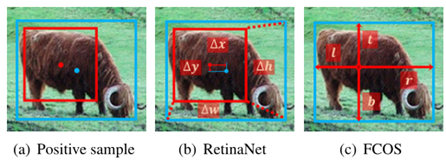
(a) 蓝点和框是对象的中心和边界,红点和框是锚点的中心和边界。(b) RetinaNet从锚框回归四个偏移量。© FCOS从锚点回归四个距离。
结论。一阶段基于锚的探测器与基于中心的无锚探测器之间的本质区别实际上是如何定义正训练样本和负训练样本,这对于当前的物体检测非常重要。
4. Adaptive Training Sample Selection

对于每个GT g,先在每个特征层找到中心点最近的k个候选anchor boxes(非预测结果),计算候选box与GT间的IoU D_g,计算IoU的均值m_g和标准差v_g,得到IoU阈值t_g=m_g+v_g,最后选择阈值大于t_g的box作为最后的输出。如果anchor box对应多个GT,则选择IoU最大的GT。
根据锚框和对象之间的中心距离选择候选对象
对于RetinaNet,当锚框的中心靠近对象中心时,IoU会更大。对于FCOS,靠近对象中心的锚点将产生更高质量的检测。因此,越靠近对象中心的锚点越好。
使用平均值和标准偏差之和作为IoU阈值
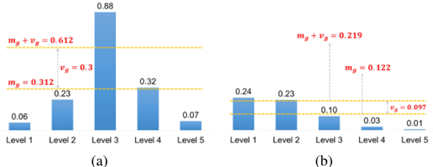
每个级别的IoU都有一个候选。a)具有高m_g和高v_g的GT。b)低m_g低v_g的GT。
均值m_g表示预设的anchor与GT的匹配程度,均值高则应当提高阈值来调整正样本,均值低则应当降低阈值来调整正样本。标准差v_g表示适合GT的FPN层数,标准差高则表示高质量的anchor box集中在一个层中,应将阈值加上标准差来过滤其他层的anchor box,低则表示多个层都适合该GT,将阈值加上标准差来选择合适的层的anchor box,均值和标准差结合作为IoU阈值能够很好地自动选择对应的特征层上合适的anchor box。
将正样本的中心限制为对象
具有中心外部对象的锚点是较差的候选对象,并且将由对象外部的特征进行预测,这不利于训练,应将其排除在外。
维护不同对象之间的公平性
根据统计理论,理论上大约有16%的样本位于置信区间[mg + vg,1]中。尽管候选者的IoU不是标准正态分布,但统计结果表明,每个对象都有大约0.2 * kL个正样本,其大小,纵横比和位置均不变。相比之下,RetinaNet和FCOS的策略往往对较大的对象具有更多的正样本,从而导致不同对象之间的不公平。
保持几乎没有超参数
本方法只有一个超参数k。随后的实验证明,它对k的变化非常不敏感,提出的ATSS可以认为几乎没有超参数。