版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ybdesire/article/details/82860607
引入
无论是基于滑动窗口,还是基于网格YOLO的目标检测算法,都有可能存在同一个问题:有可能一个BOX中有多个目标,如下图所示:
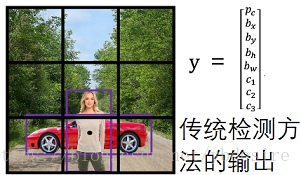
这样的图中,行人和车同时存在,并且他们的中心位置都位于同一个网格中。这种情况下,传统检测方法的输出,就无法胜任了。怎么解决这个问题呢?
Anchor Box算法
对于这个例子,我们引入Anchor Box,如下图所示,我们这里只用两个Anchor Box,说明同一个网格中最多可能存在两类物体。Anchor Box的个数与每个网格中可能出现的最多物体数量相同,也就是Y值的标注需要标注的物体个数。实际项目中,会用更多的Anchor Box。如下图:
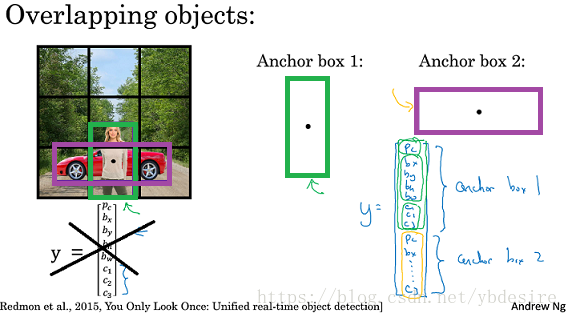
图中用了两个Anchor Box,所以Y值的标注,就需要标注两类物体(标注的成本是升高的)。Y值中:
- pc:网格中是否含有目标对象
- bx:目标对象中心点的x坐标
- by:目标对象中心点的y坐标
- bh:目标对象的高度
- bw:目标对象的宽度
- c1,c2,c3:目标对象的类别
可见,标注中,Y值中的每个参数,都是由0/1组成的。对于本文这个例子,Y值的输出为:3x3x8x2。其中3x3是图像上的网格大小,8是每个对象的输出,2说明用了两个Anchor Box。
总结
Anchor Box的概念,是为了解决同一个网格中有多个目标对象的情况。现实情况中,你的网格划分越细,比如将3x3的网格变为10x10,这种同一个网格中有多个目标对象的情况就越少。
参考
AndrewNG的deep learning