目标检测系列:
目标检测(object detection)系列(一) R-CNN:CNN目标检测的开山之作
目标检测(object detection)系列(二) SPP-Net:让卷积计算可以共享
目标检测(object detection)系列(三) Fast R-CNN:end-to-end的愉快训练
目标检测(object detection)系列(四) Faster R-CNN:有RPN的Fast R-CNN
目标检测(object detection)系列(五) YOLO:目标检测的另一种打开方式
目标检测(object detection)系列(六) SSD:兼顾效率和准确性
目标检测(object detection)系列(七) R-FCN:位置敏感的Faster R-CNN
目标检测(object detection)系列(八) YOLOv2:更好,更快,更强
目标检测(object detection)系列(九) YOLOv3:取百家所长成一家之言
目标检测(object detection)系列(十) FPN:用特征金字塔引入多尺度
目标检测(object detection)系列(十一) RetinaNet:one-stage检测器巅峰之作
目标检测(object detection)系列(十二) CornerNet:anchor free的开端
目标检测扩展系列:
目标检测(object detection)扩展系列(一) Selective Search:选择性搜索算法
目标检测(object detection)扩展系列(二) OHEM:在线难例挖掘
目标检测(object detection)扩展系列(三) Faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3在损失函数上的区别
简介:anchor free的开端
过去的目标检测算法,two-stage方法从Faster R-CNN开始,one-stage方法从SSD开始,都无一例外的引入了anchor,anchor先验的引入使网络不需要从0直接预测Bounding box,这有利于目标检测器得到更好的效果。但是随着Anchor box的逐渐增多,它变成了目标检测算法的一个瓶颈,而CornerNet首次弃用了anchor box,就像它的名字一样,它将目标物体转化为检测左上角和右下角的点,CornerNet的论文是《CornerNet: Detecting Objects as Paired Keypoints》。
CornerNet原理
设计理念
CornerNet的出发点和RetinaNet是同一个,对于one-stage的目标检测器,大量的anchor导致正负样本的不平衡,网络训练时loss会被大批量负样本所左右。同时又由于检测器是one-stage的,一旦预设了anchor,没办法二次筛选它。所以RetinaNet提出了Focal loss,在计算损失时弱化负样本的影响。而CornerNet则是直接弃用了anchor,除了上面的原因,还有一个就是anchor的设计是完全先验的,有大量的超参数,比如如何选择尺度,比例,多少个分支等等,每个层放几个等等,每个结构都不一样。
CornerNet受到人体姿态估计方法的启发,将目标检测问题转化为预测目标边界框的左上角和右下角一对顶点,也就是使用单一卷积模型生成热点图和嵌入式向量,里面的很多部分参考了《Associative Embedding:End-to-End Learning for Joint Detection and Grouping》。

网络需要输出两个Heatmap和一个embedding vector,一个Heatmap上包含了所有目标的左上角点,另一个Heatmap上包含所有目标的右下角点,embedding vector则负责预测这一堆左上角点和右下角点,哪两个应该是一对。
为什么选择角点预测
在CornerNet前的所有方法去定义Bounding Box的时候都是选择中心点和宽高,这种方式利于特征图生成的anchor去编码ground truth。但是CornerNet选择使用左上角和右下角去定义Bounding Box,原因有两个:
- 中心点相比左上角和右下角的点更难定义,因为中心点需要先确定四条边,但是角点不是这样,它只需要两条边,分别是到最右和最下的距离;
- 角点的选择对于空间的离散化是更高效的,因为只需要 个点就可以表达 个格子。意思是说,对于一个 的特征图来说,其中的任意一个点作为中心去选择box,都有 种可能性,而 的特征图上有 个点,所以表达了 个格子。
如何检测角点
网络最后会输出两个heatmap,heatmap的尺寸为
,其中C是目标的类别数,背景类不作为一个类别。两个heatmap分别负责左上角的点和右下角的点,它是一个二值的mask特征图,这两个heatmap上的包含了目标检测任务需要的大部分信息了,原始图像上各个目标的点,会根据目标类别不同反映到heatmap不同通道的前景上。
因为ConerNet就是在参考人体姿态估计的方法,输出的heatmap就是类似下图中蓝色的热力图,下图是Hourglass Network的示例图,只是ConerNet把它换成了左上角和右下角。

heatmap是一个二值的mask,所以这其实是个二分类问题,ground truth在heatmap上只是一个点,而其余所有的点都应该是负样本,对于任意的负样本,训练时的惩罚应该是一致的。但是在CornerNet没有这样来用,因为这个点如果和ground truth偏移的不多,那么两个点连起来的Box还是可以和ground truth有很大的overlaps。
CornerNet以ground truth点为中心的选择了一个圆,这个圆的半径选择依据时,圆内的点连起来的矩形应该可以与ground truth至少有0.3的IOU。就像下图,红色框是实际的目标Bbox,橙色是一个圆,在圆内两点连起来的绿色框依然和红色框有很大的交叠。

这样确定出来圆的半径之后,越是靠近圆心位置的点,惩罚就应该越小,相反的应该越大。并且一个点有
两个值,如果想用二分类问题来解决这个点的训练,需要将它映射为一个值。
基于上面两点考虑,CornerNet选择使用一个高斯分布,标准差为半径的
,映射heatmap上的点
:
heatmap的损失参考了focal loss,并在此基础上加上了高斯映射,因为半径的设计是一个局部效果,所以命名为variant of focal loss,最后的loss为:

其中的C是类别数目,然后遍历W和H,它和focal loss的区别就在负样本时的那个系数
,越是靠近圆心grounth truth的点,
就越是趋近于0,相反的惩罚就越大。
那么最后,如果是“圆”外面的点,结果会怎样,这个就是标准差选取的作用,这样的标准差选取遵循
原则,保证了在半径范围的值占到高斯分布的99%以上,而半径外的点,高斯映射后无限趋近于0,所以对于圆外面的点惩罚是1。
如何预测offset
CornerNet的另一个输出是offset,CornerNet预测的点是在特征图上,特征图是在原图上成倍数的下采样得到的,但是在特征图上的像素点只能是整数,这样就会带来精度的丢失,offset就是补偿这个精度用的,offset的计算是这样:
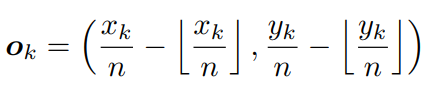
是实际做除法计算出来的小数,
是取整之后的结果,offset的预测使用的是smooth L1 Loss:
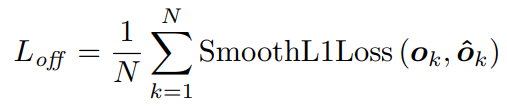
这个loss只用于ground truth的点。
如何配对角点
上面说到heatmap有两个,原图中有很多目标的话,那么两张heatmap上就有多个点。这些点中哪两个应该是一对?
CornerNet还是借鉴了上文姿态估计的方法,引入嵌入式向量。Associative Embedding论文将嵌入式向量应用到判别哪些关键点是属于同一个人的,它也同样适用于判定是否为同一目标。模型在训练阶段为每个corner预测相应的embedding vector,通过embedding vector使同一目标的顶点对距离最短,既模型可以通过embedding vector为每个顶点分组。
其实这个所谓的embedding vector就可以理解为一个值,它和角点是一一对应的,我们为了配对两张heatmap上的角点需要两个条件:
- 同一个object的角点,embedding vector应该尽量小
- 不同object的角点,embedding vector应该尽量大
为了做到上面的目的,CornerNet使用了两个损失,
和
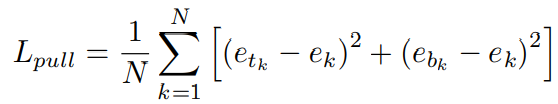
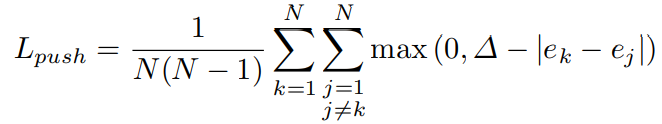
在
中,k代表object,
代表第k个object的左上角点的embedding vector,
代表第k个object的右下角点的embedding vector,
是它们的平均值,所以
的目的是拉近原本就属于一个object的点。但是这还不够,所以的object点的embedding vector都一致,那距离也很近。但是显然这样就什么都分不出来了,所以还需要
来拉开不同object之间的距离,
和
是两个不同目标的embedding vector平均值,在实验中
,所以这个loss是让
和
的差的绝对值怎么也要比1大。
同样的,这两个loss只用于ground truth的点。
Corner Pooling和沙漏网络
为了适应角点检测任务,CornerNet提出了Corner Pooling,虽然这里叫Pooling,但是它不负责下采样,只负责信息的聚合。

对于目标,它的左上角和右下角的点其实没有什么特征,它只是矩形两个边的交点而已,反而是这个矩形的上边由帽子决定,矩形的左边由手部决定。所以Corner Pooling做聚合的目的是找到行列上最具有特征的那个点。
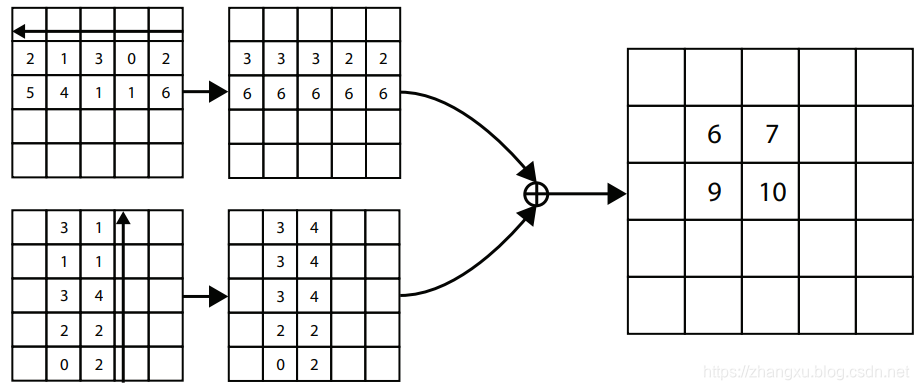
以左上角点输出为例,Corner Pooling需要两个支路一个支路从最右像最左找最大值,一个支路从最下像最上找最大值,最后把这两个支路的输出加起来。因为我们先验的认为,在上面的例子中,水平方向的最大值应该在帽子的顶部,垂直方向的最大值在右手处。
CornerNet的主干模型是Hourglass Network(沙漏网络),这个也是参考了Associative Embedding论文,沙漏网络是做姿态估计任务中很常见的结构,而且在一些人脸landmark任务中也常看到,CornerNet的主干中是使用的s=2的卷积下采样操作。连续堆叠了2个这样的模块。hourglass结构可以很好的结合局部特征和全局特征。最终feature map被缩小5倍。其中卷积层的通道数分别为(256; 384; 384; 384; 512)。hourglass结构的网络深度为104层。

组合上面五个部分,最终CornerNet的结构是这样。
CornerNet性能评价

上图在说明Corner Pooling对于CornerNet的影响,当使用Corner Pooling时AP可以提升2.0。

上图在说明角点预测时适应的惩罚策略对于CornerNet的影响,如果完全移除,也就是对于所有的负样本都是相同的惩罚,AP是最低的;当使用固定的半径时,AP可以提升;使用目标相关的半径选择时,AP最高。

上图在说明沙漏网络和Corner方法的影响,如果使用的是ResNet-101主干,使用角点预测方法,AP是最低的;使用沙漏网络和Anchor的方法AP有所提升;使用沙漏网络+角点预测效果是最好的。
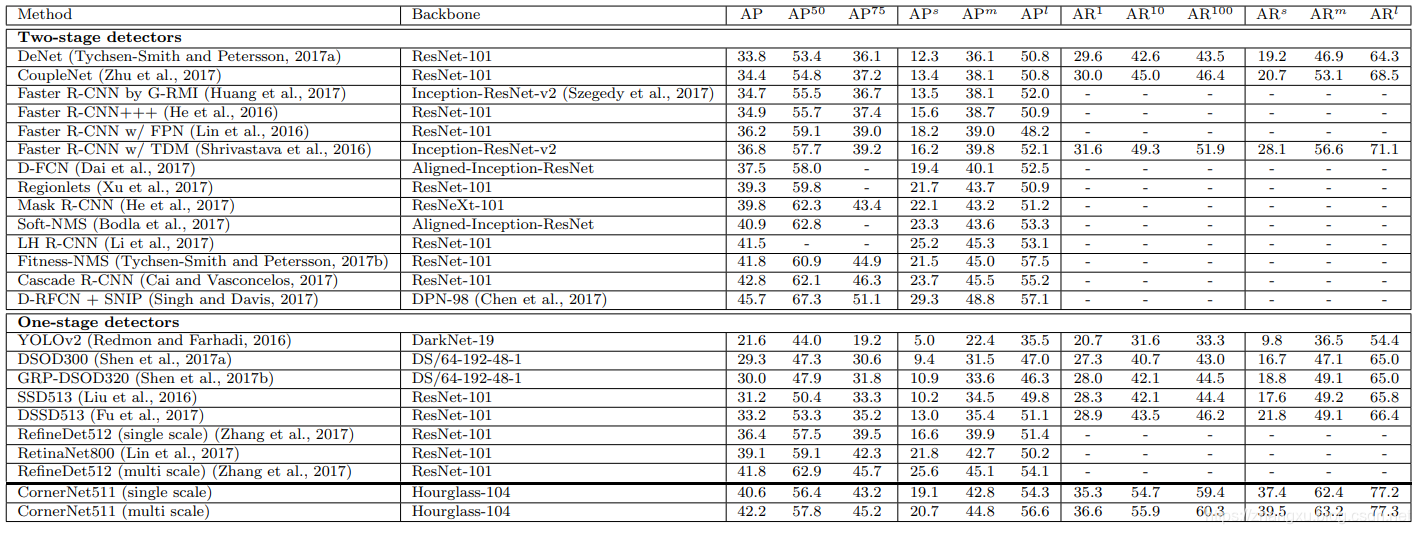
最后就是综合的实验结果,在CornerNet之前的方法全部都是基于Anchor的,而上表的下半部分是one-stage的方法,上半部分是two-stage的方法,CornerNet的AP超过了所有的one-stage检测器,但是有一点是它的AP50不如RefineDet和RetinaNet,这可能是由于CornerNet的半径选择策略和高斯分布的惩罚系数,让CornerNet关注更高的IOU。
