论文详细解释了anchor-free与anchor-based的本质区别,此外,使用ATSS去尝试解决label assignment的问题

摘要:
近年来,anchor-based检测器一直主导着目标检测。近年来,anchor-free检测器由于FPN和Focal Loss的引入而受到广泛关注。本文首先指出anchor-based检测与anchor-free检测的本质区别是在于如何定义正、负训练样本,从而导致两者之间的性能差距。如果他们在训练中对正样本和负样本采用相同的定义,无论从一个anchor还是一个point回归,最终的表现都没有明显的差异。由此可见,如何选取正、负训练样本对当前目标检测具有重要意义。然后,我们提出了一种自适应训练样本选择(ATSS),根据目标的统计特征自动选择正样本和负样本。它显著地提高了anchor-based和anchor-free检测器的性能,并弥补了两者之间的差距。最后,我们讨论了在图像上每个位置平铺多个anchor点来检测目标的必要性。在COCO数据集上进行的大量实验支持了我们的上述分析和结论。随着新引入的ATSS,我们在不引入任何开销的情况下,将最先进的检测器大大提高到50.7%的AP。
引言:
1. 当前Anchor-free detectors可以分为两种类型:
• Keypoint-based:Cornernet、Centernet
• Center-based:FCOS、Foveabox
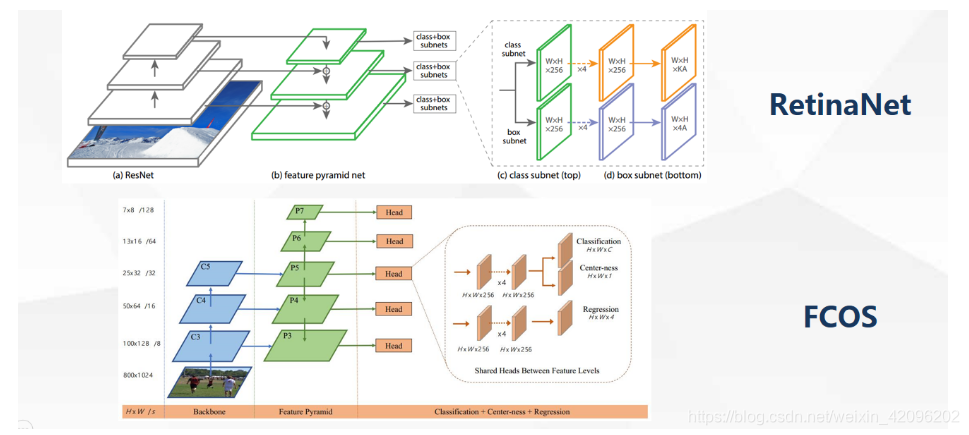
2. Anchor-free和Anchor-based方法如上图所示,可以看出来两种方法结构非常相似,Anchor-free是将点作为预设值的样本而不是anchor。它们之间有三个主要的区别:
(1) 每个位置的anchor的数量。RetinaNet每个位置设置几个anchor,而FCOS设置一个anchor每个位置;
(2) 正、负样本的定义。RetinaNet是根据IOU阈值设定,FCOS使用空间和尺度的限制来确定正负样本;
(3) 回归开始状态。RetinaNet将目标边界框从预置anchor框中回归,FCOS从点定位目标。
3.本文的创新点:
(1) 基于上述分析的区别,先指出了anchor-based检测与anchor-free检测的本质区别;
(2) 提出了一种自适应训练样本选择(ATSS),根据目标的统计特征自动选择正样本和负样本;
(3) 讨论了在图像上每个位置平铺多个anchor点来检测目标的必要性。
正文:
一、为什么anchor-free(FCOS)性能明显好于anchor-based(RetinaNet)?
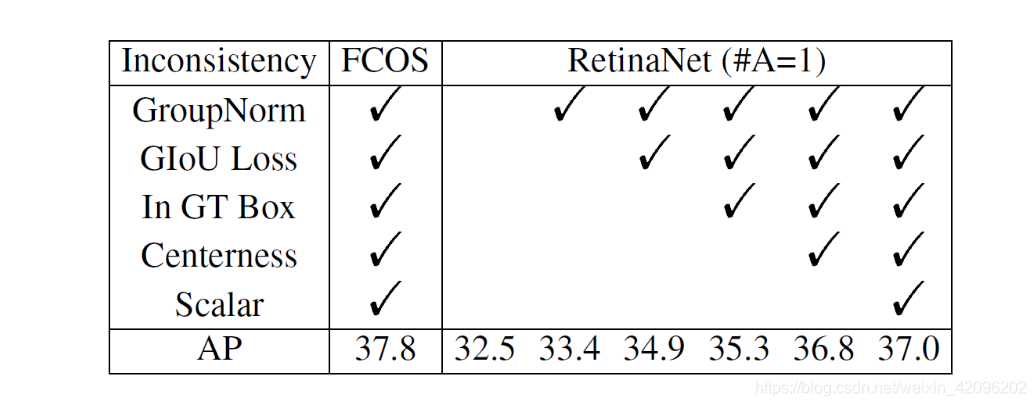
1. 文章首先分析了FCOS比RetinaNet多用的一些隐藏的涨分点,排除一些因素的干扰,主要由以下几项:
• adding GroupNorm in heads
• using the GIoU regression
• limiting positive samples in the ground-truth box
• introducing the centerness branch
• adding a trainable scalar for each level feature pyramid
经过实验分析,可以看出来FCOS比RetinaNet实际AP值只高了0.8个点
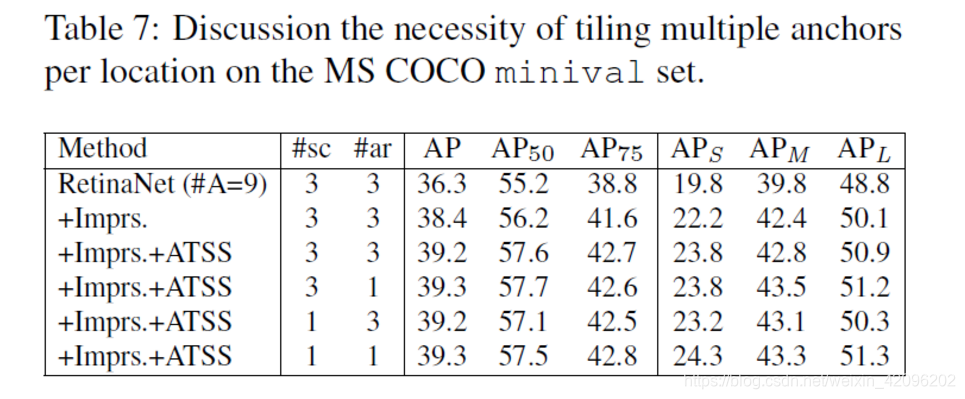
2. 分析两种方法的3个主要区别的贡献度:
(1) 每个位置的anchor的数量,这个在是1的实验中已经含盖了,RetinaNet中的A=1,意思是Anchor数量设置为1;
(2)正、负样本的定义 (3)回归开始状态
实验分析了这两个差异所造成的影响: 1)如果两者对正负样本的定义一致; 2)如果两者回归对象一致

实验结果表明定义正负样本的差异是造成两者性能差异的主要因素
3.最终结论:
指出了基于一阶段anchor-based的检测器与anchor-free检测器的本质区别在于如何定义正、负训练样本,这对于当前的目标检测具有重要意义,值得进一步研究。
具体来说:
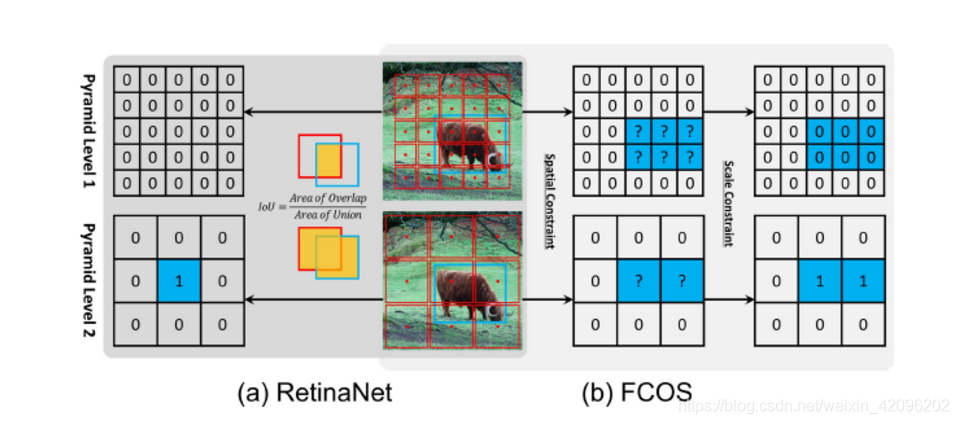
如图所示,FCOS首先使用空间约束在空间维度中查找候选正样本,然后使用比例约束在比例维度中选择最终正样本。与此相反,RetinaNet利用IoU直接同时选择空间和尺度维度的最终的正样本。
二、ATSS(Adaptive Training Sample Selection)
基于上述分析,如何更好地定义正负样本,对于目标检测的提升有着重要的意义,之前的FCOS、RetinaNet等都是属于hard型的定义方法,本文提出了自适应选择正负样本的方法:

算法流程:
- 对每个ground-truth box记为g, 在一个特征图上按照L2距离找到离中心最近的k个候选正样本集,总共有L个特征图,所以候选正样本集有k*L个;
- 计算g和候选正样本集的均值方差,得到tg=mg+vg;
- 我们选择IoU大于或等于阈值tg的候选样本作为最终正样本。值得注意的是,我们还将正样本的中心限制在ground-truth框中此外,如果将一个anchor分配给多个ground-truth box,则将选择IoU最高的那个。其余为负样本。
方法动机:
1. 使用L2距离找到离中心最近的k个候选正样本集是因为对于RetinaNet,当anchor中心更靠近物体中心时,IoU更大。对于FCOS,point离目标中心越近,检测质量越高。
2. 使用统计样本的均值和方差作为阈值的原因是如下图,图3(a)所示的高均值mg表明它有高质量的候选集,IoU阈值应该是高的。低mg如图3(b)所示,表明其候选人大多为低质量,IoU阈值应较低。高标准差vg意味着有一个最适合此目标的特征金字塔级别。利用平均mg和标准偏差vg之和作为IoU阈值tg,可以根据目标的统计特性,自适应地从适当的特征金字塔水平上为每个对象选择足够多的阳性结果。
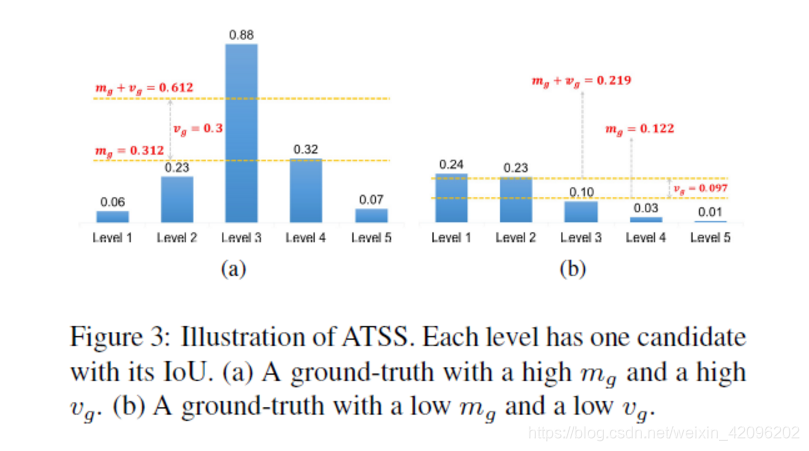
实验结果:
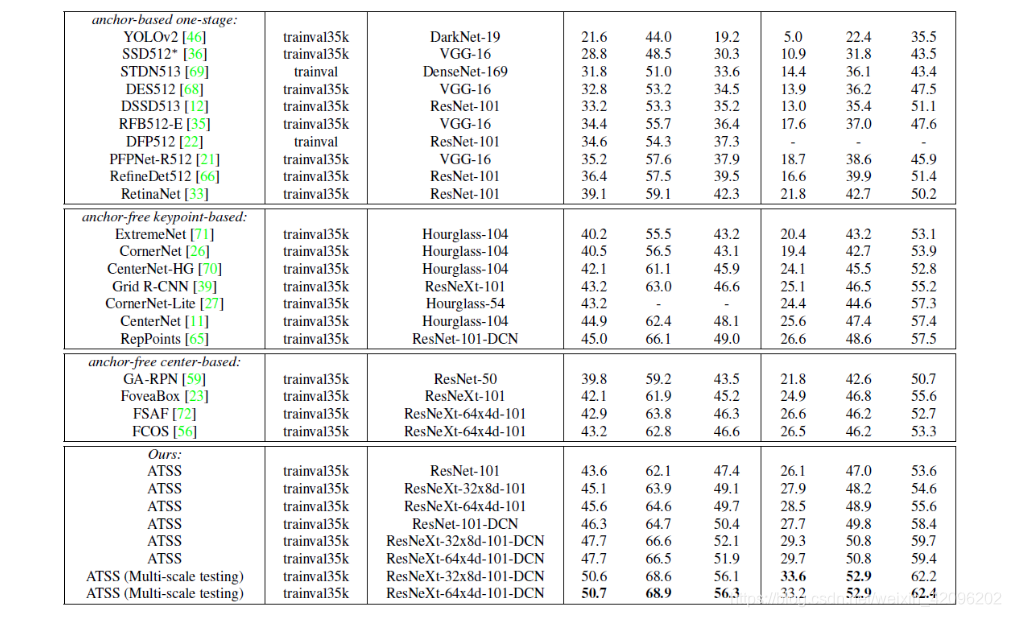
1.anchor-free、anchor-based、ATSS对比
2.ATSS中anchor预设值数量的必要性