逻辑回归与线性回归的联系与区别
联系:两种都可以归于同一个家族,即广义线性模型。这个家族中的模型形式基本上都差不多,不过的是因变量不同,如果是连续的就是多重线性回归,如果是二项分布就是logistic回归。
区别:
(1)线性回归用来预测,逻辑回归用来分类;
(2)线性回归是拟合函数,逻辑回归是预测函数;
(3)线性回归的参数计算方法是最小二乘法,逻辑回归的参数计算方法是梯度下降
逻辑回归的原理
简单来说,逻辑回归是在数据服从伯努利分布的假设下,通过极大似然的方法,运用梯度下降法来求解参数,从而达到将数据二分类的目的。
具体来说,在线性回归中,因变量是连续变量,那么线性回归能够根据因变量和自变量之间存在的线性关系来构造回归方程;但是,一旦因变量是分类变量,那么因变量与自变量就不会存在上面这种线性关系了,这时候就要通过某种变换来解决这个问题,这个变换就是对数变换;逻辑回归是在线性回归的基础上套用了一个逻辑函数,y值控制在0到1之间。
逻辑回归可以看做是两步,第一步和线性回归模型的形式相同,即一个关于输入x 的线性函数:
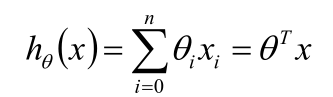
第二步通过一个逻辑函数,即sigmoid函数,将线性函数转换为非线性函数。

注意: 逻辑回归用于分类(一般为二分类),而不用于回归!
逻辑回归损失函数推导及优化

正则化与模型评估指标
-
正则化
正则化就是在损失函数后加上一个正则化项(惩罚项),其实就是常说的结构风险最小化策略,即经验风险(损失函数)加上正则化。一般模型越复杂,正则化值越大。 正则化是用来对模型中某些参数进行约束,目的是防止过拟合。 -
评估指标
-
- 分类模型: 准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-sore(精确率和召回率的调和平均) 、AUC(ROC曲线下面积)
-
- 回归模型: 平方根误差(RMSE)、误差分位数(Quantiles of Errors)、Almost Crrect” Predictions
逻辑回归的优缺点
优点:
1.便于理解和实现,可以观测样本的概率分数
2.训练速度快
3.由于经过了sigmoid函数的映射,对数据中小噪声的鲁棒性较好
4.不受多重共线性的影响(可通过正则化进行消除)
缺点:
1.容易欠拟合
2.特征空间很大时效果不好
3.由于sigmoid函数的特性,接近0/1的两侧概率变化较平缓,中间概率敏感,波动较大;导致很多区间特征变量的变化对目标概率的影响没有区分度,无法确定临界值。
样本不均衡问题解决办法
(1)扩大数据集
(2)尝试增加其他评价指标F1/Recall/Kappa/ROC
(3)重采样
(4)其他分类模型
(5)增加惩罚项
sklearn参数
class sklearn.linear_model.LogisticRegression(
penalty=’l2’, 参数类型:str,可选:‘l1’ or ‘l2’, 默认: ‘l2’。该参数用于确定惩罚项的范数
dual=False, 参数类型:bool,默认:False。双重或原始公式。使用liblinear优化器,双重公式仅实现l2惩罚。
tol=0.0001, 参数类型:float,默认:e-4。停止优化的错误率
C=1.0, 参数类型:float,默认;1。正则化强度的导数,值越小强度越大。
fit_intercept=True, 参数类型:bool,默认:True。确定是否在目标函数中加入偏置。
intercept_scaling=1, 参数类型:float,默认:1。仅在使用“liblinear”且self.fit_intercept设置为True时有用。
class_weight=None, 参数类型:dict,默认:None。根据字典为每一类给予权重,默认都是1.
random_state=None, 参数类型:int,默认:None。在打乱数据时,选用的随机种子。
solver=‘warn’, 参数类型:str,可选:{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, 默认:liblinear。选用的优化器。
max_iter=100, 参数类型:int,默认:100。迭代次数。
multi_class=‘warn’, 参数类型:str,可选:{‘ovr’, ‘multinomial’, ‘auto’},默认:ovr。如果选择的选项是’ovr’,那么二进制问题适合每个标签。对于“多项式”,最小化的损失是整个概率分布中的多项式损失拟合,即使数据是二进制的。当solver ='liblinear’时,‘multinomial’不可用。如果数据是二进制的,或者如果solver =‘liblinear’,‘auto’选择’ovr’,否则选择’multinomial’。
verbose=0, 参数类型:int,默认:0。对于liblinear和lbfgs求解器,将详细设置为任何正数以表示详细程度。
warm_start=False, 参数类型:bool,默认:False。是否使用之前的优化器继续优化。
n_jobs=None,参数类型:bool,默认:None。是否多线程
)
任务连接
https://shimo.im/docs/Qy1YFPjH9HkpfAK1
参考:西瓜书
cs229吴恩达机器学习课程
李航统计学习
谷歌搜索
公式推导参考:http://t.cn/EJ4F9Q0