一,逻辑回归模型和思路
1.1什么是逻辑回归
逻辑回归是用来做分类算法的,大家都熟悉线性回归,一般形式是Y=aX+b,y的取值范围是[-∞, +∞],有这么多取值,怎么进行分类呢?不用担心,伟大的数学家已经为我们找到了一个方法。
也就是把Y的结果带入一个非线性变换的Sigmoid函数中,即可得到[0,1]之间取值范围的数S,S可以把它看成是一个概率值,如果我们设置概率阈值为0.5,那么S大于0.5可以看成是正样本,小于0.5看成是负样本,就可以进行分类了。
1.2逻辑回归模型
逻辑回归模型如下,由两部分组成,一部分是sigmod函数,另一个是决策边界,逻辑回归的思路是,先拟合决策边界(不局限于线性,还可以是多项式),再建立这个边界与分类的概率联系,从而得到了二分类情况下的概率。

以上也为逻辑回归的决策函数
sigmoid函数:
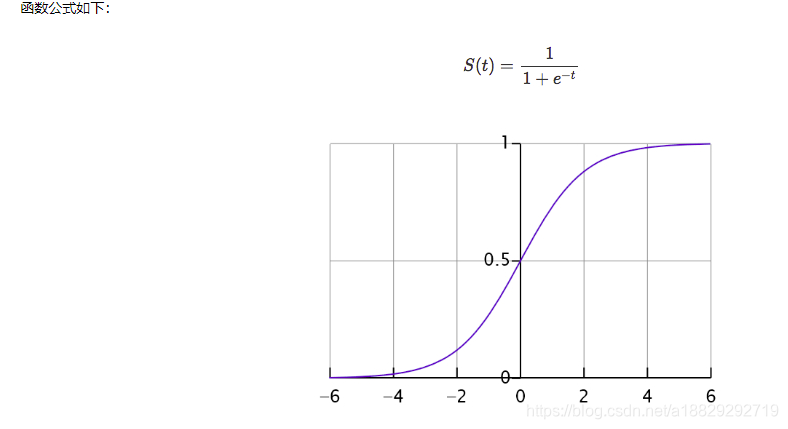
可以对线性回归产生的连续值转换为一个0-1的概率值,并且可以根据任务选择合适的阈值来进行分类任务。
二,为什么要用逻辑回归
是为了能够进行分类,逻辑回归使用对数几率函数(如下),可以计算出P(Y=1)的概率与x的直接关系,然后比较概率值选择合适的类型,将x带入sigmod函数,如果值大于0.5,就将样本判别为类别一,如果值小于0.5就将样本判别为类别0。

三.逻辑回归的优点
-
直接对分类的概率建模,无需实现假设数据分布,从而避免了假设分布不准确带来的问题
-
不仅可预测出类别,还能得到该预测的概率,这对一些利用概率辅助决策的任务很有用
-
对数几率函数是任意阶可导的凸函数,有许多数值优化算法都可以求出最优解
四,损失函数
不是线性回归不能使用均方误差做为损失函数
损失函数非突函数,难以优化
逻辑回归的损失函数是 log loss,也就是对数似然函数,或者交叉熵损失,函数公式如下:
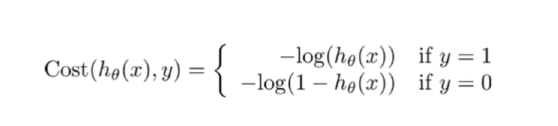
以上两个名字及为什么这么称呼都需要理解:
**对数似然函数:**我们想要达到的目的是,当真实值为1时,我们想要预测值h(x)越接近1,损失越小,当真实值时0时,我们想h(x)越接近0时损失越小,从上面函数可以达到这个效果,所以我们就选择log函数做为损失函数。
以上表达式是分段的,不易求解,所以将上面两种情况合并就出现了下面的表达式(很重要):
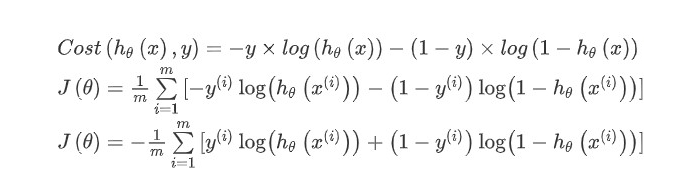
从这个整合后的公式能看出来他就是我们之前提到的交叉熵公式。
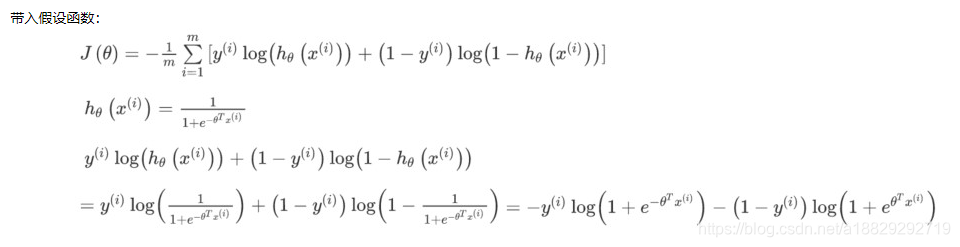
从极大似然估计理解逻辑回归的损失函数(重要)
逻辑回归的损失函数别名1:负对数似然损失
将分类问题中我们的假设函数看作0-1之间的一个概率估计,每个样本都是一次实验,实验之间独立:
似然函数:
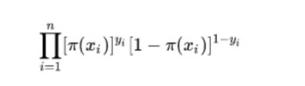
极大似然是一个方法,n个事件,当我们拿到一组样本时,每个样本都可以理解为一个独立的实验,n就是样本个数,后面的式子表示事件发生的概率,最后连乘就是事件的联合概率,所以似然函数表示的是所有事件的联合概率。他要求的是一个参数thta,让这个连乘的公式最大。这个公式中的y是符合0-1分布的,意思就是带着开关的,后面的两个乘子只会保留一个。thta(pi(x))是对标签的预测。
然后对上面的似然函数两边都去对数,就成了下面的对数似然函数。
对数似然函数:
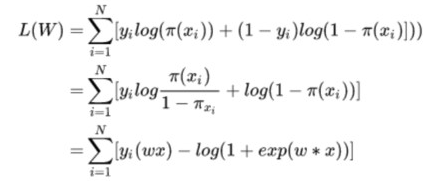
我们的目的是最小化损失函数(最小化负对数似然损失),也就是最大化对数似然函数,最大化似然函数,这个思想和贝叶斯学派的思想不谋而合。
另一个更常用的较发是交叉熵损失:
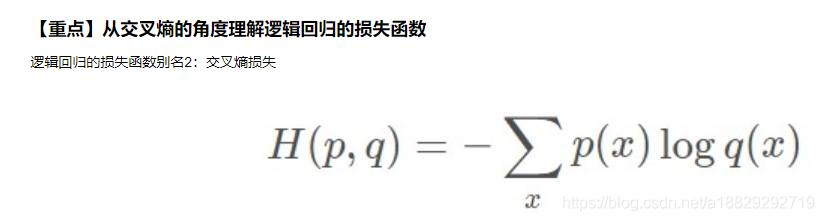
交叉熵损失函数如上,在伯努利分布情况下展开后和逻辑回归的损失函数是一样的,所以也叫做交叉熵损失。
以上是证明逻辑回归损失函数合理性的两个角度。
python实现逻辑回归的损失函数:
import numpy as np
def cost(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X* theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X* theta.T)))
return np.sum(first - second) / (len(X))
添加正则化的损失函数
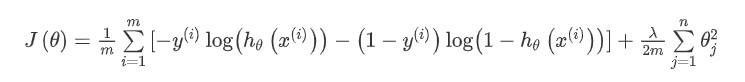
def costReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X*theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X*theta.T)))
reg = (learningRate / (2 * len(X))* np.sum(np.power(theta[:,1:theta.shape[1]],2)) #正则项
return np.sum(first - second) / (len(X)) + reg
添加正则化的目的:
1.防止过拟合,所以正则化不是必须的,可以在没有添加正则化的情况下试试
2.一些论文中说可以增加模型的鲁棒性,所以经常会加。
lamda如何选择呢?
他是一个超参数,是需要人为手动去调节的,没办法通过学习获得,在有些算法中是直接给我们封装好了的,比如lasso给了一个默认的lamda,我们在这个基础上再进行手动的调节,后面深度学习中这个值是需要我们手动设置的,经验的可以从0.1开始设置。
这是一个超参选优的问题:
和我们所有超参数选择方式是一样的,是对结果的交叉验证得来的。可以使用网格搜索的方式来对不同的lamda进行评分,选择评分最高的做为参数,相比于数据超参数对最终的影响不是很大,所以我们一般就选择经验值,可能就是0.05或者0.1
以上就是逻辑回归的核心:
1.sigmoid函数做为决策函数
2.损失函数公式,以及两个角度的解释
五.使用梯度下降法确定thta,使得损失函数最小
逻辑回归常用的优化方法有哪些
一阶方法(损失函数对thta求一阶导数)
【重点】梯度下降(背景知识:幂函数/指数函数/对数函数的导数公式)
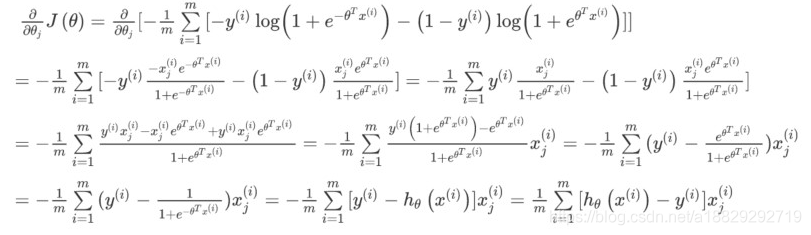
导数形式和线性回归很像
为什么梯度下降法被广泛的做为函数优化的方法?
比较常用的随机梯度下降和批次梯度下降,梯度下降法的梯度值不依赖于全量样本(随机梯度下降使用的是一个样本)。但是最小二乘法是需要全样本的。
随机梯度下降因为选取的是一个随机样本,这个样本可能不是像梯度下降的方向走的,但是总体的大方向是向梯度下降方向走的。
随机梯度下降(不使用全量样本)的好处:
运筹学科学家进行实验发现如果使用全量样本上的梯度,可能使得整体的梯度进入一个鞍点,也就是局部最优。全量样本很难让梯度逃离鞍点达到全局最有,反而是随机梯度下降这种随机性有可能得到全局最优,所以随机梯度下降也是非常常用的一种梯度下将。
随机梯度下降的坏处:
可能过于随机,造成下降的速度很慢,所以另一个更常用的是给一个batch<=64,在这个样本量上对参数进行更新,比如上面梯度式子中的m就是batch的个数。
二阶方法:牛顿法、拟牛顿法:
【了解】这里详细说一下牛顿法的基本原理和牛顿法的应用方式。牛顿法其实就是通过切线与x轴的交点不断更新切线的位置,直到达到曲线与x轴的交点得到方程解。在实际应用中我们因为常常要求解凸优化问题,也就是要求解函数一阶导数为0的位置,而牛顿法恰好可以给这种问题提供解决方法。实际应用中牛顿法首先选择一个点作为起始点,并进行一次二阶泰勒展开得到导数为0的点进行一个更新,直到达到要求,这时牛顿法也就成了二阶求解问题,比一阶方法更快。我们常常看到的x通常为一个多维向量,这也就引出了Hessian矩阵的概念(就是x的二阶导数矩阵)。

缺点:牛顿法是定长迭代,没有步长因子,所以不能保证函数值稳定的下降,严重时甚至会失败。还有就是牛顿法要求函数一定是二阶可导的。而且计算Hessian矩阵的逆复杂度很大。
拟牛顿法: 不用二阶偏导而是构造出Hessian矩阵的近似正定对称矩阵的方法称为拟牛顿法。拟牛顿法的思路就是用一个特别的表达形式来模拟Hessian矩阵或者是他的逆使得表达式满足拟牛顿条件。主要有DFP法(逼近Hession的逆)、BFGS(直接逼近Hession矩阵)、 L-BFGS(可以减少BFGS所需的存储空间)。
六,逻辑回归做多分类
6.1one vs rest
其实我们可以从二分类问题过度到多分类问题(one vs rest),思路步骤如下:
1.将类型class1看作正样本,其他类型全部看作负样本,然后我们就可以得到样本标记类型为该类型的概率p1。
2.然后再将另外类型class2看作正样本,其他类型全部看作负样本,同理得到p2。
3.以此循环,我们可以得到该待预测样本的标记类型分别为类型class i时的概率pi,最后我们取pi中最大的那个概率对应的样本标记类型作为我们的待预测样本类型。
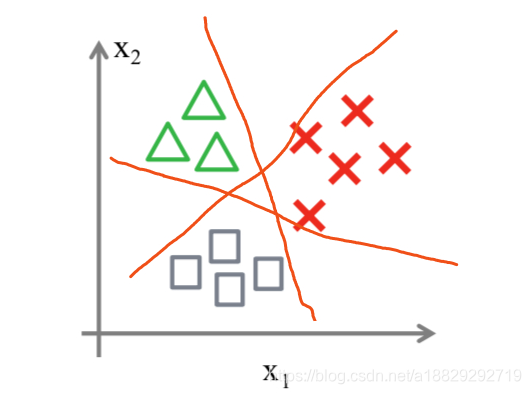
缺点:后面的分类器会受到前面分类器的影响
6.2 One-Vs-One
将数据集拆分成n个2分类的数据集,并两两训练出一个分类器,再进行投票
One-Vs-All 和 One-Vs-One ,如果有 k 个不同的类别,对于 One-Vs-All 来说,一共只需要训练 k 个分类器,而 One-Vs-One 则需训练 C(k, 2) 个分类器,然后所有分类器投票选择出最终的类别
缺点:
当类别空间很大的时候C(k,2)很大,比如NLP中分别一个字属于词表空间中的哪一个,词表空间大小就是这个k,如果有6000个词,分类器就会很多,这个计算复杂度就会很高,所以就有了下面的softmax
6.3 Softmax
在二元的逻辑回归模型中,我们用 Sigmoid 函数将一个多维数据(一个样本)映射到一个 0 - 1 之间的数值上,有没有什么方法从数学上让一个样本映射到多个 0 - 1 之间的数值呢? – Softmax 函数!
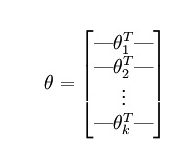
于是我们需要定义一个新的假设函数,与sigmoid函数对应,公式如下:
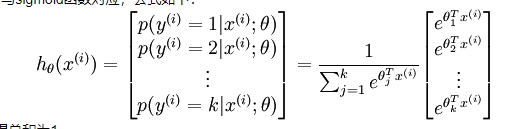
一共有k个类别;分母为归一化项,使得总和为1
以上函数的直观理解:
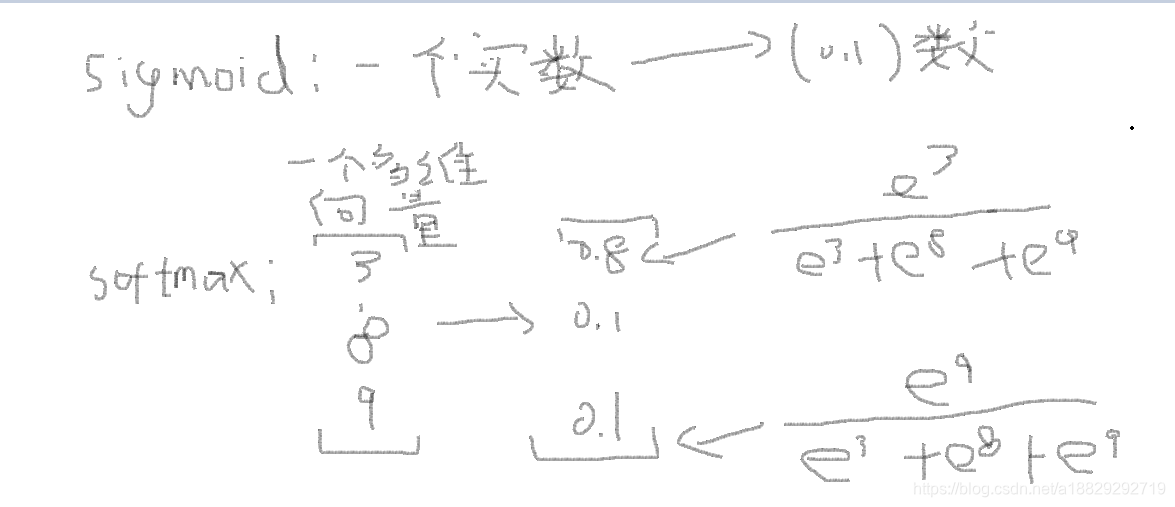
sigmoid函数是将一个实数转换为0-1之间的数,softmax是将一个向量转化为一个0-1之间的向量。正则化使用了指数。
如果只是为了归一化并得到概率,为什么需要指数计算?
答:马太效应,突出那个激活前最大的类别输出的概率,也就是max的地方。
直白的说就是放大属于某些标签的概率,指数能起到这个作用,如果按照正常的数字,得到的概率可能是[0.5,0.4,0.1],使用指数之后变成了[0.8,0.1,0.1],后面这个属于第一类的概率明显大了。更具说服力。
下图可以解释softmax计算过程:
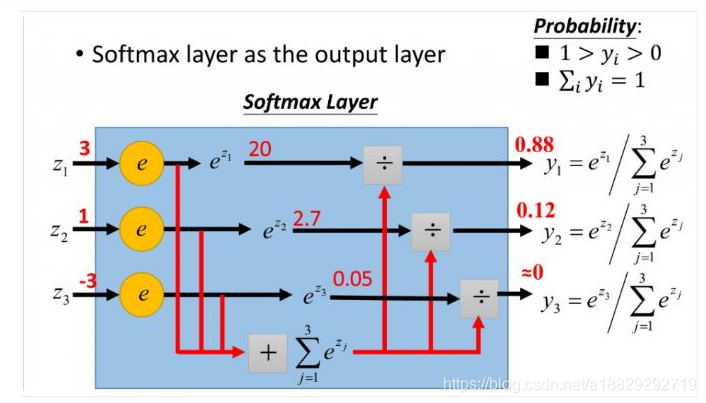
首先对于输入的实数域的值做指数运算,然后在做归一化处理得到最终结果。
举例说明softmax函数处理多分类:
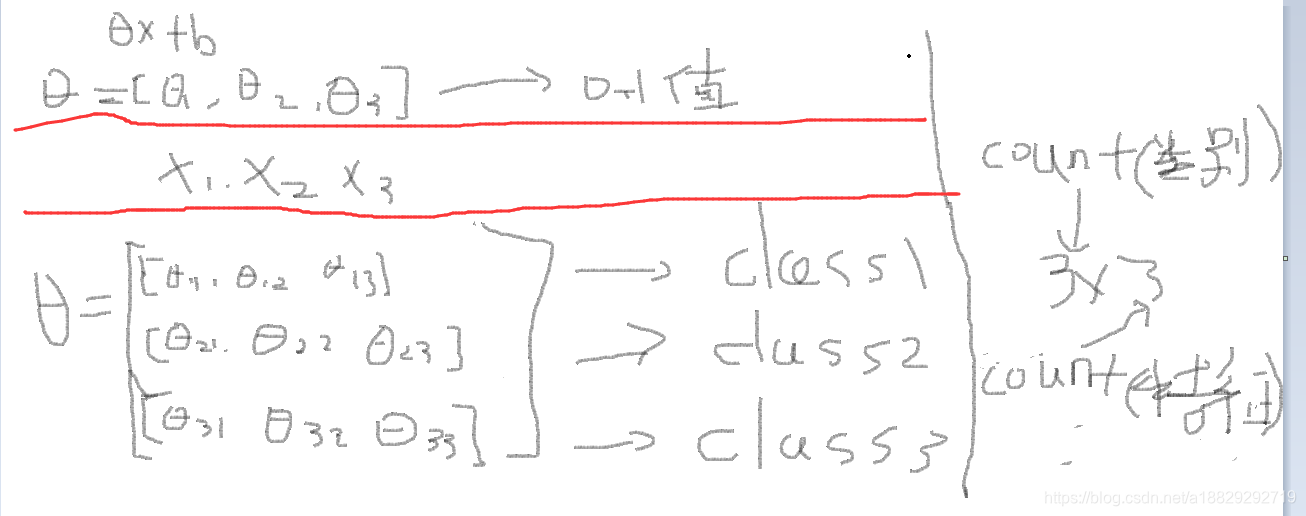
对于sigmoid处理二分类时,输入的w是一个向量,所以wx+b后是一个数值,然后再经sigmoid函数转化,如上图。
对于softmax处理多分类时,输入的是一个矩阵w,然后经过wx+b之后就是一个向量Z=[z1,z2,z3],然后再经过softmax函数形成一个概率向量,直观的理解就好像是做了很多的二分类。
可以发现,参数的量级*k,形式也从向量->矩阵:
定义了新的假设函数(hypothesis function)之后,我们要得到其对应的代价函数(交叉熵损失再多分类中的形式):
m代表类别,k代表特征
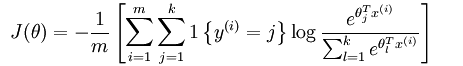
其中大括号的取值规则为大括号内的表达式值为真时,取 1,为假时取 0
其导数公式:
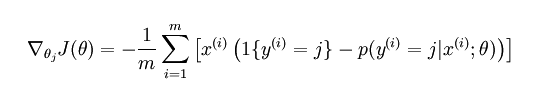
导数求导的更新过程(每一步推导过程要看得懂):

还是复合函数求导。
本质上讲,Softmax 回归就是 logistic 回归进行多分类时的一种数学拓展,如果让分类数为 2 带入 softmax 回归,会发现其本质上和 logistic 回归是一样的。
参考公式:
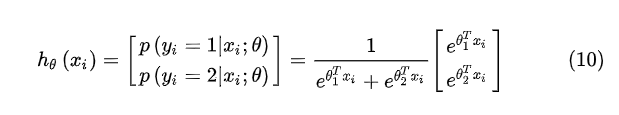
化整参数:
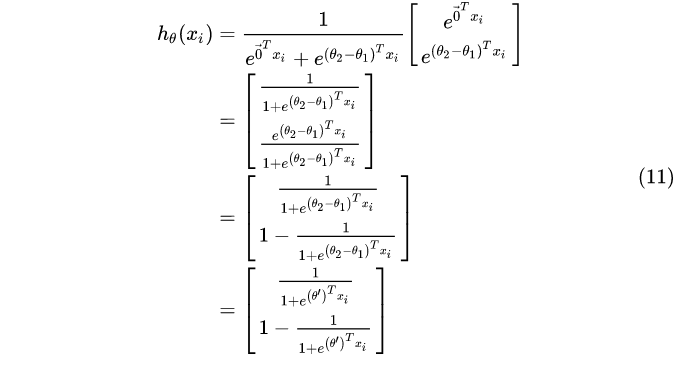
softmax是非常重要的,比如后面NLP都是多分类问题,很少有二分类问题,还有深度学习网络中,
softmax应用在将实数域的分布转换为归一化的概率分布。
七.总结
逻辑回归有什么优点
- LR能以概率的形式输出结果,而非只是0,1判定。
- LR的可解释性强,可控度高(你要给老板讲的嘛…)。
- 训练快,feature engineering之后效果赞。
- 因为结果是概率,可以做ranking model。
逻辑回归有哪些应用
- CTR预估/推荐系统的learning to rank/各种分类场景。
- 某搜索引擎厂的广告CTR预估基线版是LR。
- 某电商搜索排序/广告CTR预估基线版是LR。
- 某电商的购物搭配推荐用了大量LR。
- 某现在一天广告赚1000w+的新闻app排序基线是LR。
在十到五年前,LR在广告推荐领域处于霸主地位, 与同时代的决策树算法,SVM相比,简单易用效果也不错,因此被应用在广告,推荐,搜索排序领域,这三个领域都需要进行CTR预估
CTR预估是用来做什么的?
互联网公司80%的收入来源都是广告,所以广告部门是公司的核心,
广告收入=广告点击率*投放*每条营收,因为总投放和每条营收都是没法改变的,所以我们只能提升广告点击率。
怎么提升广告点击率呢,就是让广告更加相关,比如相亲网站在朋友圈的投放就要投放给年轻用户,而不是老年用户,因此需要做点击率预估,点击率是0-1之间的值,这个值可以由可以产生分类模型的所有模型产生,LR就是其中的一种。
在做广告投放时需要使用的特征是与广告的分发类型相关的,比如百度搜索就是非个性化的,是与搜索的query(检索词有关的),这个query的特征有哪些,我们就可以做one-hot,然后再加上一些广告标题,或者人工定义的特征,这种多维的稀疏特征的就非常适合LR,
对于特别稀疏的特征,LR不会有影响,但是决策树就会有很大影响。
NLP 中的一个方向是检索,检索排序也是一个类似CTR预估的问题,传统算法工程师中大部分也是检索,推荐,广告,风控,纯NLP,CV
CTR预估是一个二分类问题,click =1,not click =0,所以所有可以做二分类的模型都可以做CTR预估。
逻辑斯特回归为什么要对特征进行离散化。
比如将年龄[1,2,3,4,5…]做离散化成为0-18,18-50,50-60三个年龄段,这样就可以根据每个分段来计算概率,比如得病的概率[0.3,0.1,0.6]
-
非线性!非线性!非线性!逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
具体要不要离散化还是要具体问题具体分析的,比如上面提到的年龄和的病之间的关系就可以离散化,但是房价和建筑面积之间的关系就不用离散化了。
离散特征的增加和减少都很容易,易于模型的快速迭代; -
速度快!速度快!速度快!稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
离散化之后引入很多0,1值,在计算的时候GPU加速会比较快 -
鲁棒性!鲁棒性!鲁棒性!离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
一些离群点(比如极大值)会被分到桶里,让离散值对我们模型的影响不大, -
方便交叉与特征组合:离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
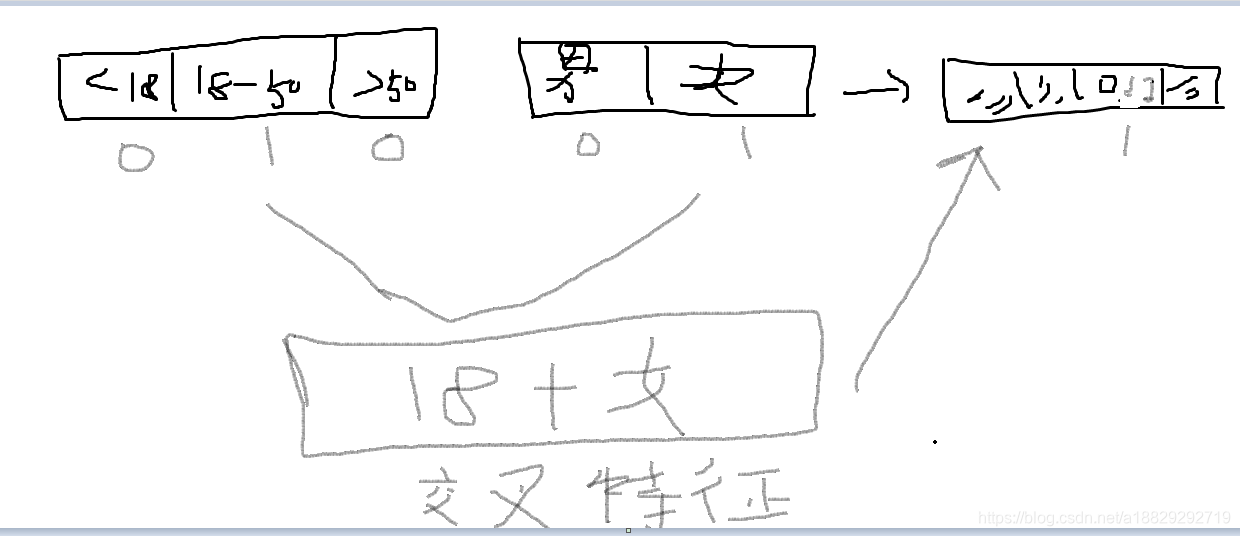
离散化之后可以做交叉特征,对于互联网核心的,广告,推荐,检索是非常有用的,如果不做离散化,像年龄这样的特征就没法选择,里离散化之后的0,1值就方便我们做特征交叉。
- 稳定性:特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
- 简化模型:特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
因为逻辑回归的优越性,我们在遇到很多问题的时候会选择先使用逻辑回归做第一版模型,因为其比较快,然后有了逻辑回归的结果之后再选择更深层次的模型去迭代。
逻辑回归的目标函数中增大L1正则化会是什么结果
所有的参数w都会变成0。
CTR预估等问题的范式
经典论文:https://dl.acm.org/doi/abs/10.1145/1242572.1242643 论文题目:Predicting Clicks: Estimating the Click-Through Rate for New Ads
发表于:Proceedings of the 16th international conference on World Wide Web,2007
引用次数:853(截至2020年04月22日)
重点:
- 逻辑回归的决策函数(sigmoid函数)
- 损失函数被成为负对数似然和交叉熵损失的原理
- 逻辑回归的损失函数
- 逻辑回归的优点
- 全过程的梯度下降过程(手写)
- 进行离散化的好处