版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/IOT_victor/article/details/83056169
目录
五、scikit-learn 中 logistic regression 参数
一、二元分类问题
Logistic regression ( 逻辑回归 ) ,尽管它的名字是回归,但通常作为分类算法。 Logistic Regression 在文献中也被称为 logit 回归,maximum-entropy classification ( MaxEnt ) ( 最大熵分类 ) 或 log-linear classifier ( 对数线性分类器 ) 。
1.1 二分类任务
找到一个单调可微函数(sigmod函数),将分类任务的真实标记y与线性回归模型的预测值联系起来。
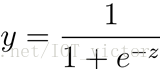

1.2 对数几率
对数几率(log odds)
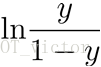
由(1-1)变化得到
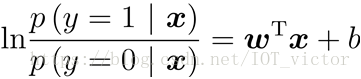
其中
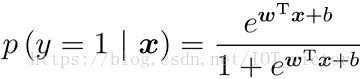
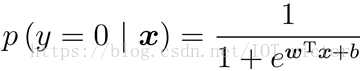
1.3 极大似然法(maximum likelihood)
①极大似然法:最大化对数似然函数
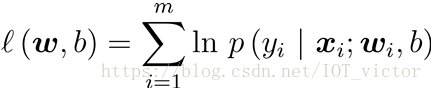
初始化参数
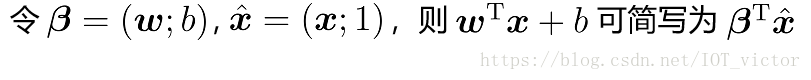
再令P为
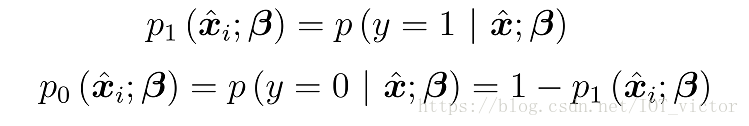
则似然项可重写为
(1-3)
②将最大化问题转换为最小化负对数似然函数求解
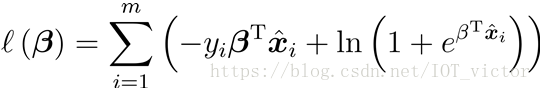
1.4 优化算法
梯度下降法、牛顿法等
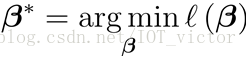
1.5 模型综述

二、两种角度看待逻辑回归
2.1 统计学角度:似然函数
与线性回归类似,为了估计模型参数,需要定义一个合理的参数似然函数(或者模型损失函数)。然后根据此函数,推导出模型参数估计值的表达式。
统计学角度考虑:根据模型,数据出现的概率越大越好(即最大似然估计法)
见1.3
2.2 机器学习角度:损失函数
借鉴统计学中的做法,定义损失函数如下
交叉熵
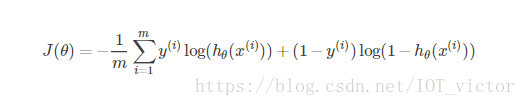
2.3 最终预测:从概率到选择
逻辑回归模型的直接预测结果并不是非事件发生与否,而是事件放生的概率。
简而言之,逻辑回归的结果并非我们想要的最终分类结果,而是需要 进一步处理的中间结果。
三 、模型评估
F1-score、ROC曲线与AUC
四、多元逻辑回归
OvR(也叫OvA)、OvO
五、scikit-learn 中 logistic regression 参数
参考资料
[1] 《机器学习》周志华
[2] 《精通数据科学》唐亘
[3] 《统计学习方法》李航