A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance
(关于城市监控车辆重识别的基于深度学习的渐进式算法)
1.简介
背景(略)。
作者提出PROVID,基于深度学习的车辆re-ID方法,有如下特点:
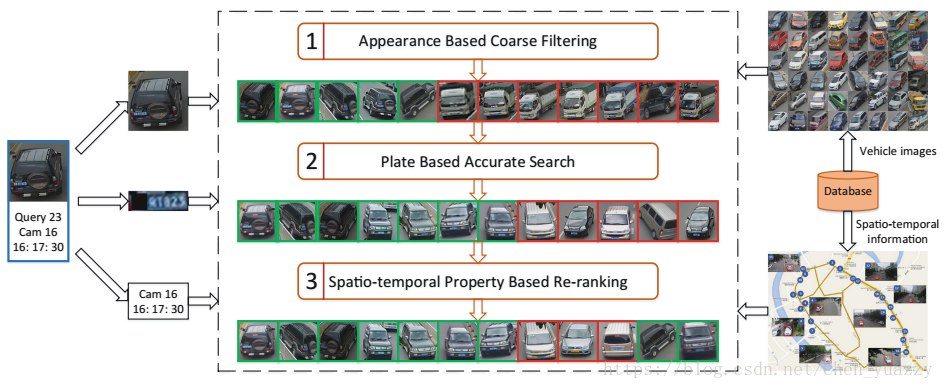
(1)和现实中一样,采用循序渐进的方法搜寻车辆(由粗到精,由近到远)
(2)粗分类:根据深度神经网络学习的外观属性(颜色,纹理,形状,种类)模型作为粗分类器。采用low-level和high-level融合模型。
(3)精确查找:根据基于Siamese网络的车牌认证匹配车牌图像。用大量车牌图片训练siamese网络。
(4)由近到远:根据时空关系协助搜寻过程。对车辆进行重排序,得到最终结果。
作者建立了车辆重识别的数据集—VeRi-776,包括多种属性,高再现率,充足的牌照信息和时空标签。
2.相关工作
略
3.提出方法
3.1概述
见简介:整体网络架构如下:
3.2**CNN抽取外观属性**
纹理特征由传统的描述符表示,如尺度不变特征变换(SIFT),然后描述符被BOW模型编码。由于其在图像检索里的精确和有效。
颜色特征由CN模型抽取,该模型由BOW模型量化,由于它(who?)在行人重识别中的表现。
High-level属性使用CNN学习,如Googlenet。此模型在CompCars数据集上微调,用于监测车辆的细节属性(如门的数量,灯的形状,座椅的数量,车辆的模型)。
这三个属性特征由distance-level融合器合成。
BTW,语义属性???
3.3基于Siamese神经网络的车牌认证
车牌识别受限于视角,光照,分辨率,图像模糊等等方面,而且车牌识别技术需要:车牌定位(在图中的位置),形状适应,字符分割,字符识别。因此它十分不适合本项目。
Siamese网络(SNN)应用于签名认证任务。SNN学习将输入图像映射到潜在空间的函数,相似度大的是相同对象的一对图像,相似度小的则是不同对象的一对图像。因此,种类数量大的时候,或者训练时全部种类的样例不可得到的时候,就可以使用SNN。
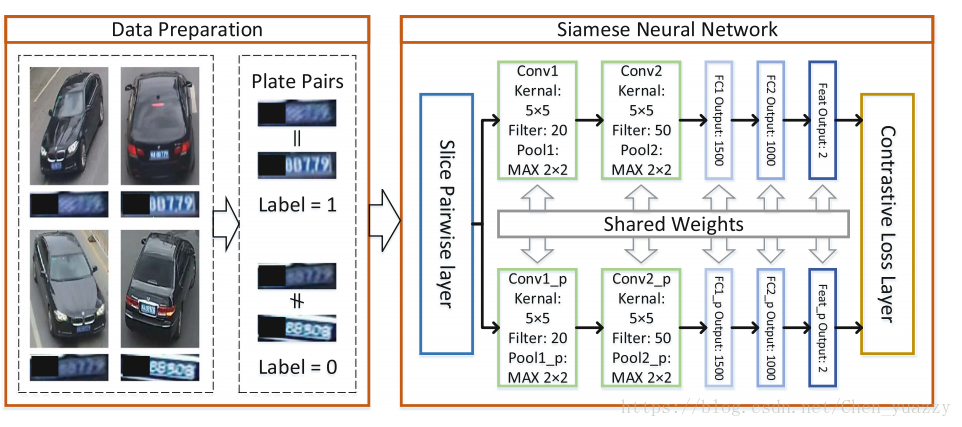
SNN的网路如上图所示,两个平行的CNN,每一条CNN构成如下:
(1)2层(卷积+最大池化)
(2)3层全连接层
(3)最后使用Contrastive LOSS函数
(4)参数设置如图所示
(5)输入两张图片,若为同一图片,则标记1,否则标记0(如何传递?)前向传播,Contrative loss函数联合计算LOSS。反向传播,共享权值同时更新。
Sw(x1)是:X1映射到潜在尺度空间的值。
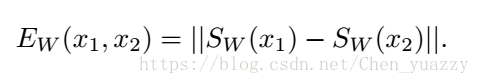
这个式子也叫能量函数(energy function):测量的是x1和x2之间的兼容性。
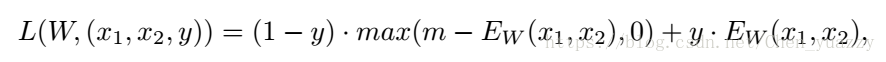
(x1,x2,y)是一对有标签的样例,m是正范围。在caffe框架设置默认m=1。测试时,SNN的FC2层抽取1000维的特征(什么意义?)
欧氏距离用来估计两张图像之间的相似性得分。(如何计算(变量是谁)??与上面的能量函数有区别吗?)
3.4基于时空关系的车辆重排序
分析了20000个同一车辆的图像对,和20000个随机选取的车辆的图像对。用统计数据看出:相同车辆对的时间、空间距离比随机选取车辆对的时间、空间距离小很多。
得出结论,大胆假设:两幅图像大概率是同一车辆如果它们的时间、空间距离都很小。
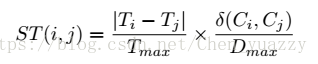
Tmax是所有查询图像和测试数据中最大的时间差。
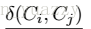
Dmax是所有相机之间的最大路径距离。
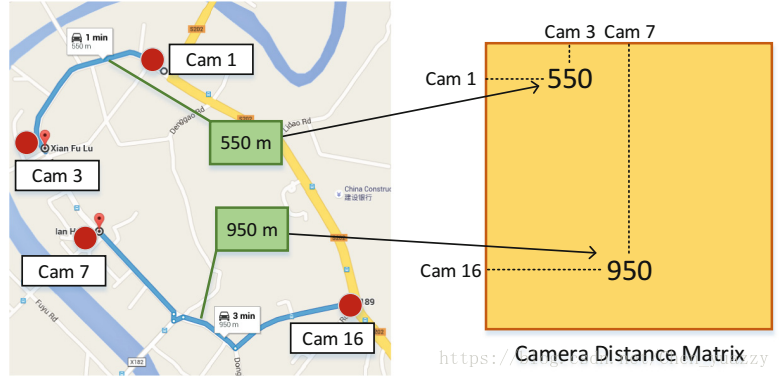
两相机之间的最短路径由Google map获得,存在矩阵中。(如下图所示)
4.实验
4.1数据集
VeRi-776数据集是从VeRi改进而来。
VeRi数据集有如下3个特点:
(1)它包括了由20个监控摄像头捕获的619辆车的40000张图像。
(2)它的图像是在真实世界中的无限制的交通场景中捕获的,并标注了许多属性:BBoxes,种类,颜色,(有颜色标注!为何还要3.2节中的颜色抽取?)品牌。
(3)它的每一个图像都是2~18个相机从不同的视角、照明环境、遮挡情况下捕获的。提供了对车辆Re-ID真实情况的高复现率。
因此,我们扩建了VeRi,有如下几个方法:
(1)数据容量扩大
向数据集中添加20%新车辆,同样标注了BBoxes,种类(这个types到底是啥?),颜色,品牌,交叉摄像机关系信息。这使得数据集包括了50000+张图像,9000+轨迹,776种车辆。
(2)车牌注释
将数据集分为200辆车(作为测试集)和576辆车(作为训练集)。在测试集中,从每一个轨迹中抽取一张图片,得到1678个查询(Why?)。对每一个查询图像和测试图像,人工标注车牌的边框信息(确定车牌的位置),得到车牌图像。
(3)时空关系注释
轨迹是同一时刻同一摄像头捕获到的车辆路径,属于同一轨迹的轨道被聚类在一起。首先对摄像头标号(1-20);然后使用第一次捕获到的时间戳最为它的时间标记;然后,为了加速(用于基于时空关系排序的)空间距离的计算,我们通过Google map计算20个摄像头每对之间的最短路径长度。
4.2实验设置
Image-to-track,图像到轨迹的方法。图片与轨迹的相似度=查询图像与所有轨迹上的图像的相似度。实际中,我们只需要找到一个相机中的轨迹就可以捕获目标车辆。因此,图像到轨迹的方法在实际场景中是更明智的选择。
4.3车牌认证的评估
经过大量车牌对训练的SNN模型能够把输入图案映射到潜在空间里(同一检测目标对相似度指标很大,不同的指标则很小)大量的训练车牌样例保证了学习模型的鲁棒性。
4.4车辆Re-ID的评估
在外观属性识别上,旧方法都有不错的表现,但在re-ID上就不行了。FACT比Googlenet更好,因为Googlenet只能考虑语义属性(high-level),但FACT除此外还加入了颜色和纹理特征。但外观属性识别不能精确确定车辆身份。
外观属性识别是粗分类,而车牌认证是精准搜寻。外观属性识别能过滤绝大多数不相似的车辆,尤其是那些有相似车牌的查询。然后剩下的车辆,外观相似,基于车牌的方法能够搜寻到车牌也相似的车辆,从而避免错误匹配。
我们的from-near-to-distant策略,渐进搜寻方法获得了较高的准确率以及提升了速度。
5.结论
由粗到精,由近到远(from-coarse-to-fine,from-near-to-distant)
外观属性识别->车牌认证->时空关系约束重排序
建立了数据集VeRi-776,包含不同的车辆属性,充足的车牌信息,精确的时空关系。
几个问题:
1.何为latent space(潜伏空间)?
3.关于BBoxes(边框),亦即确定图中车辆的位置的边框,边框的意义见如下博客:
https://blog.csdn.net/zijin0802034/article/details/77685438
4.这篇文章的颜色属性究竟是标注的还是利用网络识别的?语义(semantic)属性是什么?
5.几个算法SIFT?FACT MODEL?BOW?CN?LOMO?