主要参考
基于VGG的ssd
基于mobilenet的ssd
预训练模型基于slim
1 构建自己的模型
第一步,了解slim建立新模型的框架。定义一个Model类,主要有五部分组成:
- preprocess:在输入图像上运行检测器之前,对输入值进行任何预处理(例如缩放/移位/重新整形)。
- predict:产生可以传递给损失或后面处理函数的“原始”预测张量。这里会涉及到模型结构。
- postprocess:将预测输出张量转换为最终检测结果。
- loss:针对提供的groundtruth实体计算损失张量。
- restore:将检查点加载到Tensorflow图中。
2 了解源代码

2.1 训练逻辑
在/home/users/py3_project/models/research/object_detection目录下讲解配置文件dataset/ssd_mobilenet_v1_pascal.config:设置调用的模型名称及模型框架中的超参数、训练超参数、数据来源文件等
代码一train.py:模型训练开始部分
- 首先,主要讲解train.py的训练过程的逻辑。
该步是训练模型train.py调用的模块。train.py调用了多个模块,如下:
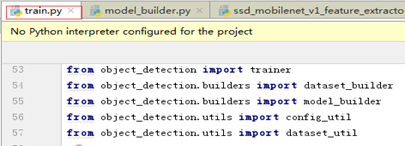
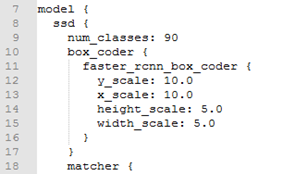
该步是train.py的主要功能之一–读取配置文件。其中train.py用到的部分主要有三块,model(模型特征)和train_config(优化器、预训练模型)和train_input_reader(训练数据集输入)。主要调用输入参数–配置文件dataset/ssd_mobilenet_v1_pascal.config,如下图三个部分model、train_config、train_input_reader:


该步是train.py的主要功能之一–调用训练方法。除了调用上面配置文件的部分,其中train.py最主要的操作如下:
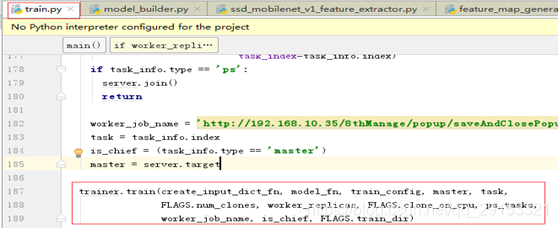
代码二:trainer.py模型训练的主要操作部分,具体实现调用其他模块
从该步开始讲解训练过程trainer.py。
模型训练主要在trainer.py中完成,训练使用的是迁移模型(不完全使用,微调),使用轻量级slim框架,主要是因为它自带了很多GOOGLE训练好的模型,比如vgg、mobilenet等多种模型结构。
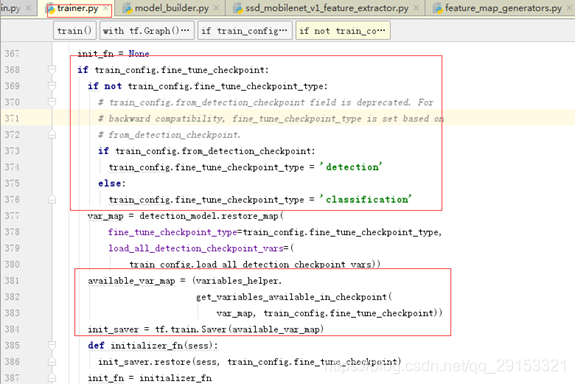
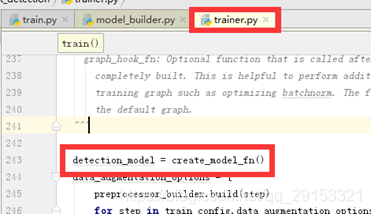
该步讲解迁移模型的主要步骤:初始化模型detection_model=create_model_fn,经过detection_model.preprocess、detection_model.provide_groundtruth、detection_model.predict、detection_model.loss、detection_model.restore_map,设置optimiter,进入训练。
首先,在trainer.py导入模型结构的类(代码第243行),然后它的最初定义在train.py中实现,如下:

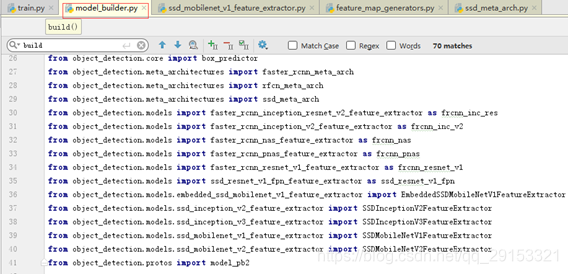
调用参数model_build.build确定模型结构,并且可以从下图看出model_builder.py中导入两类模型特征提取器并进行特征提取相应操作的模块,模型构建主要在这里实现:
然后,再在trainer.py求解total_loss、设置optimizer后,它们的具体实现还是调用了其他模块;
最后使用slim.learning.train进行训练,如下:
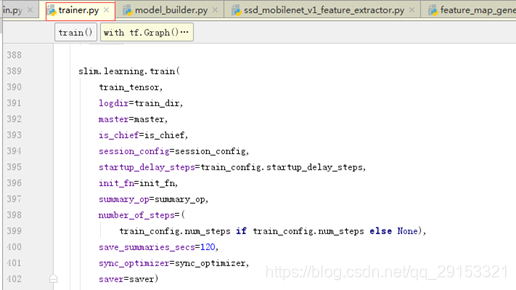
上述函数中,其中train_tensor用于计算损失和应用梯度操作,train_dir存储检查点文件路径,init_fn应用预训练模型,并且使用的是预训练模型(检测、分类)中的检测模型(之前dataset/ssd_mobilenet_v1_pascal.config配置文件相应部分(train_config下的fine_checkpoint_type)为True),因为检测模型不需要修改,这样不仅能提高检测准确性还能加快整个模型的收敛速度,而图像分类模型类别数不同,需要重新训练,故将配置文件中model中的num-classes进行修改就可以进行训练。
2.2 模型构建
最后以ssd_mobilenetV1为例讲解源码中的model构建关键点
问题一:模型怎么知道用的是ssd_mobilenetV1模型?
代码三builders/model_build.py:模型初始化部分,获取配置文件中的模型初始化超参数等信息
最开始由trainer.py里的create_model_fn方法里,追溯到它是在train.py中定义的方法,有第一个model_builder.build参数,
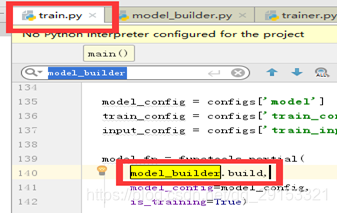
继续追踪builders/model_build.py代码,由下面代码可知与配置文件里的model配置参数有关,此处为ssd,并且后面有type: ‘ssd_mobilenet_v1’,故后面展开的是ssd_mobilenetV1模型的构建。
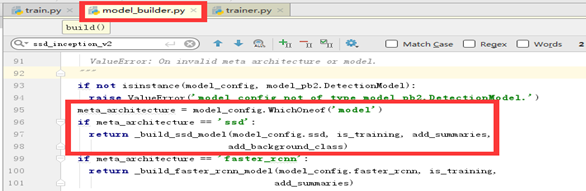
问题二:模型构建的主要部分在哪里?
代码四meta_architectures/ssd_meta_arch.py:模型框架类的构造,含preprocess,predict,postprocess,loss,restore_map等,重点关注predict部分
代码五models/ssd_mobilenet_v1_feature_extractor.py、代码六models/feature_map_genetors.py:特征feature_maps的生成部分,前者主要继承mobilenetv1框架,后者在mobilenetv1加一些卷积等操作,实现具体构造特征feature_maps。
该段操作在meta_architectures/ssd_meta_arch.py中,首先定义类及参数,里面包含基本的preprocess,predict,postprocess,loss,restore_map操作。并且可以看出SSDMetaArch这个类继承于model.DetectionModel。
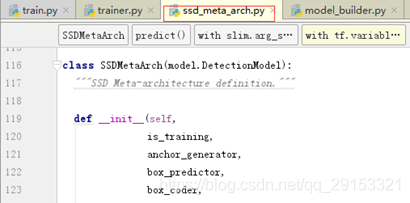
已知模型网络结构一般会出现predict操作(meta_architectures/ssd_meta_arch.py第343行)中,如果需要对模型结构进行微调需要修改predict代码,由prediction_dict(一般为predict模块重要输出)跟踪到_feature_extractor出,进而跟踪它在models/ssd_mobilenet_v1_feature_extractor.py中进行了定义(第383行跟踪到)。
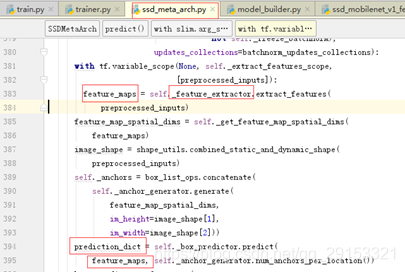
接下来这部分才是模型的网络结构部分,可以着重看这部分代码。由上面跟踪到models/ssd_mobilenet_v1_feature_extractor.py中的extract_features方法才是模型网络结构框架的主要代码,from_layer应该对应ssd_mobilenetV1中在6个层上进行feature map特征提取进行预测,对应配置文件中的num_layers,可以看出模型在mobilenet的11层、13层产生了feature map,与ssd_mobilenetV1模型结构相符,use_depthwise代表使用的是dw深层卷积,是mobilenet新提出来的卷积结构。
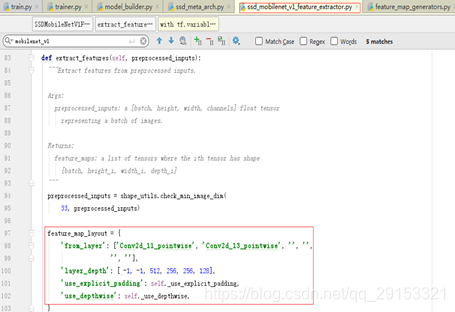
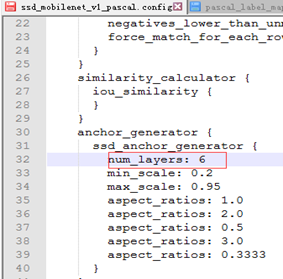
可以看出配置文件该部分是核心部分(feature map特征提取层),num_layers表示提取6层特征,不同的aspect_ratios代表不同框大小,共有6个default boxes(初始预测框大小,aspect_ratios=1.0产生两个default boxes,其他各一个),框大小计算如下:

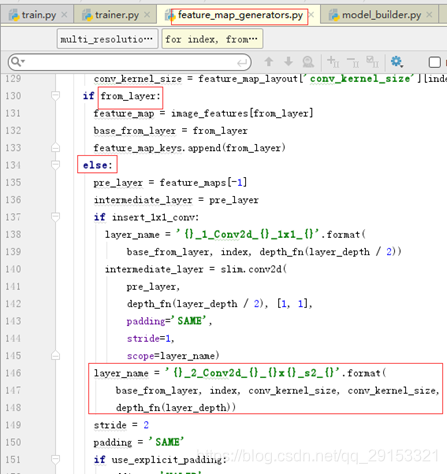
紧接着上面models/ssd_mobilenet_v1_feature_extractor.py,这部分调用了mobilenetv1的图模型,并且可以看出最后点是Conv2d_13_pointwise,也是mobilenetv1图模型的最后一个节点,如下:

从上面可以看到feature_maps(上图代码125行)的细节调用了models/feature_map_genetors.py模块的multi_resolution_feature_maps方法,这里面包含了提取特征层feature_maps的生成,包含了一些卷积操作,可以细看,每个特征层由在最后一层后面加两个普通卷积层而来,尺寸分别为11,33,深度每次不一样,参考ssd_mobilenetv1的框架结构。
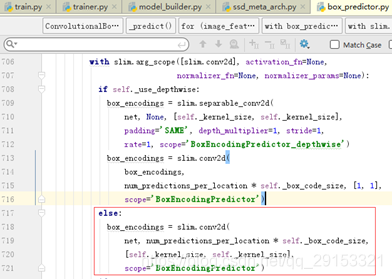
代码七core/box_predictor.py:在上一步构造完feature_maps后,使用这些层实现(框)回归和分类
feature_maps构造成功之后,将会使用它进行更重要的操作–回归和分类,主要在core/box_predict.py(上一级是meta_architectures/ssd_meta_arch.py)中,在feature_maps层的基础上进行回归和分类,具体实现就是在每层特征层后面再多加一个卷积操作。
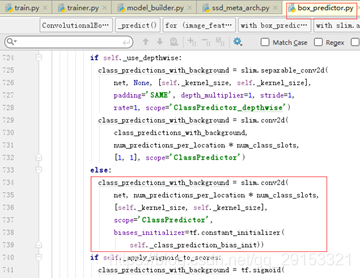
问题三:模型能否从0开始训练?
模型可以从0开始训练,这时需将训练方法slim.learning.train(trainer.py中)中的init_fn=init_fn参数去掉,即不使用训练好的checkpoint文件预训练模型。
3 模型优化
上面讲解了很多ssd模型的原理,通过查阅资料得知ssd模型的优化主要在三方面:
-
数据增强
该部分已经完成,可以将图片在输入模型前增加一些增强性样本,比如增加一些旋转、高斯模糊、高斯噪声等的新样本进入训练; -
feature map个数或位置改变
打印出源代码中的feature_maps特征提取层如下,前两个map卷积层深度(512,1024)对应下图中(models/ssd_mobilenet_v1_feature_extractor.py)layer_depth的前两位(-1,-1),后四个map卷积层深度(512,256,256,128)对应下图中(models/ssd_mobilenet_v1_feature_extractor.py)layer_depth的后四位(512,256,256,128),并且它们与预训练模型checkpoint文件内变量的参数要保持一致。

feature map个数:由于自己的训练集样本数较少,因此不需要使用较多的特征层,可以减少一些feature map个数,除了修改配置文件中的num_layers,比如改为5,还要修改模型的框架结构models/ssd_mobilenet_v1_feature_extractor.py,可以自建函数print_tensors_in_checkpoint_file输出TensorFlow中checkpoint内变量辅助查看,尝试把最后一个特征层去掉代码正常运行(红色框): -
default boxes个数改变
由于自己的训练集样本数较少,一般将配置文件中aspect_ratios的个数减少,比如去掉aspect_ratios=3和1/3,这样能加快训练速度,最后用自己的数据集证明该操作并不影响最终的检测结果
总结
除了以上方法外,通过以上的源代码分析知道feature_maps层的框架构造非常重要,因此可以通过改变feature_maps来改变模型的结构,比如使用dw卷积(源代码中使用的是普通卷积),或者增加、减少卷积层,或者修改继承mobilenetv1的部分卷积层等操作,都可以实现模型的修改,但是此时就不能用预训练模型。
4 查看checkpoint内变量的方法:
def print_tensors_in_checkpoint_file(file_name, tensor_name):
"""Prints tensors in a checkpoint file.
If no `tensor_name` is provided, prints the tensor names and shapes
in the checkpoint file.
If `tensor_name` is provided, prints the content of the tensor.
Args:
file_name: Name of the checkpoint file.
tensor_name: Name of the tensor in the checkpoint file to print.
"""
try:
reader = tf.train.NewCheckpointReader(file_name)
if not tensor_name:
print(reader.debug_string().decode("utf-8"))
else:
print("tensor_name: ", tensor_name)
print(reader.get_tensor(tensor_name))
except Exception as e: # pylint: disable=broad-except
print(str(e))
if "corrupted compressed block contents" in str(e):
print("It's likely that your checkpoint file has been compressed "
"with SNAPPY.")
输出checkpoint部分内变量如下:

