版权声明:欢迎转载,请注明来源 https://blog.csdn.net/linghugoolge/article/details/88356711
一、目的
NLP,使用LSTM对评论进行情感分析
二、流程
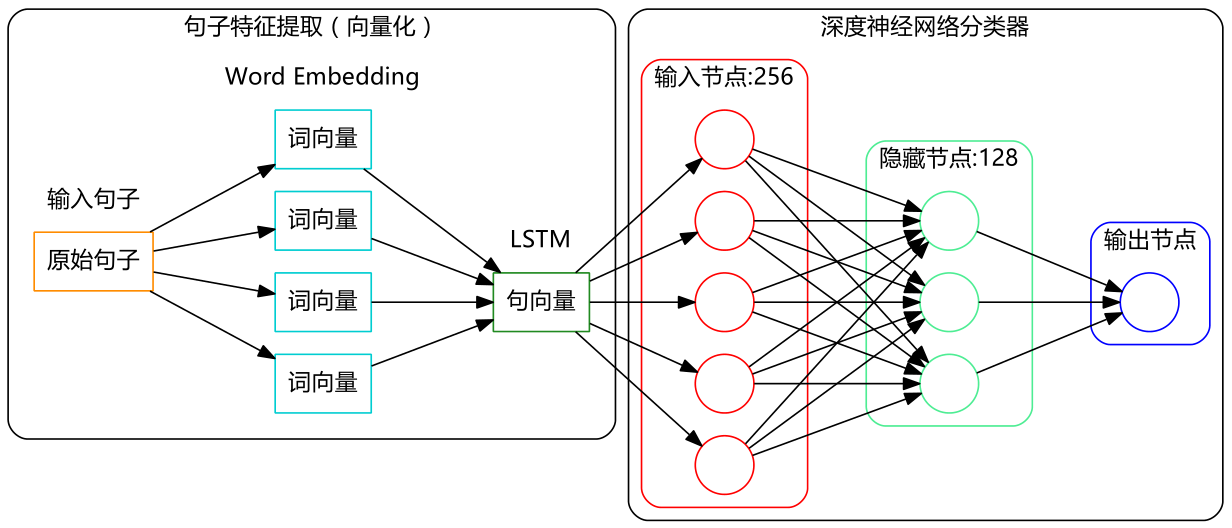
0、标注语料收集
下面是我的语料和代码。读者可能会好奇我为什么会把这些“私人珍藏”共享呢?其实很简单,因为我不是干这行的哈,数据挖掘对我来说只是一个爱好,一个数学与Python结合的爱好,因此在这方面,我不用担心别人比我领先哈。
语料下载:sentiment.zip
采集到的评论数据:sum.zip
来源:https://spaces.ac.cn/archives/3414
1、word2vec
作用:将词转化为计算机可以处理的向量,直接ont-hot编码会过于稀疏,使用google开源的word2vec工具进行处理
简介:https://blog.csdn.net/linghugoolge/article/details/88356692
转化方法:首先转为ont-hot,之后压缩到低维,使用浅层神经网络

2、代码
import pandas as pd #导入Pandas
import numpy as np #导入Numpy
import jieba #导入结巴分词
from keras.preprocessing import sequence
from keras.optimizers import SGD, RMSprop, Adagrad
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM, GRU
from sklearn import metrics
from __future__ import absolute_import #导入3.x的特征函数
from __future__ import print_function
neg=pd.read_excel('neg.xls',header=None,index=None)
pos=pd.read_excel('pos.xls',header=None,index=None) #读取训练语料完毕
pos['mark']=1
neg['mark']=0 #给训练语料贴上标签
pn=pd.concat([pos,neg],ignore_index=True) #合并语料
neglen=len(neg)
poslen=len(pos) #计算语料数目
cw = lambda x: list(jieba.cut(x)) #定义分词函数
pn['words'] = pn[0].apply(cw)
comment = pd.read_excel('sum.xls') #读入评论内容
#comment = pd.read_csv('a.csv', encoding='utf-8')
comment = comment[comment['rateContent'].notnull()] #仅读取非空评论
comment['words'] = comment['rateContent'].apply(cw) #评论分词
d2v_train = pd.concat([pn['words'], comment['words']], ignore_index = True)
w = [] #将所有词语整合在一起
for i in d2v_train:
w.extend(i)
dict = pd.DataFrame(pd.Series(w).value_counts()) #统计词的出现次数
del w,d2v_train
dict['id']=list(range(1,len(dict)+1))
get_sent = lambda x: list(dict['id'][x])
pn['sent'] = pn['words'].apply(get_sent) #速度太慢
maxlen = 50
print("Pad sequences (samples x time)")
pn['sent'] = list(sequence.pad_sequences(pn['sent'], maxlen=maxlen))
x = np.array(list(pn['sent']))[::2] #训练集
y = np.array(list(pn['mark']))[::2]
xt = np.array(list(pn['sent']))[1::2] #测试集
yt = np.array(list(pn['mark']))[1::2]
xa = np.array(list(pn['sent'])) #全集
ya = np.array(list(pn['mark']))
print('Build model...')
model = Sequential()
model.add(Embedding(len(dict)+1, 1))
model.add(LSTM(1)) # try using a GRU instead, for fun
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(x, y, batch_size=1, nb_epoch=1) #训练时间为若干个小时
pre = model.predict_classes(xt,batch_size=30)
score = model.evaluate(xt,yt,batch_size=30)
print(metrics.classification_report(yt,pre))
print(model.metrics_names)
print( score)