一. 循环神经网络
循环神经网络(recurrent neural network)简称RNN,主要用于处理和预测序列数据,其经典结构如下:
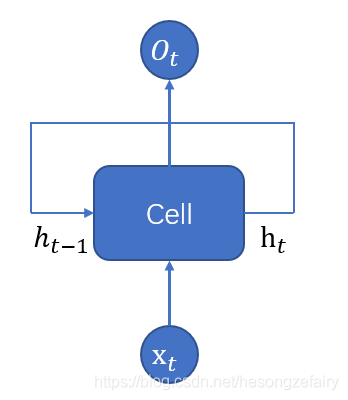
在每一时刻t,RNN会针对该时刻的输入结合当前模型的状态
给出输出
,并更新状态为
。由于Cell中的运算和变量在不同的时刻是相同的,因此RNN理论上可以看作是同一神经网络结构被无限复制的结果。
如果说CNN是在不同的空间位置共享参数,那么RNN就是在不同的时间位置共享参数,实现处理任意长度的序列。
这里我们可以将上面的结构完全展开如下图,可以清楚的看到RNN在每一个时刻有输入,然后根绝前一时刻
计算出新的状态
,并输出
。RNN当前状态
是根据上一时刻的状态
和输入
共同决定。在t时刻,状态
浓缩了前面输入序列的信息用于输出
时的参考。
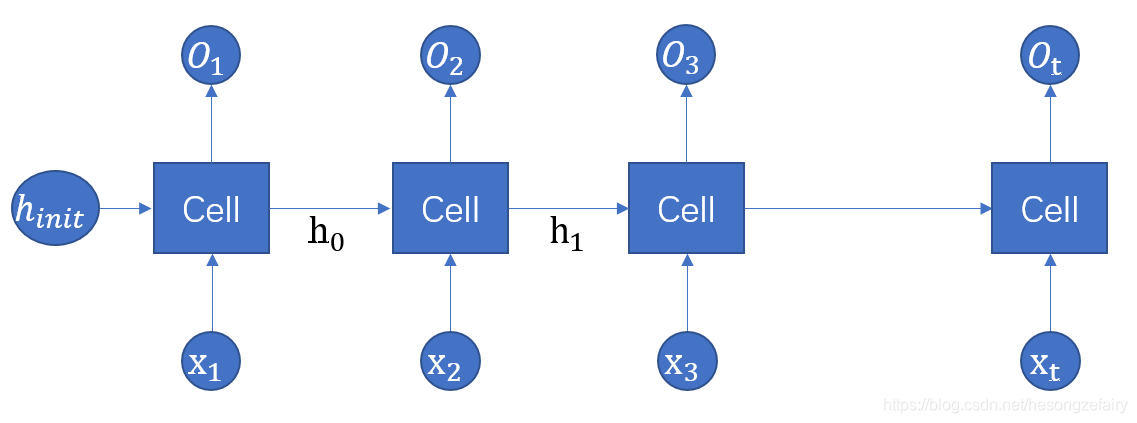
从上图可以看出,RNN对长度为N的序列展开之后,可以看作一个有N个中间层的前馈神经网络,这个前馈神经网络没有循环连接,因此可以直接使用反向传播算法训练,不需要任何特别的优化算法,这样的训练方法称为“沿时间反向传播”。
对于一个序列数据,可以将这个序列上不同时刻的数据依次传入RNN,输出可以是对序列中下一时刻的预测也可以是对当前时刻信息的处理结果,RNN要求每一时刻都有一个输入,但是不一定每个时刻都有输出。
之前说过RNN可以看成是同一神经网络结构的时间序列上被复制多次的结果,这个被复制多次的结构被称为循环体,设计循环体结构就是RNN解决实际问题的关键,下图设计一个 最简单的循环体结构:

RNN的状态是通过一个向量来表示的,这个向量的维度也称为RNN隐藏层的大小(hidden_size)。
举例说明,假设输入向量维度input_size = x,hidden_size = n,,那么循环体中全连接层网络输入大小为n+x,因为该全连接层的输出为当前时刻的状态,于是输出层的节点数也为n。下面以具体数值和代码来展示:
import numpy as np
X = [1, 2] # 模拟输入
state= [0.0, 0.0] # 初始化RNN的状态
w_state = np.asarray([[0.6, 0.3], [0.2, 0.9]])
w_input = np.asarray([0.3, 0.6]) # 分别定义输入和状态的权重
bias = np.asarray([0.3, -0.1])
w_output = np.asarray([[0.3], [2.0]])
bias_out = 0.2
#按照时间顺序执行RNN的前向传播过程
for i in range(len(X)):
before_activation = np.dot(state, w_state) + X[i] * w_input + bias
state = np.tanh(before_activation) # 状态更新
final_output = np.dot(state, w_output) + bias_out
print("before_activation = %s \n state = %s \n output = %s"
% (before_activation, state, final_output))输出: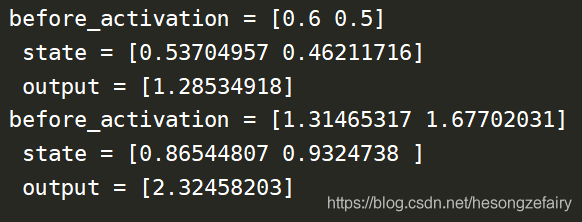
二. 长短时记忆网络LSTM
循环神经网络通过保存历史信息来帮助当前的决策,但是在某些问题中,模型仅需要短期内的信息来执行当前任务,例如预测短语“大海的颜色是蓝色”中最后一个单词“蓝色”时,模型并不需要记忆这个短语之前更长的上下文信息。
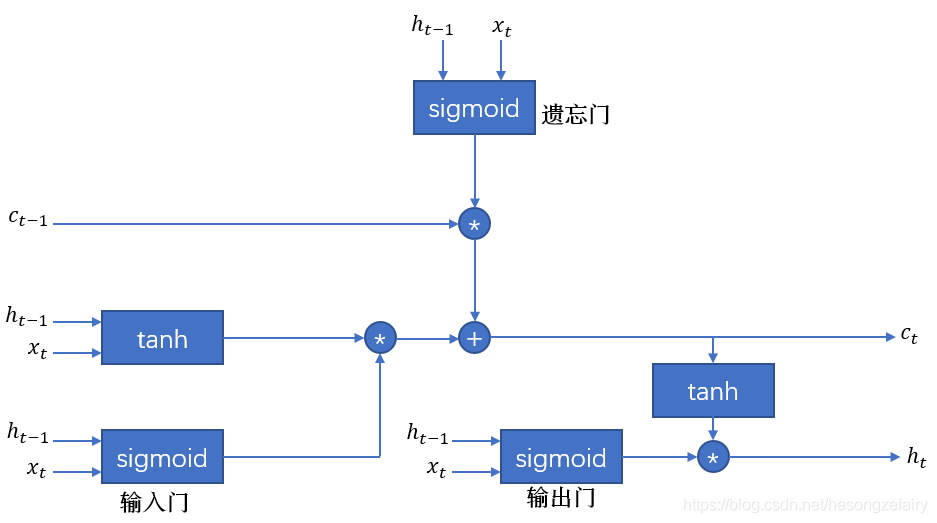
长短时记忆网络(long short-term memory,LSTM)就是为了解决这样的长期依赖问题,LSTM拥有三个门结构;
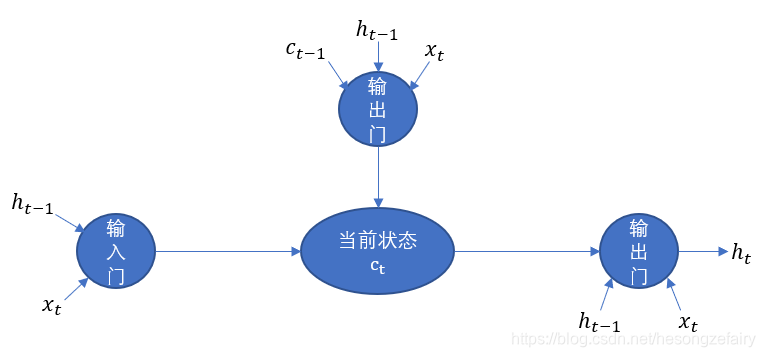
LSTM通过“门”结构让信息有选择性的影响循环神经网络每个时刻的状态,那么“门”的本质实际上是使用sigmoid和一个按位做乘法的操作,之所以称为“门”是因为使用sigmoid作为激活函数的全连接层会输出0-1之间的数值,描述当前输入有多少信息量可以通过这个结构,这个功能就类似一扇门,当门打开(sigmoid输出为1)全部信息可以通过,当门关闭(sigmoid输出为0),任何信息无法通过。
那么现在我们假设网络处于t时刻,模型已经记忆了t时刻以前的信息
遗忘门:
根据输入和上t-1时刻输出
决定
中哪一部分的记忆需要遗忘
遗忘系数:
将遗忘系数和记忆按位相乘,那么f向量取值接近0的维度上的信息相乘就会变得非常小(遗忘),而f向量取值接近1的维度上信息就会保留。
输入门:
当网络遗忘了部分之前的信息之后,需要在t时刻补充新的需要记忆的信息,根据输入和上t-1时刻输出
决定哪些信息加入新的状态
中。
记忆系数:
输入值:
将输入值和记忆系数按位相乘,同遗忘门一样,会从输入中保留需要保留的信息
更新记忆状态:
输出门:
计算出最新的记忆状态后,需要再计算出当前时刻的输出
,根绝最新状态
、上一时刻的输出
和当前输入
共同决定
。
输出系数:
输出:
整体的流程图如下:
在Tensorflow中,LSTM结构很方便就能够实现:
import tensorflow as tf
#定义LSTM结构
hidden_size = 512
batch_size = 10
time_step = 20
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_size)
#初始化状态
state = lstm.zero_state(batch_size, tf.float32)
loss = 0.0
for i in range(time_step):
# 在第一个时间步声明LSTM中变量,之后都是复用之前定义好的变量
if i > 0:
tf.get_variable_scope().reuse_variables()
# 每个时刻将输入current_input(xt)和state传入定义的LSTM结构得到
# 当前时刻的输出ht和更新后的state(c,h)
# 输出ht给其他层,state给下一时刻
lstm_output, state = lstm_cell(current_input, state)
# 当前时刻输出传入全连接层得到最后输出
final_output = fully_connected(lstm_output)
#计算损失
loss += calc_loss(final_output, label)三. 双向RNN、深层RNN、RNN的dropout
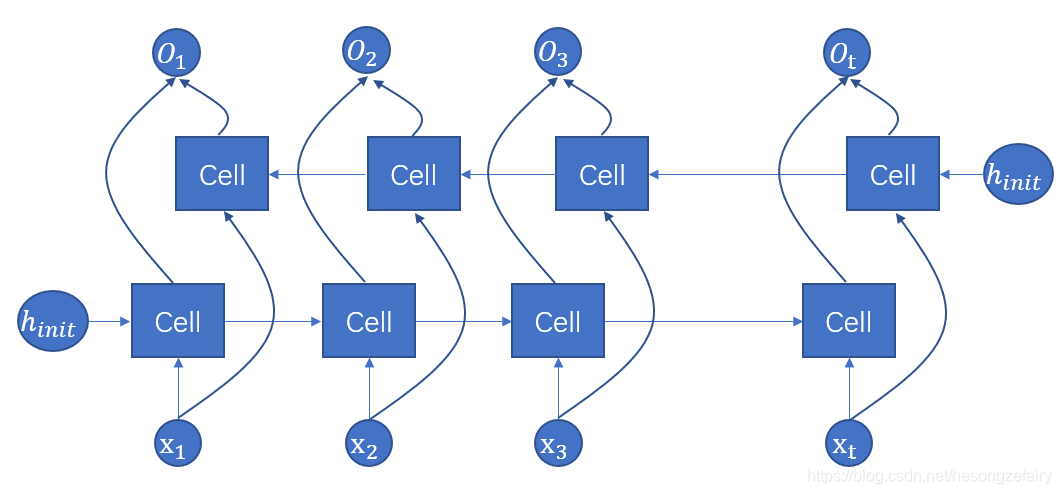
前面提及的网络都是按照时间线单向传播,但是在有些问题中,当前时刻的输出不仅和之前的状态有关也和之后的状态有关,这就需要使用双向RNN来解决问题。双向RNN是由两个独立的RNN叠加而成,输出由这两个RNN的输出拼接而成。
深层RNN可以在网络中设置多个循环层,将每层的输出传给下一层进行处理,以提取更高层的信息。
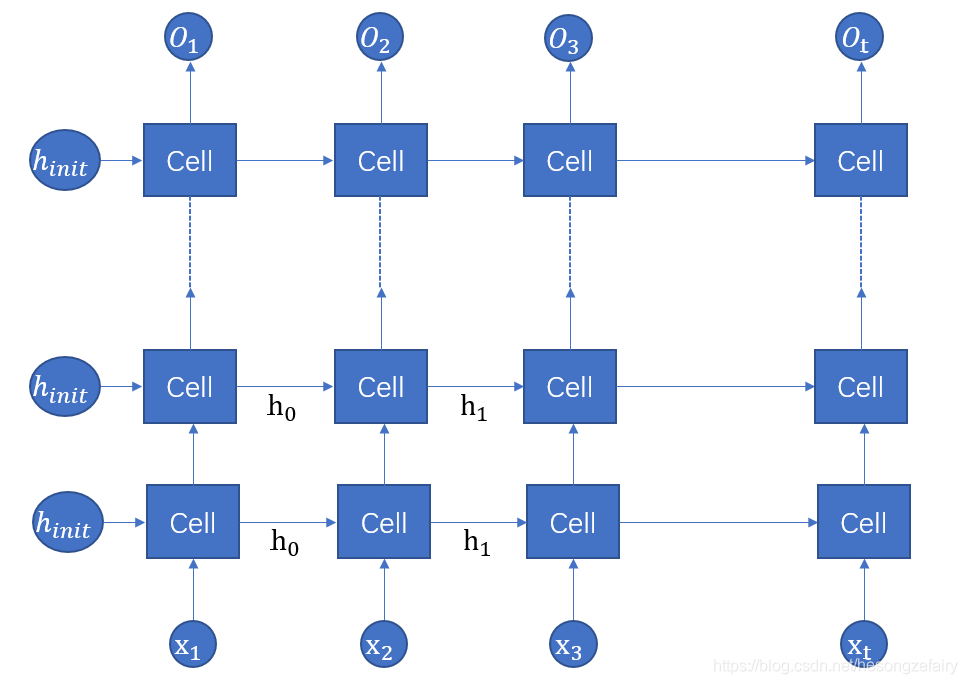
Tensorflow中可以很方便的实现深层RNN:
import tensorflow as tf
#定义LSTM结构
hidden_size = 3
batch_size = 1
time_step = 5
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell
# 创建多层
num_layer = 3
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(hidden_size) for _ in range(num_layer)])
#初始化状态
state = stacked_lstm.zero_state(batch_size, tf.float32)
for i in range(time_step):
# 在第一个时间步声明LSTM中变量,之后都是复用之前定义好的变量
if i > 0:
tf.get_variable_scope().reuse_variables()
# 每个时刻将输入current_input(xt)和state传入定义的LSTM结构得到
# 当前时刻的输出ht和更新后的state(c,h)
# 输出ht给其他层,state给下一时刻
lstm_output, state = stacked_lstm(current_input, state)
# 当前时刻输出传入全连接层得到最后输出
final_output = fully_connected(lstm_output)
#计算损失
loss += calc_loss(final_output, label)RNN中的dropout和CNN中的dropout类似,但是RNN的dropout一般只在不同层的RNN之间,同层的RNN之间不使用dropout。
import tensorflow as tf
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell
# 使用DropoutWrapper类来实现dropout功能,通过两个参数来控制dropout的概率
# 参数input_keep_prob 控制输入的dropout概率
# 参数output_keep_prob控制输出的dropout概率
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.DropoutWrapper(lstm_cell(hidden_size)) for _ in range(num_layer)])在lstm_cell上再封装一层dropout即可。
