知识储备:
Logistic回归进行分类的主要思想:根据现有数据对分类边界线建立回归公式,以此进行分类。训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化算法。
数学基础:
Sigmoid函数:一种阶跃函数,用于接受所有的输入然后预测出类别,相较于单位阶跃函数在0附近的曲线变化较为平滑易于处理。
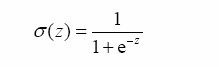
Sigmoid函数的输入记为z,由下面公式得出:
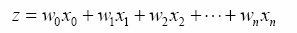
其中x为分类器的输入数据,w为最佳参数。
梯度上升法:
要找到某个函数的最大值,最好的方法是沿着函数的梯度进行寻找。函数f(x,y)的梯度表示如下:
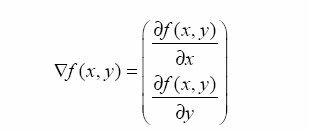
设步长为α,则梯度上升法迭代公式为:

梯度下降法:将梯度上升法中的+变为-,用于求函数的最小值。
Logistic回归优缺点:
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
分类器工作步骤:
1.加载包含特征值的训练集数据列表dataMat,包含训练集数据分类情况的标签列表labelMat.
2.将dataMat,labelMat转换为NumPy矩阵,根据给定的步长与迭代次数计算回归系数。
3.将最佳的回归系数与测试样本的特征值带入sigmoid函数,根据返回的值判断测试样本所属的类。
代码学习:
logistic回归梯度上升优化算法:
#便利函数,加载数据集并对数据集进行预处理
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
#dataMat的每一行为一个列表,列表包含了该样本各个特征的取值
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
#labelMat保存每个样本的分类情况
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
#Sigmoid计算函数
def sigmoid(inX):
return 1.0/(1+exp(-inX))
#梯度上升算法计算函数
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #转为NumPy矩阵
labelMat = mat(classLabels).transpose() #转为NumPy矩阵并转置
m,n = shape(dataMatrix) #返回矩阵行列数
alpha = 0.001 #步长
maxCycles = 500 #迭代次数
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights) #矩阵乘法
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose()* error
return weights对于倒数第二到第四行代码较难于理解,可以参考一个知乎上的问答:
https://www.zhihu.com/question/23503568
一种改进方法是一次仅用一个样本点来更新回归系数,该方法称为随机梯度上升算法。该算法没有矩阵转换的过程,变量数据类型都为NumPy数组。

随机梯度上升算法:
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights)) #h变为数值
error = classLabels[i] – h #error变为数值
weights = weights + alpha * error * dataMatrix[i]
return weights改进的随机梯度上升算法:
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m) #以样本个数为大小的数组
for i in range(m):
#步长随着j与i增大而减小
alpha = 4/(1.0+j+i)+0.0001
#随机取样本索引来更新回归系数,减少周期性的波动
randIndex = int(random.uniform(0,len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights总结
Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法来完成。在最优化算法中,最常用的就是梯度上升算法,而梯度上升算法又可以简化为随机梯度上升算法。
机器学习的一个重要问题就是如何处理缺失数据。这个问题没有标准答案,取决于实际应用中的需求。现有一些解决方案,每种方案都各有优缺点。