注:此系列文章里的部分算法和深度学习笔记系列里的内容有重合的地方,深度学习笔记里是看教学视频做的笔记,此处文章是看《机器学习实战》这本书所做的笔记,虽然算法相同,但示例代码有所不同,多敲一遍没有坏处,哈哈。(里面用到的数据集、代码可以到网上搜索,很容易找到。)。Python版本3.6
机器学习十大算法系列文章:
机器学习实战笔记1—k-近邻算法
机器学习实战笔记2—决策树
机器学习实战笔记3—朴素贝叶斯
机器学习实战笔记4—Logistic回归
机器学习实战笔记5—支持向量机
机器学习实战笔记6—AdaBoost
机器学习实战笔记7—K-Means
此系列源码在我的GitHub里:https://github.com/yeyujujishou19/Machine-Learning-In-Action-Codes
一,算法原理:
Logistic 回归是二分类任务的首选方法,它输出一个 0 到 1 之间的离散二值结果。简单来说,它的结果不是 1 就是 0。癌症检测算法可看做是 Logistic 回归问题的一个简单例子,这种算法输入病理图片并且应该辨别患者是患有癌症(1)或没有癌症(0)。
为了实现Logistic回归分类器,可以在每个特征上都乘以一个回归系数,然后把所有的结果相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1的数值。大于0.5分入1类,否则归入0类。Sigmoid函数的输入记为zz,有下面公式得出:
z=w0x0+w1x1+w2x2+...+wnxn采用向量写法,上述公式可写成z=wT*x,,其中向量x是分类器的输入数据,向量w是要寻找的最佳回归系数。
Sigmoid函数计算公式和函数图形如下:

梯度上升算法基本思想:要找到某个函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为∇,则函数f(x,y)的梯度由下式表示:
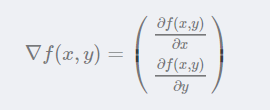
这个梯度意味着沿x方向移动∂f(x,y)/∂x,沿y方向移动∂f(x,y)/∂y。且函数f(x,y)在待计算的点上有定义且可微。梯度算子总是指向函数值增长最快的方向。这里说的是移动方向,而未提到移动量的大小。该量值称为步长,记做α。用向量表示,梯度上升法的迭代公式如下:
w:=w+α*∇w*f(w)该公式会一直迭代下去,直至达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
二,算法的优缺点:
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
三,实例代码:
1)梯度上升算法具体实现:
from numpy import *
#加载数据
def loadDataSet():
dataMat = []; labelMat = [] #数据,标签
fr = open('testSet.txt')
for line in fr.readlines(): #逐行读取
lineArr = line.strip().split() #去除字符串首尾空格后拆分
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))
#梯度上升算法
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #转换成Numpy矩阵
labelMat = mat(classLabels).transpose() #转换成Numpy矩阵
m,n = shape(dataMatrix) #m是dataMatrix的行,n是dataMatrix的列
alpha = 0.001 #学习率
maxCycles = 500 #计算轮数
weights = ones((n,1)) #3行一列
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights) #矩阵相乘,100行*3列乘以3行1列
error = (labelMat - h) #矢量减法,实际值-计算值
weights = weights + alpha * dataMatrix.transpose()* error #更新权值
return weights
#测试
import logRegres
dataArr,labelMat=loadDataSet() #加载数据
rst=gradAscent(dataArr,labelMat) #梯度上升算法
print(rst)代码结果:

2)分析数据,画出决策边界:
上面已经解出了一组回归系数,它确定了不同类别数据之间的分割线。那么怎样画出该分割线,从而使得优化的过程便于理解呢?下面将解决这个问题。
#画出数据集和Logistic回归最佳拟合直线的函数
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
#测试
dataArr,labelMat=loadDataSet() #加载数据
weights=gradAscent(dataArr,labelMat) #梯度上升算法
plotBestFit(weights.getA()) # getA()将numpy矩阵转换为数组代码结果:

3)训练算法,随机梯度上升算法
#随机梯度上升算法
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
#测试
dataArr,labelMat=loadDataSet() #加载数据
weights=stocGradAscent0(array(dataArr),labelMat) #随机梯度上升算法
plotBestFit(weights) # getA()将numpy矩阵转换为数组代码结果:

从图中可以看到,分类的正确率不是太高。
4)改进的梯度上升算法
#改进的随机梯度上升算法
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
#测试
dataArr,labelMat=loadDataSet() #加载数据
weights=stocGradAscent1(array(dataArr),labelMat) #随机梯度上升算法
plotBestFit(weights) # getA()将numpy矩阵转换为数组代码结果:

5)实例,从疝气病症预测病马的死亡率
使用Logistic回归方法进行分类并不需要做很多工作,所需做的只是把测试集上每个 特征向量以最优化方法得来的回归系数,再将该乘积结果求和,最后输入到Sigmoid函数 中即可。如果对应的Sigmoid值大于0.5就预测类别标签为1,否则为0。
#Logistic回归分类函数
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
#训练并测试数据
def colicTest():
#读取训练集和测试集
frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines(): #按行读取
currLine = line.strip().split('\t') #去除空格后拆分数据
lineArr =[]
for i in range(21): #提取特征数据
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr) #将特征加入训练集
trainingLabels.append(float(currLine[21])) #将标签加入标签集
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000) #随机梯度上升算法训练
errorCount = 0; numTestVec = 0.0 #错误数量,测试集数量
for line in frTest.readlines(): #按行读取数据
numTestVec += 1.0 #测试集数量加1
currLine = line.strip().split('\t') #去除空格后拆分数据
lineArr =[]
for i in range(21): #提取特征数据
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]): #判断类别
errorCount += 1
errorRate = (float(errorCount)/numTestVec) #错误数除以总数,得到正确率
print ("the error rate of this test is: %f" % errorRate)
return errorRate
#多次测试,求平均结果
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print ("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests)))
#测试
multiTest()代码结果:

Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以用最优化算法 完成。在最优化算法中,最常用的就是梯度上升算法,而梯度上升算法又可以简化为随机梯度上升算法。 随机梯度上升算法与梯度上升算法效果相当,但占用更少的计算资源。此外,随机梯度上升是一个 在线算法,它可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批处理运算。 机器学习的一个重要问题就是如何处理缺失数据。这个问题没有标准答案,取决于实际应用中的需 求。现有一些解决方案,每种解决方案都各有优缺点。
欢迎扫码关注我的微信公众号
