【文章来源】
Feng X, Huang L, Tang D, et al. A Language-Independent Neural Network for Event Detection[C]// Meeting of the Association for Computational Linguistics. 2016:66-71.
【原文链接】
一种与语言无关的事件检测神经网络:http://wing.comp.nus.edu.sg/~antho/P/P16/P16-2011.pdf
摘要
由于在各种上下文中编码单词语义的困难,事件检测仍然是一个挑战。 以前的方法很大程度上依赖于语言特定知识和预先存在的自然语言处理(NLP)工具。 但是,与英语相比,并非所有语言都有这样的资源和工具。 更有前途的方法是从数据中自动学习有效特征,而不依赖于特定语言的资源。 在本文中,我们开发了一个混合神经网络来捕获特定上下文中的序列和块信息,并使用它们来训练多种语言的事件检测器,而不需要人工编码任何特性。实验表明,我们的方法可以为多种语言(英语,中文和西班牙语)实现稳健,高效和准确的结果。
1 介绍
事件检测旨在提取事件触发器(通常是单个动词或名词)并将它们精确地分类为特定类型。这是事件提取的一个关键且非常具有挑战性的子任务,因为相同的事件可能以各种触发器表达式的形式出现,而表达式可能在不同的上下文中表示不同的事件类型。图1显示了两个例子。在S1中,“release”是动词的概念和“Transfer-Money”事件的触发器,而在S2中,“release”是名词的概念和“Release-Parole”事件的触发器。
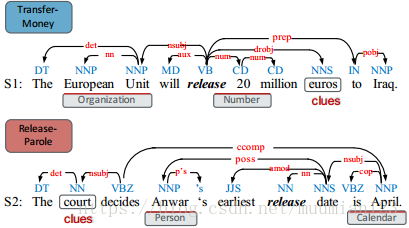
图1 事件类型和句法分析结果的示例句子。
大多数先前的方法(Ji等人,2008; Liao等人,2010; Hong等人,2011; Li等人,2013; Li等人,2015b)将事件检测视为分类问题并且设计了很多词汇和句法特征。尽管这些方法表现得相当好,但是特征通常来自特定语言的资源以及预先存在的自然语言处理工具箱(例如,名称标记器和依赖性解析器)的输出,这使得这些方法难以应用于不同的语言。序列和块是用于事件检测的两种有意义的与语言无关的结构。例如,在S2中,当预测触发候选“释放”的类型时,诸如“court法院”的前向序列信息可以帮助分类器标签“释放”作为“释放 - 假释”事件的触发器。但是,对于特征工程方法,很难在“court”和“release”之间建立关系,因为它们之间没有直接的依赖路径。此外,考虑到S1,“欧盟”和“2000万欧元”是两个块,这表明这句话与组织和金融活动有关。这些线索非常有助于推断“释放”作为“转账”事件的触发器。但是,分块和解析器仅适用于少数高源语言,其性能差异很大。
最近,深度学习技术已被广泛用于复杂结构建模,并被证明对许多NLP任务有效,例如机器翻译(Bahdanau等,2014),关系提取(Zeng等,2014)和情感分析(Tang 等,2015a)。双向长期短期记忆(Bi-LSTM)模型(Schuster等,1997)是一种双向递归神经网络(RNN)(Mikolov等,2010),它可以捕获每个单词的前后上下文信息。卷积神经网络(CNN)(LeCun等,1995)是另一种有效的模型,用于提取语义表示和捕获平面结构中的显着特征(Liu等,2015),例如块。在这项工作中,我们开发了一个混合神经网络,包含两种类型的神经网络:Bi-LSTM和CNN,以从特定的上下文中建模序列和块信息。利用单词语义表示,我们的模型可以摆脱手工制作的功能,因此很容易适应多种语言。
我们针对各种语言的事件检测任务评估我们的系统,其中可以获得地面实况事件检测注释。在英语事件检测任务中,与现有技术相比,我们的方法实现了73.4%的F值,与最先进的相比平均3.0%的绝对改进。对于中文和西班牙文,实验结果也具有竞争力。我们证明了我们的组合模型在跨语言的泛化性能方面优于传统的基于特征的方法,原因在于:(i)通过捕获序列和块信息来模拟每个单词的语义表示的能力;(ii)使用文字嵌入来引发触发候选人的更一般的表示。

2 我们的方法
在本节中,我们介绍了一种混合神经网络,它结合了双向LSTM(BiLSTM)和卷积神经网络来学习句子中每个单词的连续表示。该表示用于预测该单词是否是事件触发器。具体来说,我们首先使用Bi-LSTM来编码每个单词的语义及其前后信息。然后,我们添加一个卷积神经网络来捕获来自本地上下文的结构信息。
2.1 Bi-LSTM
在本节中,我们将介绍用于事件检测的双向LSTM模型。 Bi-LSTM是一种双向递归神经网络(RNN),它可以同时模拟单词表示与其前后信息。 Word表示可以自然地被视为检测触发器及其事件类型的功能。如(Chen等,2015)所示,我们将整个句子的所有单词作为输入,并通过查找单词嵌入来转换每个标记。具体来说,我们使用SkipGram模型预先训练单词嵌入来表示每个单词(Mikolov等,2013; Bahdanau等,2014)。
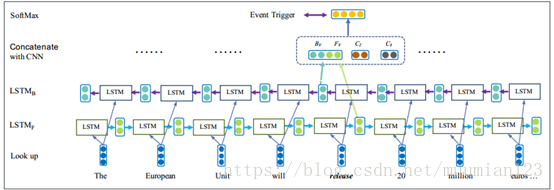
图2 我们的事件触发器提取模型的说明(此处触发器候选是“release”)。 Fv和Bv是Bi-LSTM的输出,C2,C3是CNN的输出,具有宽度为2和3的卷积滤波器。
我们在图2中给出了用于事件触发器提取的Bi-LSTM的细节。可以看出,Bi-LSTM由两个LSTM神经网络组成,一个是前向LSTMF模型,另一个是后向LSTMB模型,分别对下面的上下文进行建模。LSTMF的输入是前面的上下文以及单词作为候选触发词,并且LSTMB的输入是以下上下文加上作为触发候选的单词。我们从句子的开头到结尾运行LSTMF,并从句子的结尾到句子的开头运行LSTMB。然后,我们将LSTMF的输出Fv和LSTMB的Bv连接为Bi-LSTM的输出。人们还可以尝试对LSTMF和LSTMB的最后隐藏向量进行平均或求和作为替代。
2.2 卷积神经网络
由于卷积神经网络(CNN)擅长从一系列对象中捕获显着特征(Liu 等,2015),我们设计了一个CNN来捕获一些局部块。在以往的研究中,该方法被用于事件检测(Nguyen和Grishman,2015; Chen等,2015)。具体来说,我们使用具有不同宽度的多个卷积滤波器来产生局部上下文表示。原因是它们能够捕获各种粒度的n-gram的局部语义,这被证明是事件检测的强大功能。在我们的工作中,宽度为2和3的多个卷积滤波器在一个句子中编码双格bigrams和三格trigrams的语义。这些局部信息还可以帮助我们的模型修复由于词汇歧义而产生的一些错误。
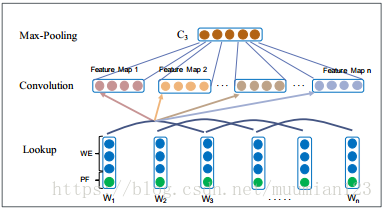
图3 CNN结构
图3中给出了具有三个卷积滤波器的CNN的图示。让我们表示由n个单词组成的句子,并且每个单词
被映射到其嵌入表示
。另外,我们添加位置特征(PF),其被定义为当前单词和触发候选之间的相对距离。卷积滤波器是具有共享参数的线性层列表。我们将卷积滤波器的输出馈送到MaxPooling层,并获得具有固定长度的输出向量。
2.3 输出
最后,我们从Bi-LSTM中学习到双向序列特征:F和B,以及局部上下文特征:C2和C3,它们是具有宽度为2和3的卷积滤波器的CNN的输出,如单个矢量O = [F, B, C2, C3]。然后,我们利用softmax方法来识别触发候选者并将每个触发候选者分类为特定事件类型。
2.4 训练
在我们的模型中,损失函数是事件触发器识别和触发器分类的交叉熵误差。我们初始化所有参数以形成均匀分布U(-0.01,0.01)。我们将卷积滤波器的宽度设置为2和3,特征映射的数量为300,PF的维数为5。表1说明了我们实验中三种语言的设置参数(Zeiler,2012)。
3实验
在本节中,我们将描述详细的实验设置并讨论结果。我们用精度(P)、召回率(R)和F-measure (F)来评估所提出的方法在各种语言(英语、汉语和西班牙语)上的应用。表1显示了我们实验中使用的数据集的详细描述。我们将模型缩写为HNN(混合神经网络)。
表1 我们在三种语言的实验中使用的超参数和文档数量

3.1基线方法
我们将我们的方法与以下基线方法进行比较:
- MaxEnt:一种基于特征的基线方法,它训练了一个具有一些词法和句法特征的最大熵分类器(Ji 等,2008);
- 跨事件(Liao等,2010):使用文档级信息来提高ACE事件提取的性能;
- 跨实体(Hong等,2011):使用跨实体推理提取事件;
- 联合模型(Li和 Ji,2014):一种联合结构感知方法,结合多层次语言特征,同时提取事件触发器和参数,以便可以相互改进局部预测;
- 模式识别(Miao and Grishman, 2015),使用模式扩展技术提取事件触发器;
- 卷积神经网络(Chen et al.,2015),利用动态多池卷积神经网络进行事件触发检测。
3.2在英语上的比较
表2 不同的英语事件检测方法的比较
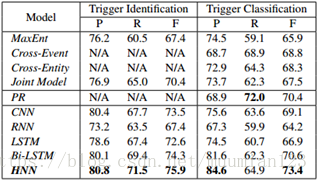
表2显示了ACE2005英语语料库中所有方法的整体性能。我们可以看到,我们的方法明显优于以前的所有方法。 HNN的更好性能可以通过以下原因进一步解释:
(1)与基于特征的方法(如MaxEnt,交叉事件,跨实体和联合模型)相比,基于神经网络的方法(包括CNN,Bi-LSTM,HNN)表现更好,因为它们可以更好地利用单词语义信息,避免错误传播的NLP的工具可能会阻碍事件检测的性能。
(2)Bi-LSTM可以捕获前后序列信息,这比依赖路径更丰富。例如,在S2中,“court”的语义可以通过我们的方法中的前向序列来传递。这是一个重要的线索,可以帮助预测“release释放”作为“ReleaseParole”的触发器。对于基于特征的显式方法,由于属于不同的条款,且之间没有直接的依赖路径,无法建立“法院”与“释放”之间的关系。在我们的方法中,“court法院”的语义可以通过前向序列传递给释放。
(3)跨实体系统实现了更高的召回率,因为它不仅使用句子级信息,还使用文档级信息。它利用事件一致性来基于跨句子推断来预测本地触发器的事件类型。例如,“攻击”事件更可能发生在“杀死”或“死亡”事件而不是“结婚”事件中。然而,这种方法在很大程度上依赖于词法和句法特征,因此精度低于基于神经网络的方法。
(4)RNN和LSTM的表现略差于Bi-LSTM。一个明显的原因是RNN和LSTM只考虑触发器的前面序列信息,这可能会遗漏一些重要的后续线索。再次考虑S1,当提取触发器“释放”时,两个模型将错过以下序列“2000万欧元到伊拉克”。这可能严重阻碍RNN和LSTM用于事件检测的性能。
3.3 在中文上的比较
对于中文,我们遵循以前的工作(Chen 等,2012)并使用语言技术平台(Liu 等,2011)进行分词。
表3 中文事件检测的结果
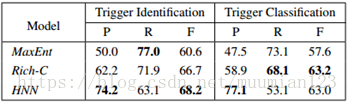
表3显示了我们的模型与现有技术方法之间的比较结果(Li 等,2013; Chen 等,2012)。MaxEnt(Li等,2013)是一种管道模型,它采用人类设计的词法和句法特征。Rich-C由Chen(2012)等人开发,其中还包含中文特色功能,以改善中文事件检测。我们可以看到,我们的方法优于基于人类设计的事件触发器识别特征的方法,并实现了事件分类的可比较的F分数。
3.4 西班牙语提取
表4 西班牙语事件检测的结果
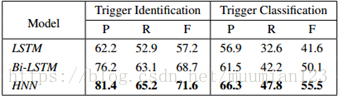
表4显示了我们的方法在西班牙ERE语料库中的表现。结果表明,HNN方法比LSTM和Bi-LSTM表现更好。这表明我们提出的模型可以在多种语言中实现最佳性能,而不是其他神经网络方法。我们没有将我们的系统与其他系统进行比较(Tanev等,2009),因为他们在非标准数据集上报告了结果。
4 相关工作
事件检测是信息提取和自然语言处理中的一个基本问题(Li等, 2013; Chen 等, 2015),其目的在于检测句子的事件触发(Ji等, 2008)。大多数现有方法将此问题视为分类任务,并使用具有手工特征的机器学习方法,例如词法特征(例如,完整单词、pos标签),句法特征(例如,依赖特征)和外部知识特征(WordNet)。还有一些研究利用更丰富的证据,如跨文件(Ji 等, 2008),跨实体(Hong等, 2011)和联合推理(Li和Ji,2014)。
尽管基于特征的方法有效,但我们认为手工设计特性模板通常需要大量的劳动。此外,特征工程需要专业知识和丰富的外部资源,这对于一些低资源语言来说并不总是可用的。此外,理想的方法应该能够自动从数据中学习信息表示,以便它可以很容易地适应不同的语言。近年来,神经网络作为一种从数据中自动学习文本表示的强大方法,在各种NLP任务中取得了良好的性能。
对于事件检测,最近的两项研究(Nguyen和Grishman,2015; Chen等,2015)探索神经网络以学习连续的单词表示,并将其视为推断单词是否是触发器的特征。 Nguyen(2015)提出了一种卷积神经网络,其中实体类型信息和单词位置信息作为额外的特征。然而,他们的系统将上下文限制为固定的窗口大小,这导致长句子的单词语义表示的丢失。我们引入了一个混合神经网络来学习连续的单词表示。与基于特征的方法相比,此方法不需要特征工程,可以直接应用于不同的语言。与以前的神经模型相比,我们保留了卷积神经网络(Nguyen和Grishman,2015)在捕获局部上下文方面的优势。此外,我们还采用了双向LSTM来模拟单词的前后信息,因为人们普遍认为LSTM擅长捕获序列中的长期依赖性(Tang等, 2015b; Li等, 2015a)。
5 结论
本文引入了一种混合神经网络模型,该模型将双向LSTMs和卷积神经网络相结合,以捕获来自特定上下文的序列和结构语义信息,用于事件检测。与传统的事件检测方法相比,我们的方法不依赖于任何语言资源,因此可以轻松应用于任何语言。我们对各种语言(英语,汉语和西班牙语)进行了实验。实验结果表明我们的方法在英语和中文竞争结果中取得了最佳表现。我们还发现双向LSTM在远距离捕获前后上下文时,对触发器提取非常有效。