题目:一种基于混合深度神经网络的位置和方向检测的新颖鲁棒性算法
声明:本篇论文的翻译,目的是为了个人的学习,如果涉及到侵权行为,请评论,我会立即删除。
Abstract(摘要)
通过使用机器视觉评估物体的位置和方向在工业自动化中是重要的。传统的Canny算子和Hough变换边缘检测算法被广泛使用,但其在复杂背景下的准确性的实时目标识别非常有限。在本篇论文中,提出了一种结合单次多盒检测器(SSD)网络和卷积神经网络(CNN)的方法。利用SSD获取对象的边界框以缩小识别范围。卷积神经网络用于检测物体的方向。该方法可以提取样本图像的弱特征。通常,与传统算法相比,所提出的方法大大提高了准确度和识别率。
关键词:物体检测,卷积神经网络,混合深度神经网络
1. Introduction(介绍)
计算机、通信和消费电子(3C)工业[1, 2]在快速发展的技术中变得越来越重要。3C产业是计算机、通信和消费电子的结合。工业机器人是智能制造中最重要的设备之一,如卡车,3C组装,焊接等。它将在未来几年占据全球市场的很大份额,使得对工业机器人的需求[3]日益迫切,机器人行业蓬勃发展。在智能地控制机器人的过程中,获得物体的位置和方向尤为重要[4]。这种普遍的发展趋势导致物体识别算法成为研究的热点。
许多学者对该课题进行了一系列研究。对于物体识别,越来越多的研究人员正在使用神经网络来获得复杂背景下物体的位置和类别。例如,多频天线阵SAR用于估计慢速和快速物体的位置[5,6],基于神经网络的贝叶斯最优方法也可以用于检测物体的位置[7]。另外,当算法中需要方向时,通常使用Canny算子和Hough变换的组合。霍夫变换用于分类级别的对象检测,并且它们的灵活性允许将霍夫变换扩展到诸如对象跟踪和动作识别的新领域。根据[8],传统的获取物体角度的方法通常取决于Canny算子的边缘检测,在图像中搜索并获得物体的边缘。然后将Hough变换[9]应用于边缘点已获得具有最多边缘点的线[10]。线的方向被视为图像的轴方向,因此图像的角度是已知的。除了所有这些因素外,还提出了一种基于Canny算子和改进Hough变换的边缘定位方法,以特定地解决矩形对象的边缘定位问题[11,12]。
虽然这些算法可以实现特定的功能,但它们有许多缺点。用于对象检测的神经网络具有局限性,并且无法确定对象的方向。因此,它必须与其他有效算法结合才能实现方向确定。这样,传统的神经网络算法,以及Canny算子和Hough变换的集成方法,都存在工作过程精度低的问题。当图像处于复杂背景中时,结合Canny算子和Hough变换的方向检测算法并不理想[13],具有很多噪声。此外,该方法存在计算成本高的问题。
基于该方法的局限性,本文提出了一种突破传统预测角度方法局限性的新方法,即通过神经网络进行预测。神经网络[14]可以识别存在噪声和变形的输入模式。利用神经网络,可以通过将多个预处理集成为一个压缩识别过程,从而获得大规模自适应并行处理[15,16]和高度容错[17]的优势。
在本文中,深度神经网络模型SSD(Single Shot MultiBox Detector)[18]用于确定图像中对象的位置。在SSD中,减少的VGG-16预训练模型用作基础网络。每个卷积层中的信道数被设置为原始网络[2]的2到8倍。然后CNN[20]用于实现物体的角度识别和定向解。网络的输入时原始图像和预先标记的标签[21],而提取的特征的特征类型取决于神经网络的连接参数。这些参数在模型训练期间通过其特征学习规则算法自动更新,例如反向传播算法[22,23]。
本文的其余部分组织如下。第2节介绍了使用位置和角度坐标的物体姿态描述。然后介绍了算法中使用的两个神经网络的结构和完成情况,SSD和五层CNN。在第3节中,介绍了网络训练过程,包括数据集的采集,数据集增强策略和几种方法避免过拟合像正则化策略[24]。在第4节中,将CNN的结果与原始Canny算子边缘检测和Hough变换在测量物体角度方面的组合所获得的结果进行比较。讨论和结论在第5节中给出。
2. 位置和方向定位算法
2.1 检测系统的设计
2.1.1. 平面特征的描述性变量
有代表性的3C产品无线电远程单元(RRU)如图1所示。在工厂组装RRU设备后,RRU需要连接电源线和信号线进行测试。在通过工业机器人将连接器插入RRU的电源端口和光纤端口之前,RRU上的电源端口或光纤端口的位置和方向需要通过机器视觉来识别。通过物体的实时和高速识别,工业机器人可以根据插入特征的反馈智能地插入电源连接器或光纤连接器。

二维平面中物体的特征可以用两个平移和一个旋转来描述,因此物体的特征向量可以展示在图1索引(b)的照片中描述为。两个平移运动(x, y)用来描述物体的运动,一个旋转运动
用来描述相对于z轴的旋转角度[25]。在一些应用中,例如视觉伺服,它需要预测用于控制机器人的特征的实时位置和方向。
2.1.2 物体检测框架
在接收到目标图像后,本文提出的检测器使用Single Shot MultiBox方法获得对象的类别和坐标。通过矩形边界框裁剪出图像中的特征对象,然后CNN进行预测[26],以便获得对象的角度信息。因此,机器人能够根据该信息执行相应的后续动作。流程图如图2所示:

2.2 位置和方向的确定算法
2.2.1. 基于SSD网络的位置确定
Single Shot MultiBox (SSD)是Wei Liu和其他学者在2016年提出的一种方法。它是使用单个端到端训练深度神经网络检测图像中物体的一种很好的方法。SSD是一种前馈卷积网络,主要包括移除了全连接层的基本CNN,如VGGNet[27]和MobieNet[28],以及额外的卷积层。主要识别原则是在不同尺寸的各种特征图上的多个位置生成不同尺寸和纵横比的矩形框。SSD将边界框空间离散为每个特征地图位置的一组默认框形状,并使用卷积核() 来预测每个位置的边界框和对象概率[18]。此外,它使用卷积预测器进行得分预测,然后执行非最大抑制以获得最终检测结果。该网络能够组合不同大小的多个特征图的预测,以适应各种尺寸的对象。此外,SSD网络还考虑了检测的准确性和速度。
2.2.2. 基于CNN网络的方向确定
本文介绍了一种利用L2正则化改进的五层卷积神经网络来检测物体的角度。该网络由四个卷积池化层和一个完全连接层组成,如图3所示。每个特征映射对应一个大小为的卷积核。不同的卷积核可以提取图像中包含的不同类型的特征。

卷积层利用卷积核, 图像被分为几个相同大小的像素块,并且每个像素块被视为神经元并执行卷积运算。CNN中定义的权重共享意味着在每个神经元分别执行相同的卷积计算。卷积计算独立于像素块的位置,因此图像中的像素块被相同的处理。另一方面,权重共享可以指数地减少该层中涉及的参数的数量。泄露的Relu函数用作激活函数,以向网络添加非线性元素以增强其表现力,该函数始终跟随卷积层,并且由于空间有限而未在图3中展示出。
池化层是维度减少操作,它保留了图像中的大部分信息。有多种方法,如最大池化,平均池化和随机池化等。在我们的检测系统中,角度检测网络模型中包含的池化层是最大池化层,本地感受野的大小为。具体的过程是在特征图上选择
的本地感受野并且提取其中的最大像素值。特征映射将池化层的输入压缩为小块,其大小为原始大小的四分之一。
在我们的检测系统中,原始图像作为角度检测网络模型的输入,并且通过卷积层和池化层连续提取和组合特征。从底层卷积层的单元层中提取的特征是像角一样的简单低级特征,并且可以重新集成以形成高级特征,因此,网络识别的检测能力大大增强。另外,检测角度是回归问题,因此最终层有全连接层和一个输出神经元构成。通常,最终层的输出是位于输入图像中的对象的倾斜角。
3. 混合深度神经网络的训练
3.1. 获取具有不同特征的数据集的方法
对于网络模型,数据集应足够大,以使模型训练更加高效。这里讨论的不仅是指数据集中的图像数量,还指组件的差异。实质上,数据集的图像应包含不同的对象位置和方向集。它应该在数据集中的组件之间具有足够的差异,以便网络可以从中学习更多的特征并提高模型的泛化能力。我们的检测系统从网络训练数据集的一小部分开始,已获得网络模型的高性能。该模型用于预测剩余数据集并获得结果。如果某个图像的预测结果存在较大差异,则意味着图像与原始数据集中的图像相比具有显著的差异。导致错误预测的图像被分类到数据集之外,并且其余的图像经历相同的操作,直到获得最终的差异数据集。该过程如图4所示:

3.2. 研究避免过拟合现象
3.2.1. 神经网络的过拟合现象
过度你和是神经网络中的典型现象。如果发生这种现象,神经网络的参数通常会非常大,以及它的方差和偏差。这种过拟合现象可以在图5中说明。

在图5中可以清楚看出,预测曲线需要满足所有采样点,并且当过拟合现象发生时,那个拟合曲线像是剧烈的湍流。网络的损失函数和方差特别大,使得估计的参数值特别大。在这种情况下,新测试数据集中的错误可能非常大,导致网络的泛化能力差,并限制了训练网络的应用。因此,采取多种措施避免过度拟合现象也至关重要。
3.2.2. 数据增强
应用大量数据可以有效的防止神经网络在训练网络时过度拟合。然而,角度标签的手动获取非常困难,为了解决这个问题,使用SSD网络的检测结果来构建兴趣数据集。使用兴趣数据集生成随机旋转角度,通过收集所有随机图像来获得增强数据集。增强数据集的图像随机添加了椒盐噪声,以模仿现实中收集的图像。增强数据集的一些噪声样本如图6所示。

3.3. 网络模型的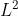 正则化
正则化
正则化是训练网络准确性的另一种有效方式。损失函数写为等式(1):
(1)
网络的输出是对象的角度,因此应将其归类为线性回归问题。为了解决这个问题,L2从[16]的常规形式用于更新参数。损失函数可以重新定义为等式(2):
(2)
通过添加常规项,成本函数不在与网络的预测值和真实值得误差唯一相关,而且与参数
无关。
正则化在成本函数后面直接添加了一个正常项,表示为
函数被定义为等式(3):
(3)
权重越小,网络的复杂性越低,数据处理的效果越好。在实际应用中,与未经调节的网络相比,L2正则化网络[24]预测的效果通常会得到显著改善。
为了避免上述现象,将正则化引入我们的检测系统以防止参数规范过大。
3.4. 模型训练过程
我们的检测系统中的网络训练过程主要分为两部分。第一部分是SSD神经网络的训练,训练数据集包括带有类别标签和矩形边界框的图像。当损失函数值下降到足够小的值时,这意味着可以停止训练处理并且可以获得具有高性能的网络模型。
第二部分是卷积神经网络训练预测角度,输入数据集英包括带角度标签的图像。与SSD神经网路类似,当损失值下降到可接受的小值时,可以终止训练并且获得能够有效地检测物体角度的网络模型。
4. 实验比较
为了显示我们的检测系统的有效性,进行了以下新型检测算法与传统算法之间角度测量的对比实验。通过将从卷积神经网络获得的结果与从原始Canny算子边缘检测和Hough变换的组合获得的结果进行比较,可以获得分析。
4.1. 测量被测试物体的角度
在本实验中,计算真实值的方法是将样本图像放入GIMP图像处理软件中,然后使用标尺工具回执图像中的物体边缘线,从而自动获得倾斜角度。这些真实值显示在表1中。真实值和预测值之间的误差根据公式(4)计算。
(4)
代表预测值,
代表真实值,并且n代表样本图像的数量。
4.2. 基于单个样本图像的比较
选择单个样本进行新型检测算法与传统算法的对比实验。结果如图7所示。

基于单个样本图像的实验中获得的数据显示在表1中,在原始图像中,测量的对象角度是。
至于使用Canny算子处理样本图像并检测对象的边缘,检测到的边缘在图7中的(c)图展示,其中红线被选择作为代表性边缘线。由Canny算子计算的角度值为。本文设计的神经网络算法用于识别物体的位置和倾斜角度,物体的探测角度为
。

基于不同方法的实验数据,我们可以得出神经网络算法的精度高于Canny算子的结论。当神经网络检测到物体的姿态信息时,它首先识别物体的位置,然后检测物体本身的角度,而不是检测整个图像的角度。以这种方式,缩小了预测范围,并且大大增加了预测的准确性。结果是精度远高于传统算法。
4.3. 基于多个样本图像的对比
利用单个样本进行两种算法的比较后,应用多个样本图像将新的检测算法与传统算法进行比较。预测值和真实值之间的误差显示在表2中。
从表2的数据可以得出以下结论。与传统的Canny算子算法相比,新型检测算法的检测角度偏离角度值更接近测量值。在比较两种算法的效率的过程中,神经网络算法用于提取40个图像用于预测和运行时间计算。结果是23.46919s,因此单个图像的运行时间是0.5876s(=23.46919s/40)。

然后利用单个图像来估计传统算法的运行时间,即Canny算子和Hough变换的组合。运行时间为2.4219秒。相比之下,很明显,神经网络算法比Canny算子检测运行得更快。此外,在预测角度时,神经网络首先识别物体,然后检测特定物体的角度,而不是检测整个图像。因此,预测的准确性大大提高,并且高于传统算法。
当传统算法用于检测复杂背景图像时,这意味着图像中存在许多轮廓,Canny算子在检测图像时无法区分对象边缘和背景边缘。在检测过程中,轮廓的提取和角度的预测需要与其他算法像结合,应用于不同背景的方法是不同的。在某些情况下,获得合适的算法非常困难。因此,很明显,Canny算子具有局限性和相对较大的误差。当背景像素值与对象的像素值不是很大时,Canny算子无法检测到对象,因此传统方法无法准确应用。神经网络的预测结果明显优于传统方法,主要是因为神经网络可以准确地识别物体。对特定物体的识别通常会产生良好的效果。神经网络的预测结果受图像背景的影响较小,并且很少依赖于物体与背景之间的像素值差异,并且它们还呈现出良好的自适应效果和高预测精度。
另外,Canny算子在实验项目9和10中呈现理想的预测结果,因为第9和第10实验的图像时清晰的并且噪声较小。但传统算法总是失去检测精度,而采用神经网络的新型检测算法几乎保持稳定的检测精度,因此证明神经网络在定向检测中比Canny算子更具鲁棒性。
5. 总结
物体位置和方向的图像识别是机器人智能控制中的基本和重要的图像处理。本文提出的混合深度神经网络识别算法为RRU的光纤接口检测提供了一种高鲁棒,实时的图像处理。所提出的检测系统在对象的像素值和背景之间不需要太大的差异。另外,具有高预测精度和鲁棒性的检测系统突破了传统算法的局限性。混合算法在复杂背景和噪声干扰下也可以获得很好的预测结果,可以完全提取图像中的弱特征。最后,对比实验表明,混合深度神经网络的检测系统具有高性能和高精度检测,检测系统比传统的噪声图像算法更具鲁棒性。
参考文献
[1] S. Fang, X. Huang, H. Chen, N. Xi, Dual-arm robot assembly system for 3c product based on vision guidance, in: IEEE International Conference on Robotics and Biomimetics, 2017, pp. 807–812.
[2] J. Zhang, Y. Dong, H. U. Wangning, L. I. Donghai, Hardware and algorithm design of industrial robot for 3c products manufacturing, Machine Design & Research.
[3] M. W. Spong, Robot Dynamics and Control, John Wiley & Sons, 1989.
[4] L. J. Jiang, G. R. Wang, A stereovision method for resuming the position and pose of symmetry revolution object, Journal of Engineering Graphics 26 (5) (2005) 84–88.
[5] G. Wang, X. G. Xia, V. C. Chen, R. L. Fielder, Detection, location, and imaging of fast moving targets using multifrequency antenna array sar, Spie Proceedings 40 (1) (2004) 345–355.
[6] M. Tavana, A. R. Abtahi, D. D. Caprio, M. Poortarigh, An artificial neural network and bayesian network model for liquidity risk assessment in banking, Neurocomputing In Press.
[7] S. L. Adams, L. W. Nolte, Bayes optimum array detection of targets of known location, Journal of the Acoustical Society of America 58 (3) (1975) 656–669.
[8] J. Gall, A. Yao, N. Razavi, L. V. Gool, V. Lempitsky, Hough forests for object detection, tracking, and action recognition, IEEE Transactions on Pattern Analysis & Machine Intelligence 33 (11) (2011) 2188–2202.
[9] Z. Zhou, J. Zhang, Object detection and tracking based on adaptive canny operator and gm(1,1) model, in: IEEE International Conference on Grey Systems and Intelligent Services, 2007, pp. 434–439.
[10] T. He, X. Li, Y. Jiang, Improved ht object detection algorithm based on canny edge operator, Journal of Multimedia 9 (9).
[11] J. Ma, Y. Lu, L. Li, X. Lu, F. He, Z. Zhong, Edge location method based on canny operator and improved hough transform, Automation & Information Engineering.
[12] H. J. Wang, Edge detection of axis parts via combining canny operator with hough transformation, Mechanical & Electrical Engineering Technology.
[13] J. Xi, J. Z. Zhang, Edge Detection from Remote Sensing Images Based on Canny Operator and Hough Transform, Springer Berlin Heidelberg, 2012.
[14] I. Goodfellow, Y. Bengio, A. Courville, Deep Learning, MIT Press, 2016.
[15] D. Gutierrez-Galan, J. P. Dominguez-Morales, E. Cerezuela-Escudero, A. Rios-Navarro, R. TapiadorMorales, M. Rivas-Perez, M. Dominguez-Morales, A. Jimenez-Fernandez, A. Linares-Barranco, Embedded neural network for real-time animal behavior classification, Neurocomputing.
[16] Y. Fan, M. D. Levine, G. Wen, S. Qiu, A deep neural network for real-time detection offalling humans in naturally occurring scenes, Neurocomputing.
[17] Y. Lecun, Y. Bengio, G. Hinton, Deep learning, Nature 521 (7553) (2015) 436.
[18] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, A. C. Berg, Ssd: Single shot multibox detector (2015) 21–37.
[19] J. Jeong, H. Park, N. Kwak, Enhancement of ssd by concatenating feature maps for object detection.
[20] H. Li, Z. Lin, X. Shen, J. Brandt, G. Hua, A convolutional neural network cascade for face detection, in: Computer Vision and Pattern Recognition, 2015, pp. 5325–5334.
[21] J. Gu, Z. Wang, J. Kuen, L. Ma, A. Shahroudy, B. Shuai, T. Liu, X. Wang, L. Wang, G. Wang, Recent advances in convolutional neural networks, Computer Science.
[22] Y. L. Cun, B. Boser, J. S. Denker, R. E. Howard, W. Habbard, L. D. Jackel, D. Henderson, Handwritten digit recognition with a back-propagation network, in: Advances in Neural Information Processing Systems, 1989, pp. 396–404.
[23] W. Cao, X. Wang, Z. Ming, J. Gao, A review on neural networks with random weights, Neurocomputing.
[24] A. Y. Ng, Feature selection, l1 vs. l2 regularization, and rotational invariance, 2004, p. 78.
[25] D. Stewart, A platform with six degrees of freedom: A new form of mechanical linkage which enables a platform to move simultaneously in all six degrees of freedom developed by elliottautomation, Aircraft Engineering & Aerospace Technology (4).
[26] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam, Mobilenets: Efficient convolutional neural networks for mobile vision applications.
[27] L. Wang, S. Guo, W. Huang, Y. Qiao, Places205-vggnet models for scene recognition, Computer Science.
[28] G. Tsauro, D. S. Tourctzky, T. K. Ln, N. Burgess, Advances in Neural Information Processing Systems, Morgan Kaufmann Publishers, 1989.