将图神经网络与对比学习解耦用于欺诈检测
论文链接:https://linmengsysu.github.io/slides/main.pdf
摘要:
最近,许多欺诈检测模型引入了图神经网络(GNN)来提高模型性能。然而,欺诈者经常通过伪装自己的特征或关系来伪装自己。由于 GNN 的聚合性质,来自输入特征和图结构的信息将被压缩以同时进行表示学习。一方面,由于伪装,并非所有邻居都能提供有用的信息,因此聚合来自所有邻居的信息可能会降低模型的性能。另一方面,由于关系伪装,包含所有邻居的结构并不可靠。在本文中,我们建议将属性学习和结构学习解耦,以避免特征和关系伪装的相互影响。因此,模型首先单独学习其嵌入,然后将它们与标签引导的对比损失组合在一起,以做出更好的预测。我们对两个真实世界的数据集进行了广泛的实验,结果表明了所提出模型的有效性。
符号和问题定义
符号 通常,标量表示为小写字母(例如,x),小写粗体字母(例如,x)表示向量,大写粗体字母(例如,X)表示矩阵。集合或张量表示为书法字母(例如 )。 X(i, :) 和 X(:, j) 分别表示 X 的第 i 行和第 j 列。 X(i, j) 表示X 的第i 行j 列的元素。 ‖ · ‖F 表示矩阵F-范数。 ∪ 和
分别表示级联和向量内积。
定义 1(多关系图)。多关系图可以表示为 G = (V, {Er }|R r=1, X ),其中 V = {v1, .. , vn} 表示节点集,X = {x1, . 。 。 ,xn}表示所有节点特征的集合。每个节点 vi 与一个 d 维特征向量 xi ∈ Rd 关联,如果 vi 和 vj 通过关系 r ∈ {1, . .. ,R}。标签集Y表示节点标签集。
在本文中,我们放宽了有关“跳”的术语定义,“跳”表示一定距离度量内的节点
定义 2(K 跳邻居) 假设节点 vi 到 vj 之间的距离是 dij 。节点 vi 的 K 跳邻居是一组满足 dij ≤ K 的节点。给定图中的节点 vi ∈ V,我们使用 表示 K 跳邻居。
问题定义。给定一个多关系图 G = (V, {Er }|R r=1, X ) 以及 V 中所有节点(帐户或评论)的相应标签集 Y,我们将欺诈检测问题建模为二元分类任务。形式上,我们的目标是找到一个函数 f (·), s.t。
![]()
提出的方法
为了减轻伪装的影响,我们将 GNN 学习过程解耦为个体属性编码和多关系局部结构编码;之后,我们融合属性嵌入和结构嵌入作为最终的节点表示。为了更好地协助学习过程,我们提出了两种标签引导的对比损失。整体框架如图2所示。
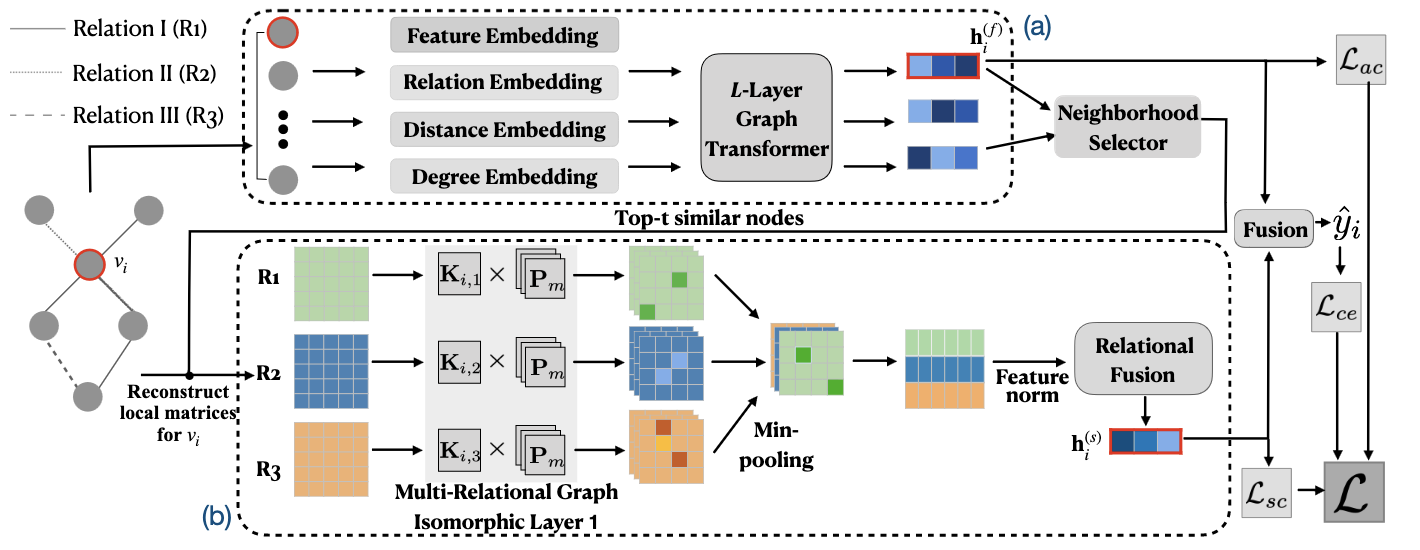
图 2:DC-GNN 架构。 (模块(a):使用图转换器进行个体属性编码;模块(b):使用多关系IsoNN进行多关系局部结构编码,包括多关系图同构层、最小池化层、特征归一化(norm)和关系融合;L:最终损失,其中包括用于标签预测的Lce,分别用于属性和结构对比损失的Lac和Lsc。
3.1 个体属性编码
节点属性
由于欺诈节点经常在节点特征上伪装自己,我们建议再添加三个与图相关的属性来确定节点是否欺诈。由于节点位于多关系图中,因此我们选择连接的关系类型、到中心节点的距离以及每个关系图下的度数。我们选择它们作为附加属性的原因是:(1)欺诈者为了获取利润而经常参与许多社会活动。例如,在在线评论图表中,欺诈者经常为许多商品撰写不真实的评论,以更好地进行促销。因此,欺诈者会联系许多也为这些商品撰写评论的用户; (2)此外,许多欺诈者还参与不同类型的活动,这可能会暴露欺诈者的活动类型,例如撰写虚假评论或同时发布虚假评论; (3) 此外,到给定节点的距离显示了节点对给定节点的影响。
形式上,给定一个多关系图 G = (V, {Er }|R r=1, X ),对于节点 vi,我们将相应的节点特征 xi 编码如下
![]()
由于我们处理的是多重关系,因此我们使用向量 ri ∈ {0, 1}R,其中 ri(j) = 1 表示节点具有第 j 个关系类型连接。采用一层 MLP 层来获得关系向量的嵌入。
![]()
我们使用[20]中提出的位置嵌入来编码vi到中心节点的距离P(vi)(即,该距离由vi到中心的最短距离决定)

其中 ![]() 。索引 l 迭代上述向量中的所有条目,以根据节点的距离使用 sin(·) 和 cos(·) 函数计算节点的条目值。对于度di,由于其数量可能非常大,我们首先对其进行归一化,并使用MLP来获取其信息。
。索引 l 迭代上述向量中的所有条目,以根据节点的距离使用 sin(·) 和 cos(·) 函数计算节点的条目值。对于度di,由于其数量可能非常大,我们首先对其进行归一化,并使用MLP来获取其信息。
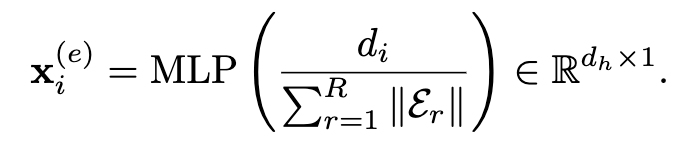
通过将四个属性相加,我们获得所有节点的初始节点嵌入
![]()
使用图变换器进行属性编码
由于变换器[20]的强大表示能力,我们使用它作为属性编码器。在图中,我们将节点的上下文视为其邻域。因此,我们直接选择 K 跳邻居作为给定节点的上下文。
对于每个节点,我们通过预处理图数据来获得其 K 跳邻居。假设我们有 vi 的 K 跳邻居集 ,对应的输入特征矩阵
![]() 且
且 ![]() 。我们设置
。我们设置 ![]() 并将其输入 L 层变压器:
并将其输入 L 层变压器:
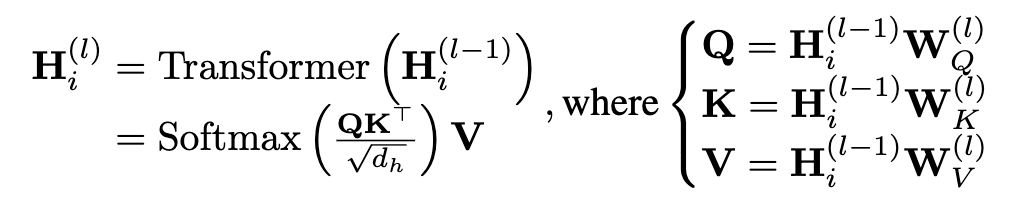
其中,![]() ,
, ![]() 请注意,由于特征伪装,我们直接将
请注意,由于特征伪装,我们直接将 作为节点 vi 的最终属性嵌入
以避免合并来自良性类的嵌入。
3.2 多关系局部结构编码
节点之间的关系还揭示了检测欺诈者的重要信息。正如之前的作品[16]所示,欺诈者经常集体行动,这也意味着欺诈者可能具有相似的局部结构。然而,传统的 GNN 无法学习良好的结构信息,因为欺诈者经常将自己隐藏在与良性节点的连接中,从而引入属于良性节点的特征。
我们建议单独对邻接矩阵进行编码。因此,我们利用同构图神经网络[14]。然而,IsoNN 最初用于同构图分类,我们将其扩展到多关系图以捕获每个节点的局部结构嵌入。
局部邻接矩阵重建
我们需要重建所有节点的局部邻接矩阵,然后每个节点学习其局部结构表示。然而,用其K跳邻域重建局部邻接矩阵是不现实的,因为它可能涉及多个节点,导致较高的计算成本。因此,我们从 K 跳邻居中选择有用的节点。根据给定节点及其邻居的变压器 H(L) i 输出中嵌入之间的相似性来选择节点。在这里,我们计算相似度如下:
![]()
这里,欧几里得距离是相似度度量。我们选择Top-t相似节点{vj,····,vk}及其本身vi来重建局部邻接矩阵。请注意,在本文的其余部分中,为了简单起见,我们将 {vj , · · · , vk} 与中心节点 vi 一起视为选定的 t 节点
利用多关系图 G = (V, {Er }|R r=1, X ) 和选定的节点 {vi, vj , · · · , vk},我们重建所有关系的局部邻接矩阵,即记为 Ai = {Ai,r ∈ {0, 1}t×t|1 ≤ r ≤ R},第 r 个关系中节点 vi 的局部邻接矩阵 Ai,r 如下

请注意,节点的顺序不会对嵌入结果产生太大影响,因为 IsoNN 可以减轻邻接矩阵带来的节点顺序约束
使用多关系 IsoNN 进行结构编码
IsoNN 中的图同构层采用可学习的核变量 K ∈ Rm×m 来学习区域结构信息。在这里,为了与多关系图结合,我们提出了多关系图同构层。我们使用关系内核 {K1, . .., KR},其中 Kr ∈ Rm×m 是第 r 个关系。我们可以有多个通道,因此关系 r 的可学习核表示为 Kr ∈ Rc×m×m。然后可以通过以下方式学习特征
![]()
其中 Pj ∈ {0, 1}m×m 是来自置换集 {P1, · · · , Pm!}(穷举所有的置换矩阵) 的置换矩阵(通过初等变换得到的矩阵,结果还是对称矩阵)。 ![]() 因为 Ai,r 总共生成 (t − m + 1) × (t − m + 1) 个子矩阵。计算完所有可能的排列后,我们需要找到最佳排列所产生的特征。因此,在排列矩阵引起的维度上采用最小池化层来找到最优排列计算出的最小值:
因为 Ai,r 总共生成 (t − m + 1) × (t − m + 1) 个子矩阵。计算完所有可能的排列后,我们需要找到最佳排列所产生的特征。因此,在排列矩阵引起的维度上采用最小池化层来找到最优排列计算出的最小值:
![]()
其中 ![]() 。为了减少参数数量,我们在所有通道中对 ˆFi,r 采用平均池化层。
。为了减少参数数量,我们在所有通道中对 ˆFi,r 采用平均池化层。
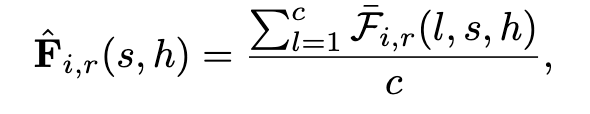
其中 ˆFi,r ∈ R(t−m+1)×(t−m+1)。由于学习到的特征的值可能在很大范围内变化,因此我们对这些学习到的特征进行标准化。此外,区分哪个区域贡献更多可以构建更好的结构特征。我们重塑 ![]() 转化为向量并将它们连接为
转化为向量并将它们连接为 ![]() ,然后将其归一化为
,然后将其归一化为
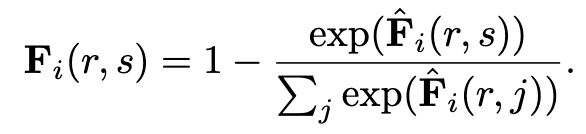
在这里,我们使用“1”进行减法,因为较小的值显示模板和子图之间更好的匹配。因此,嵌入 h(s) i 的局部结构是
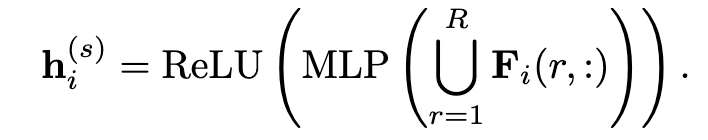
3.3 标签引导的对比损失增强优化
标签预测。为了预测节点标签,我们将属性嵌入和结构嵌入连接在一起作为最终的节点嵌入。形式上,节点 vi 的预测可以通过
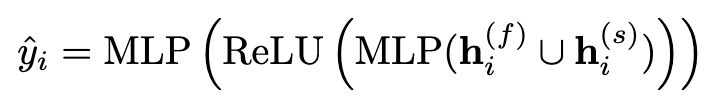
标签预测的损失函数是加权交叉熵。
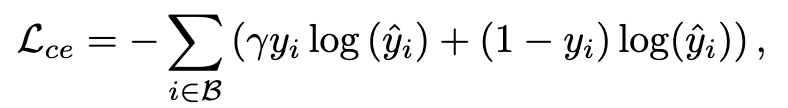
其中 γ 是欺诈标签 (yi = 1) 与良性标签 (yi = 0) 的不平衡比,B 是训练批次。
标签引导的对比损失。为了更好地协助优化,我们引入了两种标签引导的对比损失,为学习节点嵌入提供额外的指导。如上所述,我们将属性和结构分开,因为它们会相互影响,这可能会使欺诈者更难被发现。因此,我们分别对比属性嵌入和结构嵌入。具有相同标签和负对的那些是基于训练集具有不同标签的那些。在这里,我们将属性标签引导的对比损失定义为:

![]()
实验效果
