《Single-Shot Refinement Neural Network for Object Detection》(RefineDet)
(一)论文地址:
《Single-Shot Refinement Neural Network for Object Detection》
(二)解决的问题:
对于目标检测, 方法(比如faster-rcnn)实现了较高的准确率,而 方法(使用不同位置、不同大小、不同比例的稠密采样,预测分类和坐标回归,比如SSD)则实现了检测的高效率;
两个网络的详解可以看我的这几篇博客:
这篇文章提出了 ,在实现了比 方法有更高准确率的同时,也保证了检测的效率;
(三)RefineDet 的核心思想:
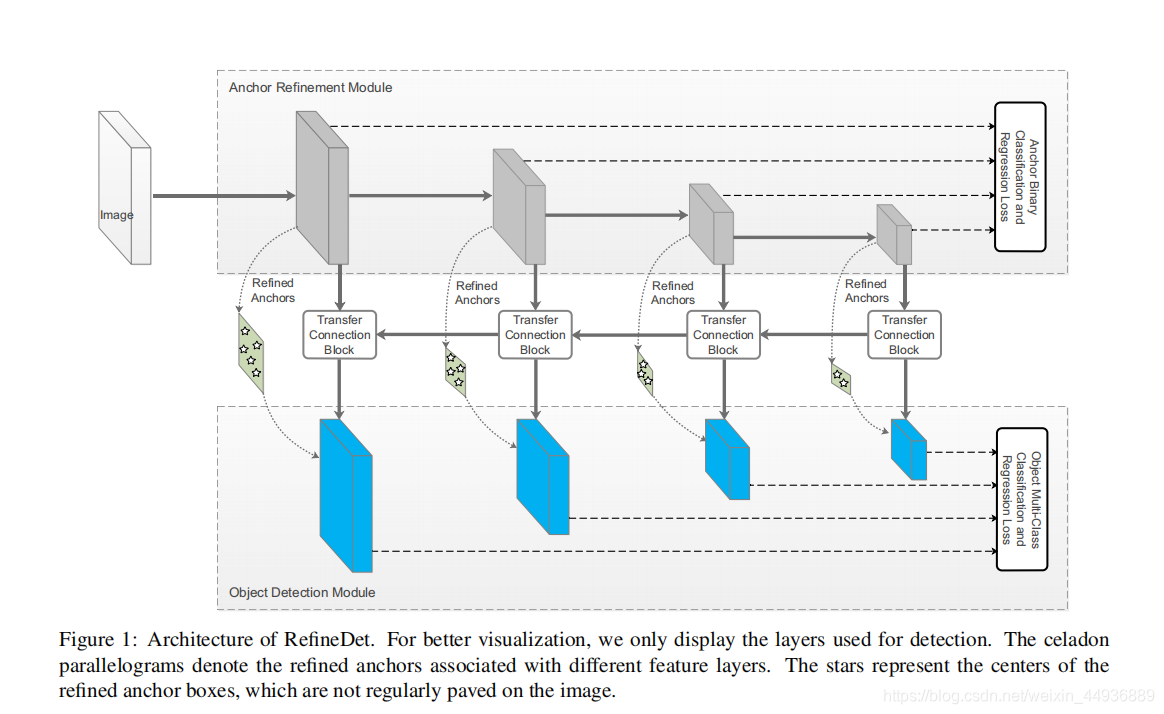
的核心是提出了两个相互连接的模块:
-
(简称
),作用是:
1.1 过滤预选框( )中的负样本,从而减小分类器( )的搜索空间;
1.2 粗略地调整正样本的位置和大小,为后续回归的预测提供更好的初始化条件;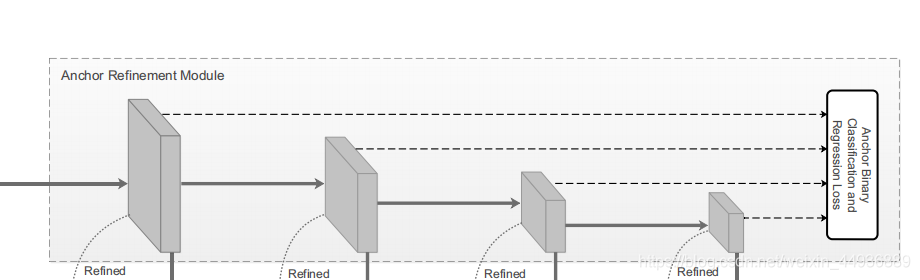
-
(简称
),作用是:
2.2 接受筛选的正样本作为输入,预测回归坐标;
2.3 预测正样本的类别标签;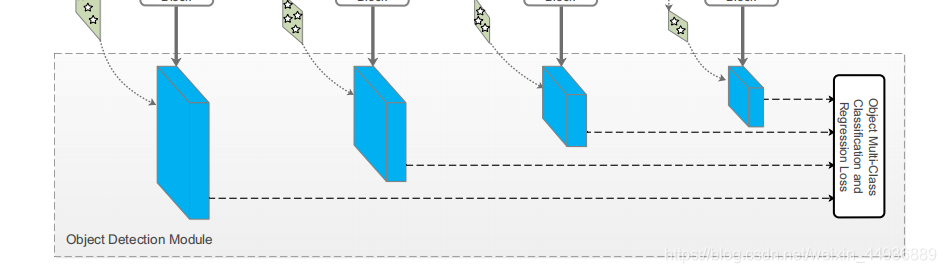
即, 对应 faster-rcnn的 过程,负责正样本提取和初步预测调整,从而提高后续预测和回归的准确率,并减少计算; 进行预选框坐标的进一步调整和目标的分类预测;
并且 使用了类似SSD的方法,采用不同感受野大小的特征层,来分别预测不同大小的目标;
(四) - 方法的优势:
在
方法中,一般是首先生成粗略的坐标框,再做更深入的分类和坐标回归;
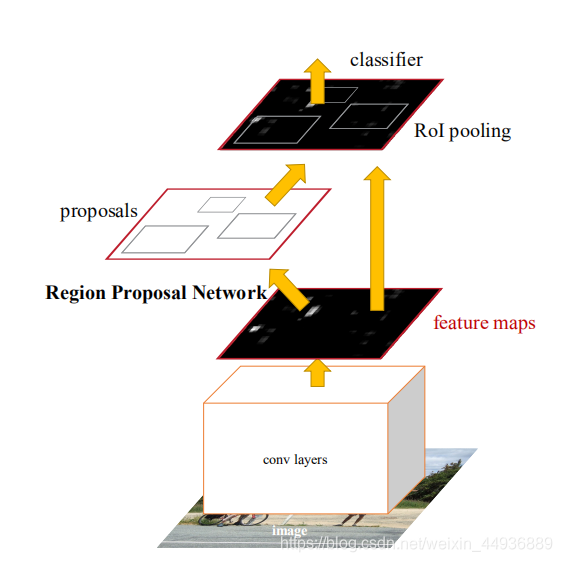
这样做有三个优势:
- 使用粗略采样解决了负样本和物体分类不均衡的问题;
- 使用 连级预测,提高了检测框回归坐标的精度;
- 使用 的特征描述目标;
因此, 使用了 方法来过滤负样本并进行候选框的粗略预测;同时使用了两个内部相互连接的 来发挥 优势;
DSSD的理论提出,使用反卷积将较深的特征图与较浅的特征图融合,能够有效增加上下文信息、进一步利用和提取特征,从而提高小目标检测的精度;
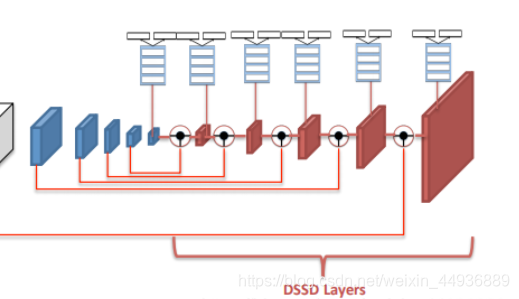
DSSD详解可以看我的这一篇博客:
【论文阅读笔记】DSSD : Deconvolutional Single Shot Detector
基于这个理论,作者设计了 (简称TCB),从而更有效地利用深层的特征图,并为 ODM 的高精度预测进一步提取和转换特征;
(五)RefineDet 的网络结构:
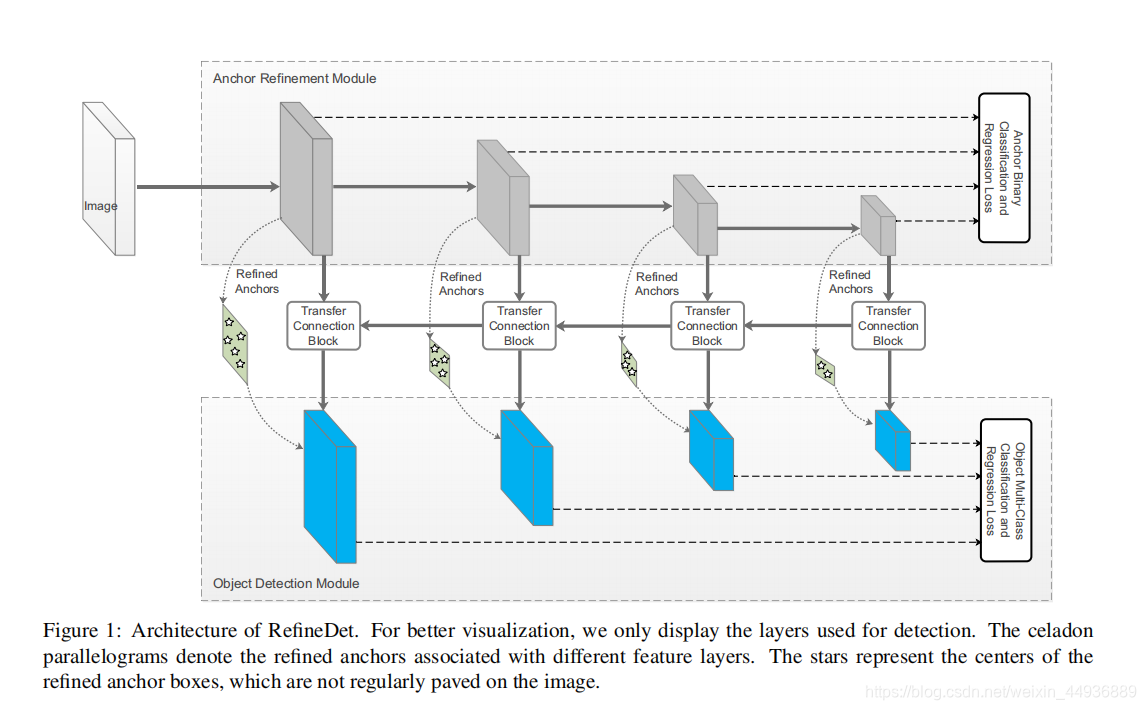
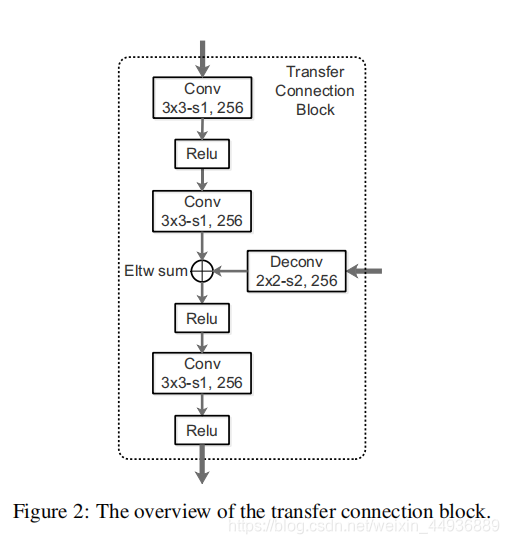
5.1 Transfer Connection Block:
基于DSSD的理论,作者设计了 (TCB),来连接 ARM 和 ODM,并实现了将 ARM 的特征转换成 ODM 的输入格式;
TCB 的另一个功能就是,将深层特征通过反卷积融合到浅层特征中,从而提高检测的准确率;
5.2 Two-Step Cascaded Regression:
(两步联级回归)是对当前 方法进行目标坐标框回归的改进;
当前 方法进行目标坐标框回归,一般是基于不同大小的特征图,使用不同大小的anchors来预测坐标和目标大小,这种方法在一些复杂场景和检测小物体时准确度较低;
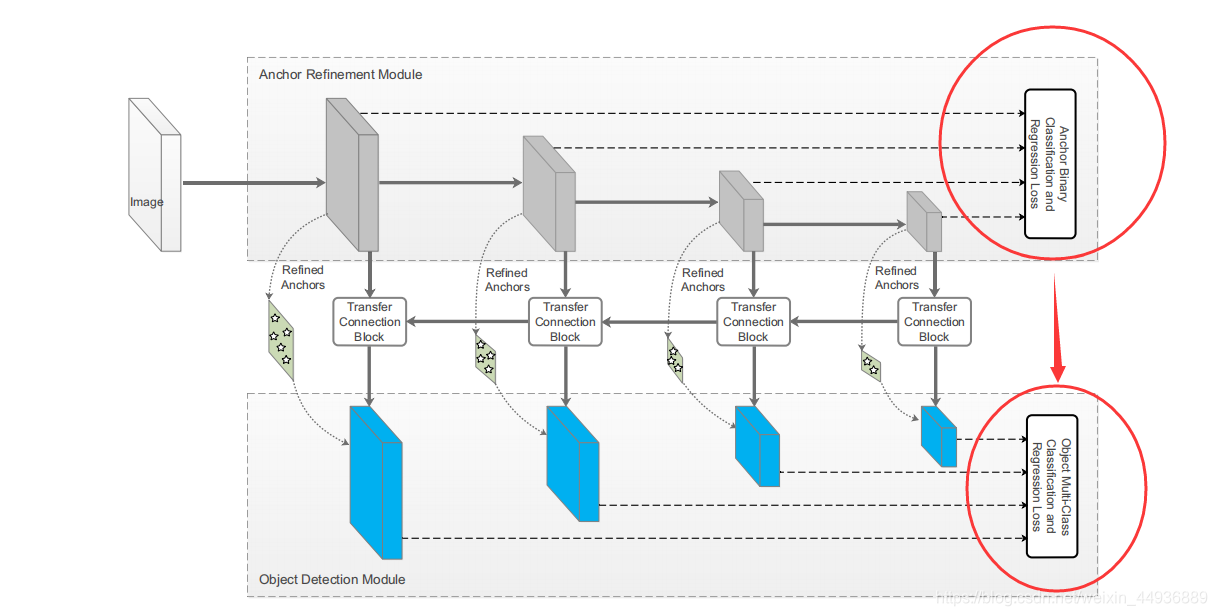
这里作者提出了 ,即先通过 ARM 调整 anchors 的位置和大小,来为 ODM 提供更好的初始条件;
首先 ARM 中假设特征图上每个点(cell)有 个 anchor boxes,每个 anchor box 的初始位置对应特征图上的点都是固定的;因此我们在预测特征图上每个点,生成 4 个相关的粗略的坐标相关的回归值,并预测两个置信度得分(表示是目标还是背景),这样每个点就得到了 个 refined anchor boxes;
在 ODM 中,我们将 个 refined anchor boxes传入相应的特征图中,对每个 refined anchor box,使用 大小卷积核的卷积层作为预测层,生成 个类别得分和 4 个精确的回归坐标值(这一步跟SSD的预测过程非常像);
5.3 Negative Anchor Filtering:
为了尽可能地去除置信度较高的负样本、减轻正负样本分类不均衡的问题,作者设计了负样本的过滤机制;
在训练过程中,如果一个样本的背景置信度大于一个给定的阙值 (设 ),那么我们将不允许这个样本(anchor)参与到 ODM 的训练中;
也就是说,我们只保留前景置信度高的正样本和难以区别的负样本,参与到 ODM 的训练中;
(六)RefineDet 的训练结构:
6.1 特征提取网络:
前面由于提取特征的网络,一般是移除分类层并加上一些额外结构的基础网络(如在 上预训练的 - 、 - );
6.2 数据增强:
为了使模型具有更好的鲁棒性,作者使用了随机填充、随机裁剪和随机翻转;
6.3 Anchors 的设计和匹配:
为了匹配不同大小的物体,RefineDet 使用了4中不同步长大小的特征层,分别为8、16、32、64像素大小,对应不同的 anchors 大小(每层的anchor大小是步长的4倍),并且 anchors 分别由0.5、1.0、2.0的长宽比;
在匹配 anchors 的 label 时,将 anchor 与真值框的 的 anchor 标注为相应的类别;
6.5 正负样本的筛选:
由于即使有了 ARM 初步区分正负样本,负样本的比例依然远远大于正样本的比例;
为了调节正负样本比例不均衡的问题,训练时选取loss最大的负样本,使得负样本的数量:正样本的数量的比率 ,而不是使用全部的负样本;
6.6 Loss 函数:
RefineDet 的 Loss 函数由两部分组成:ARM 的 Loss 和 ODM 的 Loss;
定义 Loss 函数如下:
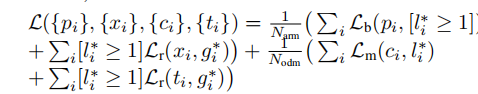
其中:
- 是 anchor 在 mini-batch 中对应的索引;
- 是 anchor 的真实分类标签;
- 是目标的真实坐标和真值框的大小;
- 是 ARM 中 anchor 的前景/背景置信度;
- 是 ARM 中 anchor 的初步坐标预测值;
- 和 则分别是 ODM 中分类和坐标的预测值;
- 和 分别是 ARM 和 ODM 中正样本的数量;
- 是二分类中的交叉熵对数损失函数;
- 是多分类的 softmax 损失函数;
- 是坐标值的 ;
6.7 优化器:
这里使用均值为0的高斯随机分布做为参数的初始化;
使用带有动量项(momentum=0.9)的SGD(随机梯度下降法)作为优化器;
使用系数为0.0005的 weight decay;
初始 learning rate 为 ,并使用了 learning rate decay;
最后使用 NMS(非极大值抑制)出去重叠的预测框;
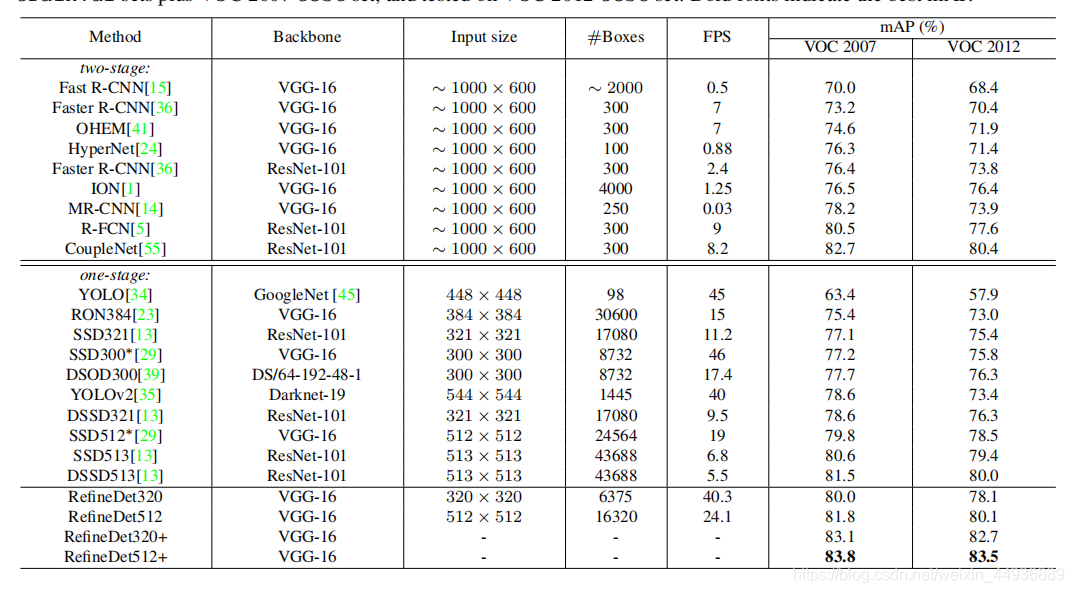
7. 实验结果: