来自于论文:《Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling》
基于attention的encoder-decoder网络在机器翻译取得成功,本文提出基于attention的网络联合对齐模型用于IC和SF,在ATIS任务上实现了最先进的效果-ID错误率和SF的f1 score。
问题:
attention在seq2seq中用于学习soft对齐同时解码,本身SF就是对齐的情况下,attention应该如何应用。
前向和后向RNN的hi会丢失长依赖的信息,通过映入context向量ci,来提供hi没有捕捉到的长依赖的信息。对于IC,如果没有attention,对各个hi使用mean-pooling的方式输入IC,但加入attention之后,输入将是hi的加权和。
文章一共介绍了两种模型:
1、加入Attention机制和对齐机制的RNN编码器-解码器模型
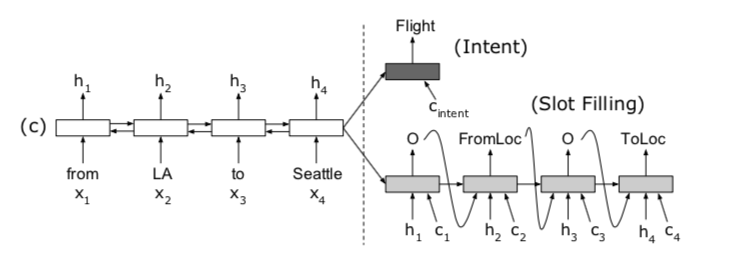
1.1 底层特征:
Embeding
窗口词向量:
xtd=e(wt)
1.1.1 BiRNN(GRU or LSTM)
ht
=RNN
(xt,ht−1
)
ht
=RNN
(xt,ht−1
)
输出:
ht
=[ht
,ht
]
1.2 attention:
-
slot filling:
- 权重计算:
ciS=j=1∑Tαi,jShj,(1)
αi,jS=∑k=1Texp(ej,k)exp(ei,j)(2)
ei,k=VTσ(WheShk+Wiehi)(3)
ciS∈Rbs∗T,和
hj一致。
ei,k∈R1,
ei,k计算的是
hk和当前输入向量
hi之间的关系。
作者TensorFlow源码
WkeShk用的卷积实现,而
WieShi用的线性映射_linear()。
T是attention维度,一般和输入向量一致,源码其实
ei,k=reduce_sum(VTσ(WkeShk+Wiehi)),将其变为1维度,一共T个word,就有T个e。
- SF
yiS=softmax(WhyS(hi+ciS))(4)
- Intent Prediction:其输入时BiLSTM的最后一个单元的输出
hT以及其对应的context向量。
yI=softmax(WhyI(hT+cI))(5)
2、加入Attention机制的RNN模型。
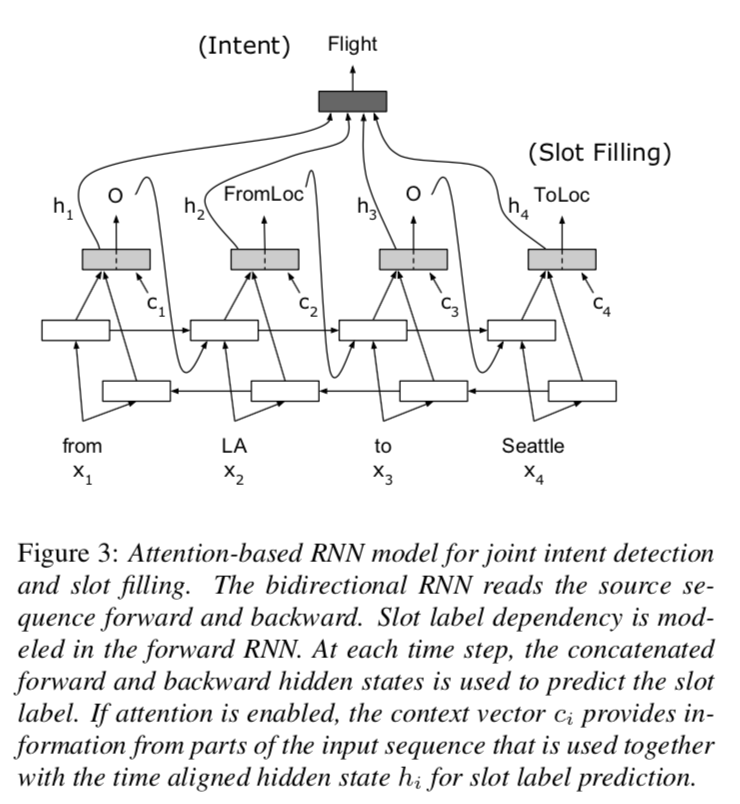
计算和模型1类似,公式不在列出。
实验结果:
| model |
ic error |
slot F1 |
| Attention Encoder-Decoder NN |
1.57 |
95.87 |
| Attention BiRNN |
1.79 |
95.98 |
词槽抽取的实验结果比目前最好的要好0.1%左右。
意图识别的实验结果比目前最好的要提高1%左右。
Conclusions
获得了stae of the art的表现,但是没有指出未来的点,以及一些可能会有的问题,
个人认为数据集问题,有待在更大更多数据集验证效果,例如ATIS数据量其实还是比较小,一共4478+500+893,对于百分点的提升有一定的随机性,有待统计假设检验验证等。(其实模型还是挺靠谱的,只是实验还可以做得更严谨)
csdn原文:https://blog.csdn.net/shine19930820/article/details/83052232
Reference
- 来源论文:https://arxiv.org/abs/1609.01454
- 代码:https://github.com/HadoopIt/rnn-nlu