《Machine Comprehension Using Match-LSTM and Answer Pointer》
这篇论文介绍了一种端到端解决机器阅读理解问答任务的方法,结合了Match-LSTM和Pointer Net。该文是第一个在SQuAD数据集上测试的端到端神经网络模型。最终训练效果好于原数据集发布时附带的手动抽取特征+LR模型。
SQuAD数据集
SQuAD 是由 Rajpurkar 等人提出的一个最新的阅读理解数据集。该数据集包含 10 万个(问题,原文,答案)三元组,原文来自于 536 篇维基百科文章,而问题和答案的构建主要是通过众包的方式,让标注人员提出最多 5 个基于文章内容的问题并提供正确答案,且答案出现在原文中。SQuAD 和之前的完形填空类阅读理解数据集如 CNN/DM,CBT等最大的区别在于:SQuAD 中的答案不再是单个实体或单词,而可能是一段短语,这使得其答案更难预测。SQuAD 包含公开的训练集和开发集,以及一个隐藏的测试集,其采用了与 ImageNet 类似的封闭评测的方式,研究人员需提交算法到一个开放平台,并由 SQuAD 官方人员进行测试并公布结果。下图是一个示例:

模型结构
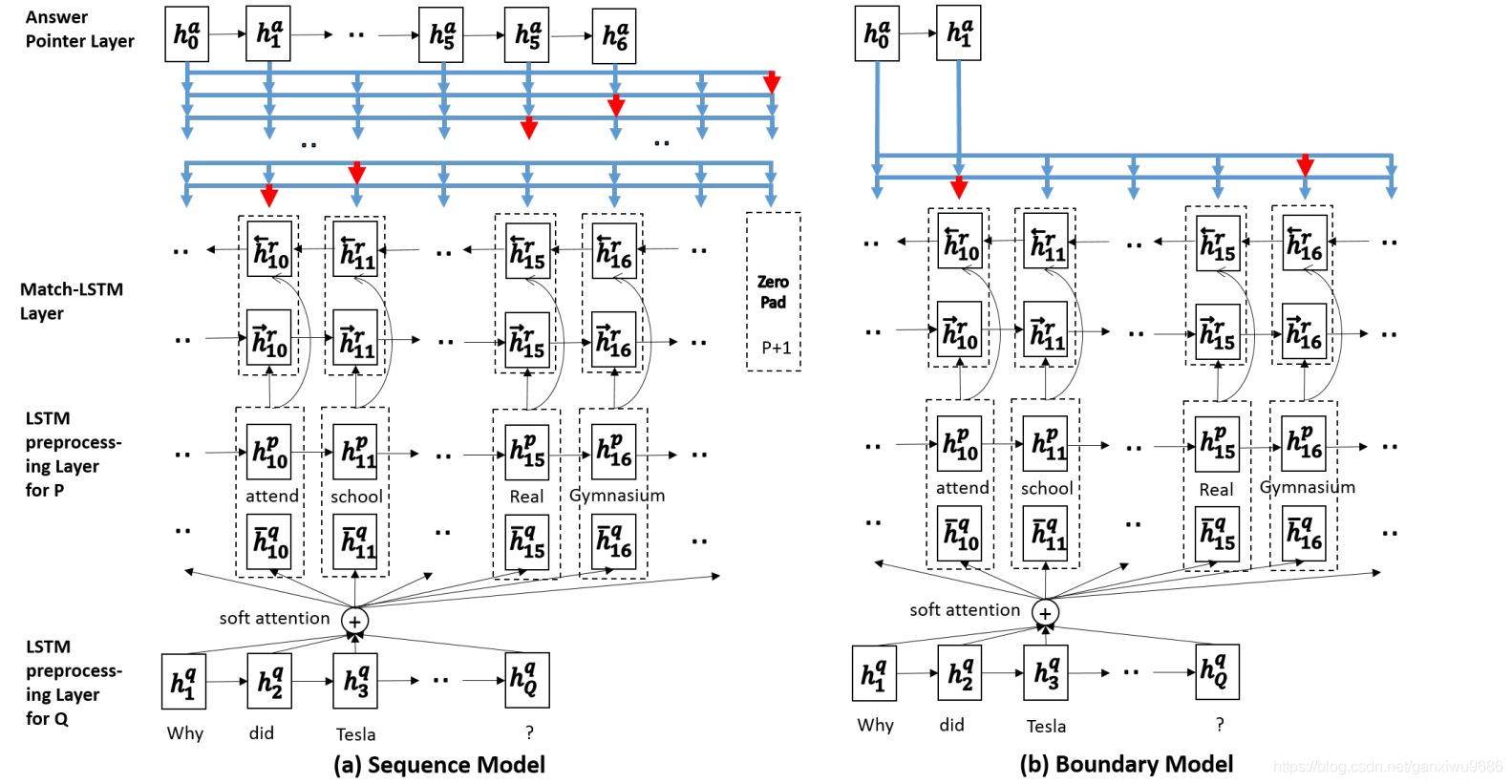
模型整体分为三部分:
- LSTM预处理层:编码原文以及上下文信息
- match-LSTM层:匹配原文和问题
- Answer-Pointer层:使用Ptr-Net网络,从原文中选取答案。这里又提出了两种预测答案的模式:
- Sequence model:不做连续性假设,预测答案存在与原文的每一个位置。
- boundary model:直接预测答案在原文中起始和结束位置。相比于 Sequence Model 极大地缩小了搜索答案的空间,最后的实验也显示简化的 Boundary Model 相比于复杂的 Sequence Model 效果更好,因此 Boundary Model 也成为后来的模型用来预测答案范围的标配。
简单的说:带着问题去阅读原文,然后用得到的信息去回答问题
- 先利用LSTM阅读一遍passage,得到输出的encoding 序列。
- 然后带着question的信息,重新将passage的每个词输入LSTM,再次得到passage的encoding信息。但是这次的输入不仅仅只有passage的信息,还包含这个词和question的关联信息,它和question的关联信息的计算方式就是我们在seq2seq模型里面最常用的attention机制。
- 最后将信息输入answer模块,生成答案。
LSTM preprocessing layer
首先用词向量表示问题和段落,再使用单向 LSTM 编码问题和段落,得到hidden state表示。这里直接使用单向的LSTM,每一个时刻的隐含层向量输出只包含左侧上下文信息。
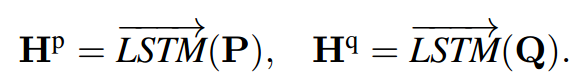
l是LSTM的隐藏层大小,P和Q分别是段落passage 和 问题question的长度。
Match-LSTM layer
match-LSTM原先设计是用来解决文版蕴含任务:有两个句子,一个是前提H,另外一个是假设T,match-LSTM序列化地经过假设的每一个词,然后预测前提是否继承自假设。而在问答任务中,将question当做H,passage当做T,则可以看作是带着问题去段落中找答案。这里利用了attention机制(soft-attention)。
对段落p中每个词,计算其关于问题q的注意力分布α,并使用该注意力分布汇总问题表示;将段落中该词的隐层表示和对应的问题表示合并,输入另一个 LSTM 编码,得到该词的 query-aware 表示。具体结构如下:
- 针对passage每一个词语输出一个α向量,这个向量维度是question词长度,故而这种方法也叫做question-aware attention passage representation。
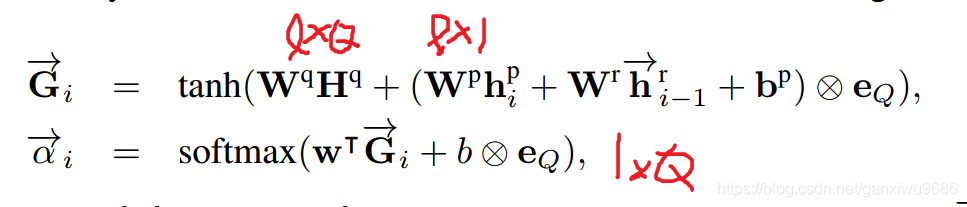
- 将attention向量与原问题编码向量点乘,得到passage中第i个token的question关联信息,再与passage中第i个token的编码向量做concat,粘贴为一个向量
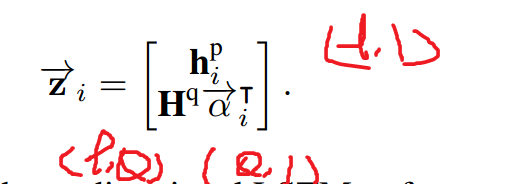
- 最后输出到LSTM网络中。
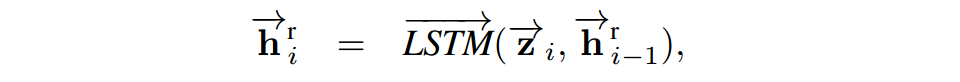
4.反向同样来一次,最后两个方向的结果拼起来。得到段落的新的表示,大小为2lxP.
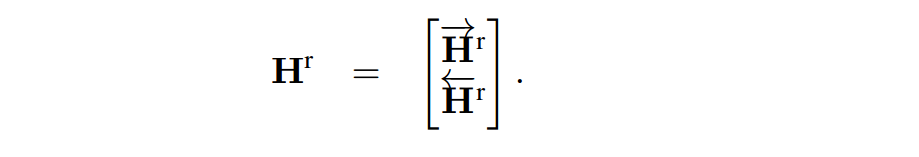
Answer Pointer layer
Answer Pointer的思想是从Pointer Net得到的, 它将 Hr 作为输入,生成答案有两种方式sequence model 和 boundary model。
The sequence model
序列模型不限定答案的范围,即可以连续出现,也可以不连续出现,因此需要输出答案每一个词语的位置。又因答案长度不确定,因此输出的向量长度也是不确定的,需要手动制定一个终结符。假设passage长度为P,则终结符为P+1。
假设答案序列为: a=(a1,a2,…) ,其中ai为选择出来答案的词在原文passage里面的下标位置,ai∈[1,P+1], 其中第P+1 是一个特殊的字符,表示答案的终止,当预测出来的词是终止字符时,结束答案生成。
简单的方式是像机器翻译一样,直接利用LSTM做decoder处理: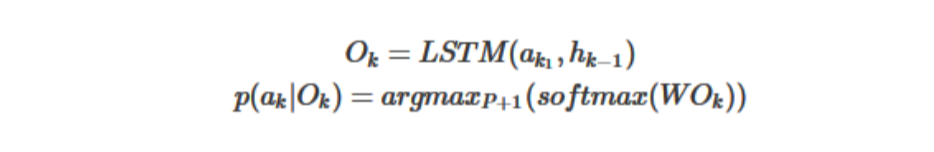
找到passage里面概率最大的词的就可以了。
对于pointer net网络,实质上仍然是一个attention机制的应用,只不过直接将attention向量作为匹配概率输出。
这里也利用了Attention机制, 在预测第k个答案的词时,先计算出一个权重向量 βk 用来表示在[1, P+1]位置的词,各个词的权重。
- 对于第k个答案,段落里各个词对应的权重:
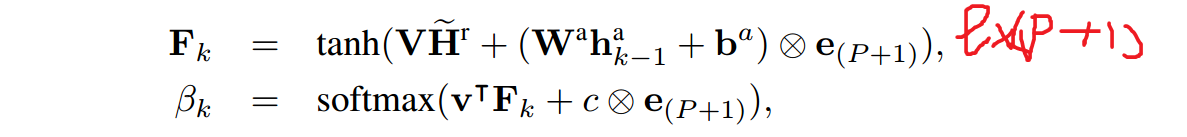
- 将上一步得到的编码Hr与权重βk求内积,得到针对第k个答案的表示

- βk,j 就表示第k个位置的答案ak是段落中第j个词的概率。βk,j最大的一个下标就是预测的ak值

The boundary model
边界模型直接假设答案在passage中连续出现,因此只需要输出起始位置s和终止位置e即可。基本结构同Sequence Model,只需要将输出向量改为两个,并去掉终结符。
答案a=(as,ae) 只有两个值
作者对于这种模型扩展了一种 search mechanism,在预测过程中,限制span的长度,然后使用全局搜索,找 p(as) × p(ae)最大的。
实验结果

讨论
- 测数据发现长的答案更难预测,当答案包含大于9个tokens时,f1值跌落至55%左右,em值到30%左右
- 模型更适合“是什么”类型问题,对于“为什么”类型效果较差
- 作者对上文中match-LSTM层的attention向量α做可视化,与事实相符,该向量应该是描述question与passage每一个位置的相关程度的。
这里有几个问题:
1.
的计算里面,
怎么来的?随机初始化第0时刻吗?
2.Here “Search” refers to globally searching the spans with no more than 15 tokens—这里的Search是指对预测的答案限定不超过15个单词吗?超过了怎么处理呢?
——解答:是的,超过的话,可以选定开始符后15个单词,之后截断。
3.during prediction, we try to limit the length of the span and globally search the span with the highest probability computed by p(as) × p(ae)。
这里,也是限定块的长度,是对预测的答案限定还是把文章分成若干个span?然后再选取最大的概率。
——解答:对预测的答案限定在15个词之内。
还有这个globally search the span,全局搜索,啥意思?
——解答:全局搜索,即预测开始位置时,不是选择最大的一个,而是选择若干个position,然后计算若干个结束位置,从中选择概率最高的,即p(as) × p(ae)最大。
4.Besides, as the boundary has a sequence of fixed number of values, bi-directional Ans-Ptr can be simply combined to fine-tune the correct span.
双向指针网络能微调正确的块?啥意思?