引言
本文是论文FusionNet1的阅读笔记。
摘要
作者引入了一种全新的网络结构,叫做FusionNet,它从三个方法扩展了现有的注意力方法。首先,提出了一个新颖的“单词历史”概念,以描述从最低单词级别嵌入到最高语义级别表示的注意力信息。其次,确定了更好地利用“单词历史”概念的注意力评分函数。最后,提出了一种全感知(fully-aware)的多层次注意力机制,以捕获一个文本(如问题)中的完整信息,并相应地(比如在上下文或文章中)逐层利用它。
核心思想
该论文的贡献之一便利对各种注意力方法对一个总结。
全感知注意力
首先介绍一下机器阅读理解的概念架构图,然后引入了单词历史的概念,并提出了一种轻量级的实现。
机器阅读理解的概念架构
在所有最先进的机器阅读理解架构中,都会有如下的重复模式。给定两组向量,A和B,我们使用集合B中的信息增强或修改集合A中的每个向量。我们称之为融合过程,其中集合B融合到集合A中。融合过程通常基于注意力,但有些不是。当时的MRC工作的主要改进方向在于融合过程的设计方式。
图2显示了最先进架构的概念架构,该架构由三个组件构成。
- 输入向量:上下文(context)和问题中每个单词的嵌入向量。
- 集成组件: 图中的矩形框,通常是基于RNN实现的。
- 融合过程: 带有数字的箭头(1),(2),(2’),(3),(3’)。从箭头起始位置向箭头指向位置融合。
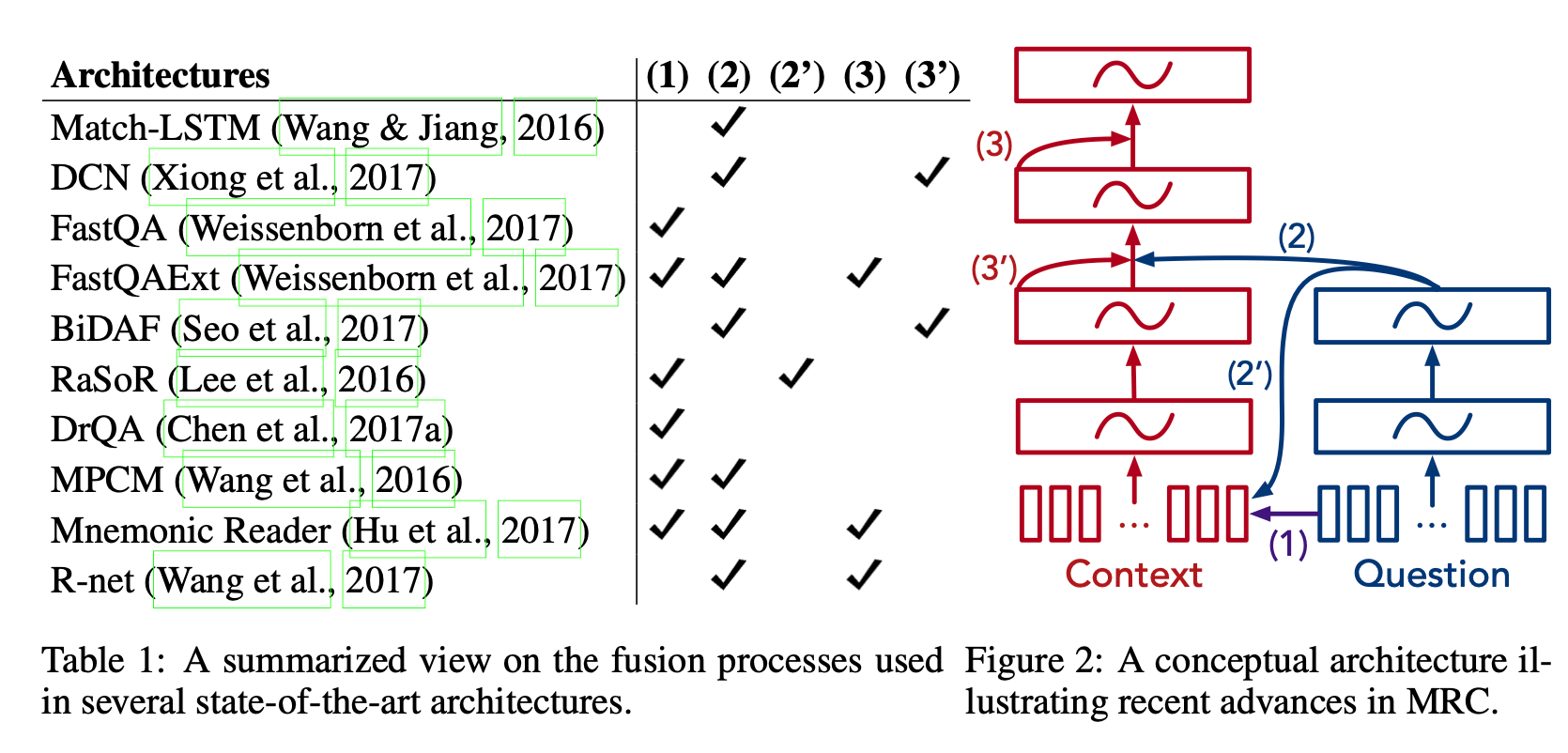
现在主要的三种融合过程。上图左边的表显示了不同网络结构使用的融合过程。
(1)单词级融合 通过向上下文(Context,或者说文章)提供直接的单词信息,我们可以快速放大上下文中更相关的区域。然而,如果一个单词基于上下文有不同的语义,此时可能用处不大。许多单词级别的融合不是基于注意力,例如有人在上下文单词中添加二进制特征,指示每个上下文单词是否出现在问题中。
(2)高层融合 融合问题中语义信息的上下文可以帮助我们找到正确的答案。但高层信息没有单词信息准确,这可能会导致模型对细节的了解不够。
(2’)高层融合(可选) 类似地,我们也能将问题的高层信息融入上下文的单词信息中。
(3)自提升融合 由于上下文可能会很长,而较远部分的文本可能需要互相依赖来充分理解文本信息。最近的研究建议将上下文融合到自身。由于上下文包含过多的信息,一个常见的选择是在融合问题Q后执行自提升融合(self-boosted fusion)。这使我们能够更好地了解与问题相关的区域。
(3’)自提升融合(可选) 另一种选择是直接在问题Q上调整自提升融合过程,比如DCN2论文中提出的共同注意力机制(coattention mechanism)。然后,我们可以在融合问题信息之前执行自提升融合。
现有融合机制的一个共同特点是,它们都没有同时使用所有层的表示。作者认为,应用所有层的表示信息是对达到更好的文本理解来说至关重要。
单词历史上的全感知注意力
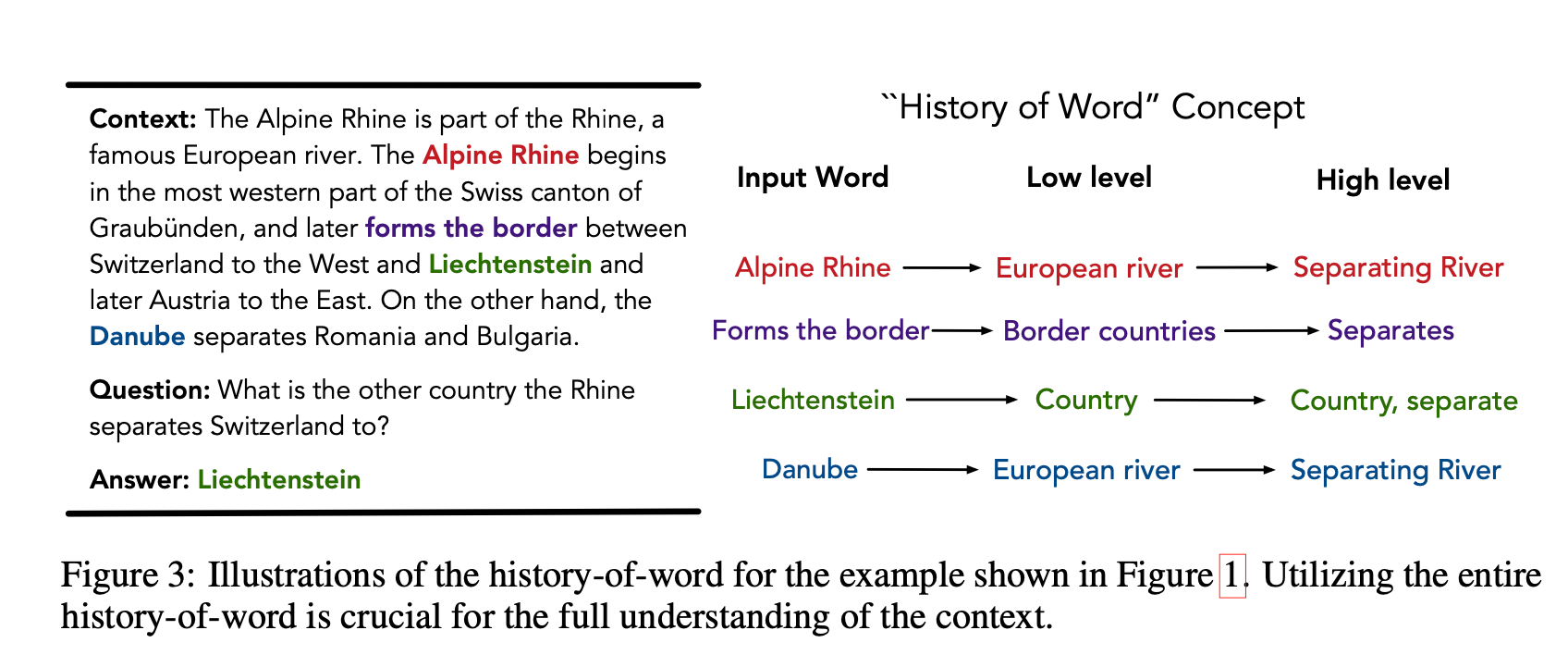
上图是一个展示单词历史的例子。下面给出它的翻译,方便分析:
上下文 高山莱茵河(Alpine Rhine)是莱茵的一部分,莱茵河是欧洲著名的河流。高山莱茵河始于瑞士格劳宾登州最西部,后来形成了瑞士西部和列支敦士登(Liechtenstein)之间的边界,后来是奥地利东部的边界。另一方面,多瑙河(Danube)将罗马尼亚和保加利亚分开。
问题 莱茵河(Rhine)将瑞士和哪个国家一起分开了?
答案 列支敦士登(Liechtenstein)
见上面的译文,我们阅读上下文的时候,每个单词都会转换成更抽象的表示。比如,从低层到高层概念。总之,它们构成了我们脑海中每个单词的历史。作为人类,我们经常使用单词历史的信息,但我们总是忽略它的重要性。比如,问了回答上面的问题,我们需要同时关注“形成边界(forms the borders)”的高层概念和高山莱茵河的低层概念。如果我们只关注高层概念,我们会被高山莱茵河与多瑙河困扰,因为它们都是欧洲大陆的河流,同时都分开了国家。因此,作者强调整个单词历史对于完全理解文本的重要性。
在网络结构中,作者定义第 i i i个单词的历史为: H o W i HoW_i HoWi,为这个单词生成的所有表示的拼接。可能包含单词嵌入,RNN中的多个中间和输出隐藏向量,和其他层的对应表示。为了将单词历史融入到神经网络模型中,作者提出了一个轻量级实现,被称为 全感知注意力。
本文作者关注的是,从一个东西(比如,向量)融合信息到另一个东西这种注意力应用场景。考虑两个文本中的单词隐藏向量集合 A A A和 B B B: { h 1 A , ⋯ , h m A } , { h 1 B , ⋯ , h n B } ⊂ R d \{h^A_1, \cdots, h^A_m\},\{h^B_1,\cdots,h^B_n\} \subset \Bbb R^d {
h1A,⋯,hmA},{
h1B,⋯,hnB}⊂Rd。它们关联的单词历史是
{ HoW 1 A , ⋯ , HoW m A } , { HoW 1 B , ⋯ , HoW n B } ⊂ R d h \{\text{HoW}^A_1,\cdots, \text{HoW}^A_m\}, \,\, \{\text{HoW}^B_1,\cdots, \text{HoW}^B_n\} \subset \Bbb R^{d_h} {
HoW1A,⋯,HoWmA},{
HoW1B,⋯,HoWnB}⊂Rdh
其中 d h ≫ d d_h \gg d dh≫d。通过标准的注意力方法融合 B B B到 A A A中,针对 A A A中的每个 h i A h^A_i hiA,
- 为 B B B中的每个 h j B h^B_j hjB计算注意力得分 S i j = S ( h i A , h j B ) ∈ R S_{ij}= S(h^A_i ,h^B_j) \in \Bbb R Sij=S(hiA,hjB)∈R
- 通过softmax形成注意力权重 α i j = exp ( S i j ) / ∑ k exp ( S i k ) \alpha_{ij} = \exp(S_{ij})/\sum_k \exp(S_{ik}) αij=exp(Sij)/∑kexp(Sik)
- 拼接 h i A h^A_i hiA和它的加权信息 h ^ i A = ∑ j α i j h j B \hat h^A_i =\sum_j \alpha_{ij} h^B_j h^iA=∑jαijhjB
在全感知注意力中,通过单词历史来计算注意力得分
S ( h i A , h j B ) ⟹ S ( HoW i A , HoW j B ) S(h^A_i,h^B_j) \implies S(\text{HoW}^A_i, \text{HoW}^B_j) S(hiA,hjB)⟹S(HoWiA,HoWjB)
为了在注意力中充分利用单词历史信息,我们需要一个合适的注意力打分函数 S ( x , y ) S(x,y) S(x,y)。
常见的做法是: x T U T V y x^TU^TVy xTUTVy,
S i j = ( HoW i A ) T U T V ( HoW j B ) S_{ij} = (\text{HoW}_i^A)^TU^TV(\text{HoW}_j^B) Sij=(HoWiA)TUTV(HoWjB)
其中 U , V ∈ R k × d h U,V \in \Bbb R^{k \times d_h} U,V∈Rk×dh; k k k是注意力隐藏层大小。然而,如果我们直接使用这两个这么大的矩阵会使得模型很难训练。所以作者增加了一个限制, U T V U^TV UTV必须是对称的。对称矩阵能被分解为 U T D U U^TDU UTDU,即
S i j = ( HoW i A ) T U T D U ( HoW j B ) S_{ij} = (\text{HoW}_i^A)^TU^TDU(\text{HoW}_j^B) Sij=(HoWiA)TUTDU(HoWjB)
其中 U ∈ R k × d h U \in \Bbb R^{k \times d_h} U∈Rk×dh; D ∈ R k × k D \in \Bbb R^{k \times k} D∈Rk×k;同时 D D D是对角矩阵。对称形式有利于为不相似的 HoW i A , HoW j B \text{HoW}^A_i,\text{HoW}_j^B HoWiA,HoWjB得到高注意力得分。同时,将非线性与对称形式相结合,以在单词历史的不同部分之间提供更丰富的相互作用。
最终计算注意力得分的公式为:
S i j = f ( U ( HoW i A ) ) T D f ( U ( HoW j B ) ) S_{ij} = f(U(\text{HoW}^A_i))^TDf(U(\text{HoW}^B_j)) Sij=f(U(HoWiA))TDf(U(HoWjB))
其中 f ( x ) f(x) f(x)是逐元素应用激活函数。在下午中,作者令 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)。
全感知融合网络
端到端架构
基于全感知注意力,作者提出了一个端到端架构:全感知融合网络(FusionNet)。给定文本A和文本B,FusionNet将文本B中的信息融合到文本A中,并生成两组向量:
U A = { u 1 A , ⋯ , u m A } , U B = { u 1 B , ⋯ , u n B } U_A = \{u^A_1,\cdots,u^A_m\}, \,\,\,\, U_B = \{u^B_1,\cdots,u_n^B\} UA={
u1A,⋯,umA},UB={
u1B,⋯,unB}
下面,我们考虑特殊情况,文本A是阅读理解中的上下文C,文本B是问题Q。
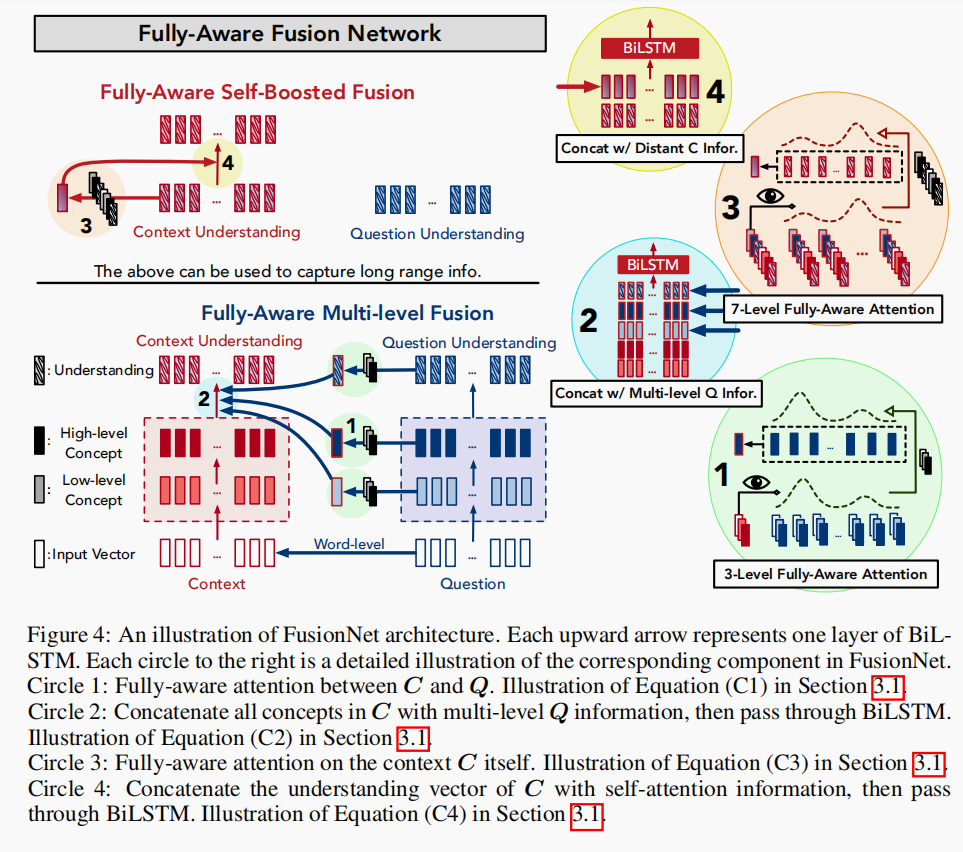
FusionNet图示。每个向上的箭头代表BiLSTM的一层。右边的每个圆圈都是FusionNet中相应组件的详细说明。
圆圈1: C和Q之间的全感知注意力。描述了下面的公式(C1)
圆圈2: 将C中的所有信息与多层次的Q信息连接起来,然后经过BiLSTM。描述了下面的公式(C2)
圆圈3:上下文C的自全感知注意。描述了下面的公式(C3)
圆圈4: 将C的理解向量和自注意信息拼接起来,然后经过BiLSTM。描述了下面的公式(C4)
FusionNet的示意图如上,它包含以下组件:
输入向量 首先,每个C和Q中的单词被转换为一个输入向量 w w w。这里使用了300维的GloVe嵌入和600维的contextualized向量。在SQuAD任务中,作者还为上下文C增加了12维的POS嵌入和8维的NER嵌入,以及C的归一化的词频。一起形成了
{ w 1 C , ⋯ , w m C } ⊂ R 900 + 20 + 1 , { w 1 Q , ⋯ , w n Q } ⊂ R 900 \{w_1^C,\cdots,w^C_m\} \subset \Bbb R^{900+20+1}, \{w^Q_1,\cdots,w^Q_n\} \subset \Bbb R^{900} {
w1C,⋯,wmC}⊂R900+20+1,{
w1Q,⋯,wnQ}⊂R900
全感知多层融合:单词级 在多层融合时,作者分别考虑了单词级融合和高层融合的情况。单词级融合告诉C关于Q中有什么类型的单词。如Figure 2中的箭头(1)所示。首先,为C中的每个单词创建一个特征向量 e m i em_i emi,以指示该单词是否出现在问题Q中。其次,对GloVe嵌入 g i g_i gi采用基于注意力的融合技术:
g ^ i C = ∑ j α i j g j Q , α i j ∝ exp ( S ( g i C , g j Q ) ) , S ( x , y ) = ReLU ( W x ) T ReLU ( W y ) \hat g_i^C =\sum_j \alpha_{ij} g_j^Q, \,\, \alpha_{ij} ∝ \exp(S(g_i^C,g^Q_j)), \,\, S(x,y) = \text{ReLU}(Wx)^T \text{ReLU}(Wy) g^iC=j∑αijgjQ,αij∝exp(S(giC,gjQ)),S(x,y)=ReLU(Wx)TReLU(Wy)
其中 W ∈ R 300 × 300 W \in \Bbb R^{300 \times 300} W∈R300×300。此时单词历史是输入向量本身,所以没有应用全感知注意力。最终得到上下文的增强的入向量 w ^ i C = [ w i C ; e m i ; g ^ i C ] \hat w_i^C = [w_i^C;em_i;\hat g_i^C] w^iC=[wiC;emi;g^iC]
阅读 在阅读组件中,作者分别为C和Q使用一个BiLSTM来形成低层和高层信息。
h 1 C l , ⋯ , h m C l = BiLSTM ( w ^ 1 C , ⋯ , w ^ m C ) , h 1 Q l , ⋯ , h n Q l = BiLSTM ( w ^ 1 Q , ⋯ , w ^ n Q ) h_1^{Cl},\cdots,h_m^{Cl} = \text{BiLSTM}(\hat w_1^C,\cdots, \hat w_m^C),\,\, h_1^{Ql},\cdots,h_n^{Ql} = \text{BiLSTM}(\hat w_1^Q,\cdots, \hat w_n^Q) h1Cl,⋯,hmCl=BiLSTM(w^1C,⋯,w^mC),h1Ql,⋯,hnQl=BiLSTM(w^1Q,⋯,w^nQ)
h 1 C h , ⋯ , h m C h = BiLSTM ( h 1 C l , ⋯ , h m C l ) , h 1 Q h , ⋯ , h n Q h = BiLSTM ( h ^ 1 Q l , ⋯ , h ^ n Q l ) h_1^{Ch},\cdots,h_m^{Ch} = \text{BiLSTM}(h_1^{Cl},\cdots,h_m^{Cl}),\,\, h_1^{Qh},\cdots,h_n^{Qh} = \text{BiLSTM}(\hat h_1^{Ql},\cdots, \hat h_n^{Ql}) h1Ch,⋯,hmCh=BiLSTM(h1Cl,⋯,hmCl),h1Qh,⋯,hnQh=BiLSTM(h^1Ql,⋯,h^nQl)
这样就得到了每个单词的低层和高层信息 h l , h h ∈ R 250 h^l,h^h \in \Bbb R^{250} hl,hh∈R250
问题理解 作者应用一个新的BiLSTM,同时输入 h Q l h^{Ql} hQl和 h Q h h^{Qh} hQh去获得最终的问题表示 U Q U_Q UQ:
U Q = { u 1 Q , ⋯ , u n Q } = BiLSTM ( [ h 1 Q l ; h 1 Q h ] , ⋯ , [ h n Q l ; h n Q h ] ) U_Q = \{u^Q_1,\cdots,u_n^Q\} = \text{BiLSTM}([h_1^{Ql};h_1^{Qh}],\cdots, [h_n^{Ql};h_n^{Qh}]) UQ={
u1Q,⋯,unQ}=BiLSTM([h1Ql;h1Qh],⋯,[hnQl;hnQh])
其中 { u i Q ∈ R 250 } i = 1 n \{u^Q_i \in \Bbb R^{250}\}_{i=1}^n {
uiQ∈R250}i=1n是问题Q的理解向量。
全感知多层融合:高层 这个组件通过对单词历史的全感知注意力,将问题Q中的所有高层信息与上下文C融合。由于所提出的针对全感知注意的注意力评分函数被限制为对称的,因此我们需要识别C,Q的共同历史单词,得到
HoW i C = [ g i C ; c i C ; h i C l ; h i C h ] , HoW i Q = [ g i Q ; c i Q ; h i Q l ; h i Q h ] ∈ R 1400 \text{HoW}_i^C =[g_i^C;c^C_i;h_i^{Cl};h_i^{Ch}],\,\, \text{HoW}_i^Q=[g_i^Q;c^Q_i;h_i^{Ql};h_i^{Qh}] \in \Bbb R^{1400} HoWiC=[giC;ciC;hiCl;hiCh],HoWiQ=[giQ;ciQ;hiQl;hiQh]∈R1400
其中 g i g_i gi为GloVe嵌入, c i c_i ci为CoVe嵌入。然后,我们通过全感知注意力,将从Q到C的低层、高层和理解层的信息融合起来。通过注意函数 S l ( x , y ) , S h ( x , y ) , S u ( x , y ) S^l(x,y),S^h(x,y),S^u(x,y) Sl(x,y),Sh(x,y),Su(x,y)计算不同层的注意力权重,以融合低层、高层和理解层的信息。这三个函数都是前文提出的非线性对称形式,但参数独立,以关注不同层次的不同区域。注意隐藏大小设置为 k = 250 k = 250 k=250。
-
低层融合:
h ^ i C l = ∑ j α i j l h j Q l , α i j l ∝ exp ( S l ( HoW i C , HoW j Q ) ) (C1) \hat h_i^{Cl} = \sum_j \alpha_{ij}^l h_j^{Ql}, \,\, \alpha_{ij}^l ∝ \exp \left(S^l(\text{HoW}_i^C,\text{HoW}_j^Q )\right) \tag{C1} h^iCl=j∑αijlhjQl,αijl∝exp(Sl(HoWiC,HoWjQ))(C1) -
高层融合:
h ^ i C h = ∑ j α i j h h j Q h , α i j h ∝ exp ( S h ( HoW i C , HoW j Q ) ) (C1) \hat h_i^{Ch} = \sum_j \alpha_{ij}^h h_j^{Qh}, \,\, \alpha_{ij}^h ∝ \exp \left(S^h(\text{HoW}_i^C,\text{HoW}_j^Q )\right) \tag{C1} h^iCh=j∑αijhhjQh,αijh∝exp(Sh(HoWiC,HoWjQ))(C1) -
理解融合:
u ^ i C = ∑ j α i j u u j Q h , α i j u ∝ exp ( S u ( HoW i C , HoW j Q ) ) (C1) \hat u_i^C = \sum_j \alpha_{ij}^u u_j^{Qh}, \,\, \alpha_{ij}^u ∝ \exp \left(S^u(\text{HoW}_i^C,\text{HoW}_j^Q )\right) \tag{C1} u^iC=j∑αijuujQh,αiju∝exp(Su(HoWiC,HoWjQ))(C1)
这种多层次的关注机制独立捕获不层级别的信息,同时考虑到所有层级的信息。应用新的BiLSTM来获取完全融合了问题Q信息的上下文C的表示:
{ v 1 C , ⋯ , v m C } = BiLSTM ( [ h 1 C l ; h 1 C h ; h ^ 1 C l ; h ^ 1 C h ; u 1 C ] , ⋯ , [ h m C l ; h m C h ; h ^ m C l ; h ^ m C h ; u m C ] ) (C2) \{v^C_1,\cdots, v_m^C\} = \text{BiLSTM}([h_1^{Cl};h_1^{Ch};\hat h_1^{Cl};\hat h_1^{Ch};u_1^{C}], \cdots, [h_m^{Cl};h_m^{Ch};\hat h_m^{Cl};\hat h_m^{Ch};u_m^{C}]) \tag{C2} {
v1C,⋯,vmC}=BiLSTM([h1Cl;h1Ch;h^1Cl;h^1Ch;u1C],⋯,[hmCl;hmCh;h^mCl;h^mCh;umC])(C2)
全感知自提升融合 我们现在使用自提升(self-boosted)融合来考虑上下文中的远距离部分,如Figure 2中的箭头(3)所示。同样,我们通过全感知注意历史单词来达到这一点。我们确定历史单词为:
HoW i C = [ g i C ; c i C ; h i C l ; h i C h ; h ^ i C l ; u ^ i C ; v i C ] ∈ R 2400 \text{HoW}_i^C = [g_i^{C};c_i^{C}; h_i^{Cl};h_i^{Ch};\hat h_i^{Cl};\hat u_i^{C}; v_i^C] \in \Bbb R^{2400} HoWiC=[giC;ciC;hiCl;hiCh;h^iCl;u^iC;viC]∈R2400
然后应用全感知注意,
v ^ i C = ∑ j α i j s v j C , α i j s ∝ exp ( S s ( HoW i C , HoW j C ) ) (C3) \hat v_i^C = \sum_j \alpha_{ij}^s v_j^C, \,\, \alpha_{ij}^s ∝ \exp \left(S^s(\text{HoW}_i^C,\text{HoW}_j^C) \right) \tag{C3} v^iC=j∑αijsvjC,αijs∝exp(Ss(HoWiC,HoWjC))(C3)
最终的上下文表示由以下方法获得:
U C = { u 1 C , ⋯ , u m C } = BiLSTM ( [ v 1 C ; v ^ 1 C ] , ⋯ , [ v m C ; v ^ m C ] ) (C4) U_C = \{u_1^C,\cdots, u_m^C\} = \text{BiLSTM}([v_1^C;\hat v_1^C], \cdots, [v^C_m;\hat v_m^C]) \tag{C4} UC={
u1C,⋯,umC}=BiLSTM([v1C;v^1C],⋯,[vmC;v^mC])(C4)
其中 { u i C ∈ R 250 } i = 1 m \{u^C_i \in \Bbb R^{250}\}_{i=1}^m {
uiC∈R250}i=1m是C的理解向量。
在经过FusionNet中的这些组件之后,我们为上下文C创建了理解向量 U C U_C UC,这些向量与问题Q完全融合。我们还有问题Q的理解向量 U Q U_Q UQ。