First published on indexfziq.github.io at 2019-01-17 19:10:40.
Introduction
本文出自微软亚研院,一作是北航的Chuanqi Tan, 代码没有公开,链接为台湾的一位同学用CNTK实现的代码。首次使用了Seq2Seq模型对MS-MARCO阅读理解数据集进行答案生成,比较符合MS-MARCO的本意,同时定义了先抽取再生成的框架,在R-Net的基础上有一定的提升。
模型在MS-MARCO V1的排名是第三,效果与抽取式的模型结构并没有太大的提升,这也让人怀疑Seq2Seq的作用到哪里去了。文章有几处疑点,一是Attention Pooling时,公式有些问题;二是Seq2Seq的输入到底是什么,如果出现答案来自于多篇文章的情况,输入还是按照答案-文档对来做的吗?
Motivation
这篇文章的动机就是抽取式的网络结构并不适合微软阅读理解数据集,有很多情况下,答案需要根据问题和文档组合或者生成。如图所示,除了第一种情况,其他都不能简单的抽出来。

Contribution
- 为多篇章阅读理解(或者说生成式)提出了一个先抽取再生成的框架;
- 在抽取的模块,采用多任务学习,利用Page ranking这个辅助任务帮助抽取答案片段;
- 第一个将序列到序列模型应用到阅读理解数据集。
Model
下面对模型详细介绍:模型整体比较复杂,大体就是R-Net和Seq2Seq的组合。
Overview

由上图可以看出,整个模型是一个pipeline结构,并不是端到端的,Seq2Seq的效果本来就不是很好,因此第一个模块抽取的质量很关键,能把Seq2Seq用上本身就是一种突破。
模型分两个模块,分别是Evidence Extraction Model和Answer Synthesis Model。
Evidence Extraction Model
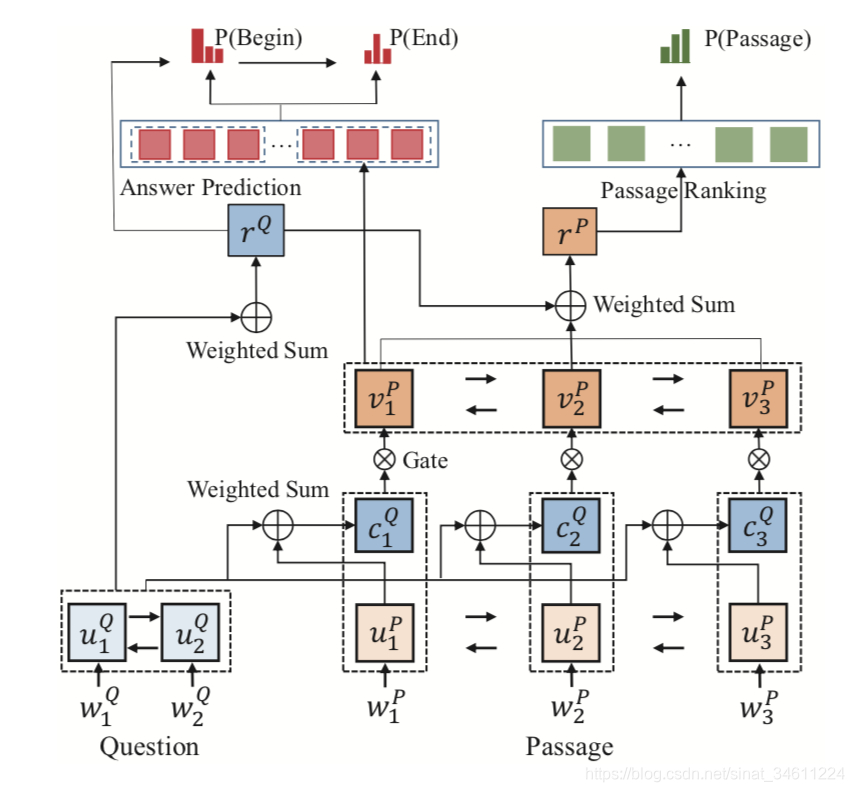
这个模型从本质上讲和R-Net有很大的相似性,只是没有高层的self-attention。
Embedding Layer
该层的输入就两个,词级别的表示和字符级别的表示,然后喂给双向GRU得到最终的表示 。
Question-aware passage representation
这部分就是passage对query做attention,得到权重化的表示,也就是所谓的Question-aware。这部分较复杂,过程简单来讲就是计算attention,过门控函数,再用GRU得到表示 。
之后还是一个计算attention的过程, 做一个self-attention,得到最终的表示 。然后用得到的问题表示 与GRU得到表示 做attention,加权求和得到最终的passage表示 。
这里可以提一下多任务学习中的硬共享模式,这两个表示也就硬共享模式中的shared representation,在此基础上,在根据任务在最后一层有不同的输出。任务分别是Evidence Prediction和Page Ranking。
Evidence Prediction
主要思想就是指针网络,求span起始位置和终止位置的概率值。
首先用问题最后的表示 初始化GRU的第0时刻的隐藏层状态 ,然后就是标准的pointer network。输入是 和 ,GRU之后过softmax,选择概率最大的作为输出。
Page Ranking
这个任务本质上是个二分类问题,合理利用了数据集中给的标注,问题的答案是否用到当前passage的内容,用到标为1,没用到标为0。直接把 和 喂给分类器就可以了,任务简单,但是给了抽取任务一定的监督信号,有一定的辅助作用。
Training for Evidence Extraction Model
抽取模块的损失函数分两部分,用超参去调相应的比重。
Answer Synthesis Model
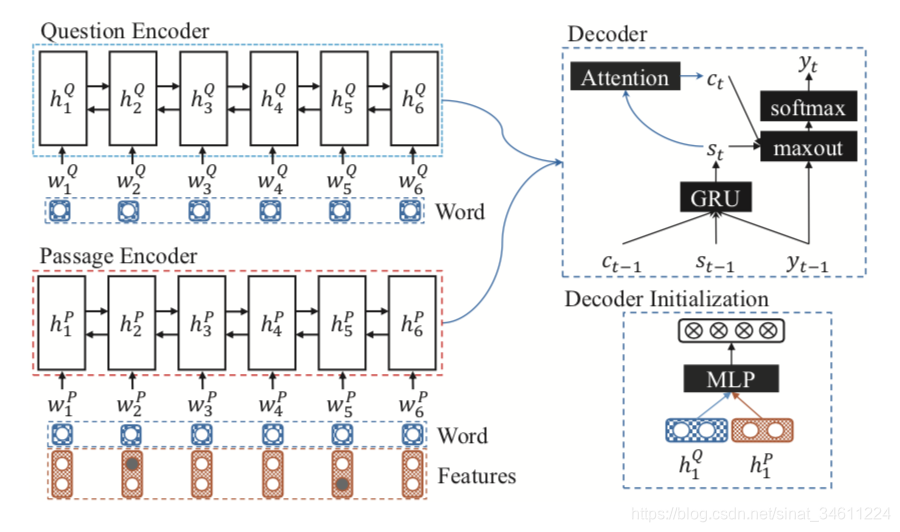
抽取片段的模型部分得到evidence,之后并不是直接就作为Seq2Seq的输入,中间还有一定的处理过程。
Initialization
首先,用BiGRU得到问题和文档的表示,文档的表示是由抽取模块处理好的passage(把起始位置和终止位置作为特征)作为输入,用0/1表示。
其中,
用来表示span的起止位置,然后
初始化Seq2Seq,其中:
这里就是取BiGRU的第一个隐藏层状态作为MLP的输入得到Seq2Seq所需要的
。
Answer Synthesis
答案合成这个部分就是标准的Attention-based Seq2Seq,图上画的也比较清楚了,公式如下
其中Attention是的计算就是最普通的Global Attention。最终的输入在过Maxout激活函数和softMax,即得到概率分布。
Training for Answer Synthesis Model
答案合成模块的损失函数就是负对数似然。
Experiments

从实验结果上可以看出,S-Net的答案抽取模块并没有R-Net好,虽然加了一个Passage Ranking的辅助任务,但是还是没有对Passage representation最后再做一次self-attention效果好。不过,最后加上Seq2Seq效果好很多,接近人类的水平,个人观点是在抽取span之后处理的好,当然不可否认可以把Seq2Seq训练好也不容易了。
Conclusion
最后,对S-Net做一个简单的总结:
- 为多篇章(生成式)阅读理解提供了一个先抽取再生成的框架;
- 使用多任务学习辅助训练主任务;
- 第一次将Seq2Seq应用到阅读理解的任务中。
另外,如有错误或者不对的地方,请您提出宝贵意见!
References
- S-Net: From Answer Extraction to Answer Generation for Machine Reading Comprehension. JChuanqi Tan, Furu Wei, Nan Yang, Bowen Du, Weifeng Lv and Ming Zhou. AAAI 2018.
- MAMARCO leaderboard: http://www.msmarco.org/leaders.aspx
- MAMARCO Analysis: https://github.com/IndexFziQ/MSMARCO-MRC-Analysis