《S-Net: From Answer Extraction to Answer Synthesis for Machine Reading Comprehension》
这篇文章是发表在2018年AAAI上的,应该算是比较早的生成式的模型。在微软发布的MS MARCO数据集上得到了SOTA效果。
分以下五部分介绍:
- Dataset
- Motivation
- Model
- Experiment
- Discussion
因为之前没有了解过 MARCO数据集,所以先简单介绍一下该数据集。和其他数据集对比一下。
1、DATASET
SQuAD是抽取式的,来自于维基百科语料,问题是人产生的,答案是span;相较SQuAD 1.1中的10万问答,SQuAD 2.0又新增了5万个人类撰写的问题——而且问题不一定有对应答案,要求机器能从对应段落中找到问题答案,还测试机器在没有对应答案时可以say No。
NarrativeQA来自于书本和电影剧本的1567个完整故事和摘要,共有 46,765个问题答案对,问题由人类基于摘要编写,答案也是。读者必须阅读整本书或整个剧本才能回答有关故事的问题,也就是说必须彻底理解了故事内容后,才有可能成功回答深层次的问题。
MARCO是生成式的,包含10W个问题对。来自网页真实用户的query,passage是检索目标中的top-10的摘要,多文档的。答案由人工给出,V2.0的答案更加well formed。
2、Motivation
主要是针对SQuAD数据集:
- First, the SQuAD dataset constrains the answer to be an exact sub-span in the passage, while words in the answer are not necessary in the passages in the MS-MARCO dataset.答案不一定是文章中的
- Existing methods for the MS-MARCO dataset usually follow the extraction based approach for single passage in the SQuAD dataset, while the MS-MARCO dataset contains multiple passages.So developing an extraction-then-synthesis framework to synthesize answers from extraction results.现存的MARCO的方法大都是基于SQUAD的方法,但是本数据集是多文档的,所以提出先抽取再综合的框架并且加入额外的passage rank多任务学习
3、Model
看模型的时候感觉好像没有实现多文档的解决方方案,包括最后作者也说对于多文档问题是未来的研究点。
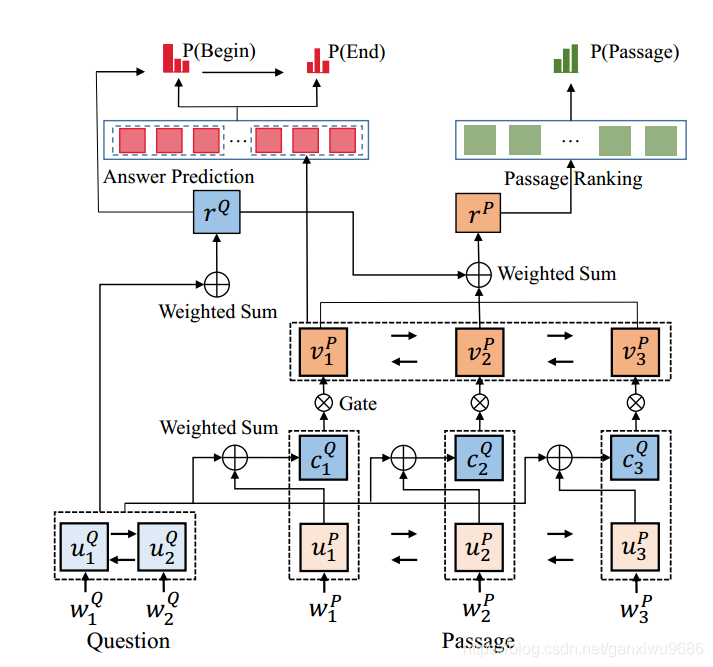
3.1 overview

模型的整体结构首先先抽取相关的evidence,然后通过综合文档问题以及evidence去进行答案的生成。
3.2 EVIDENCE EXTRACTION
将文档和问题当中的词转成对应的词向量和字符向量。字符向量通过双向gru的最后隐藏状态获得。
然后再通过一个双向gru将字符向量和词向量连接,得到文档和问题的表示。
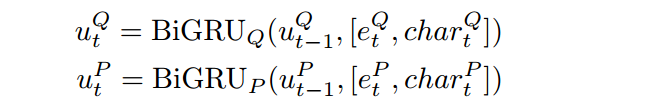
随后,generating sentence-pair representation (融合了问题信息)
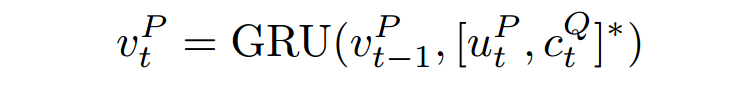
其中Ct如下方式获得:
在t时刻p中的词对q中所有的词作一个attention,然后加权求和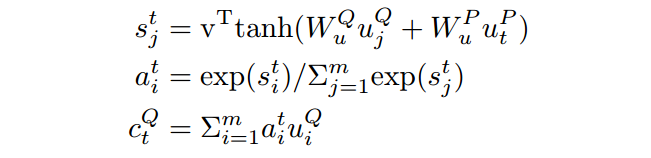
Wang et al. (2017) [1]提出一种门机制过滤掉文章中不重要的词:
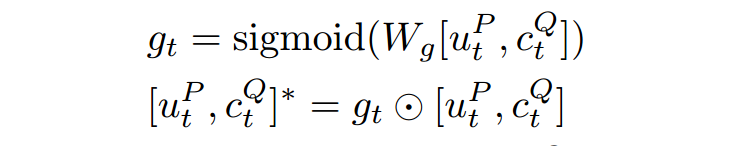
获得融合了问题的文档的表示之后,使用指针网络去预测出evidence的位置.
指针网络是一个gru,初始状态用问题的表示获得,即rQ。
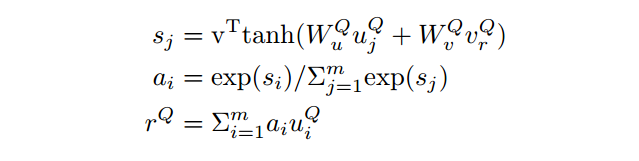
随后根据这个状态和融合了问题的文档的表示去进行attention的计算。最后能够得到,整篇文档中的一个打分,并且把打分最高的那个作为开始为止。
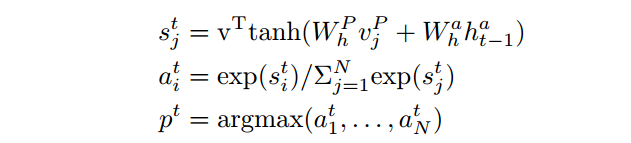
更新指针网络状态,对文档的表示通过打分,再做一个加权求和,得到上下文向量表示c,更新隐状态。
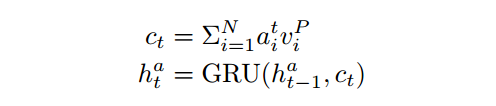
这个地方文章说的是把所有的文档连接起来,去预测出一个span
3.2.2 PASSAGE RANK
通过
和
计算attention,得到整个文档的表示
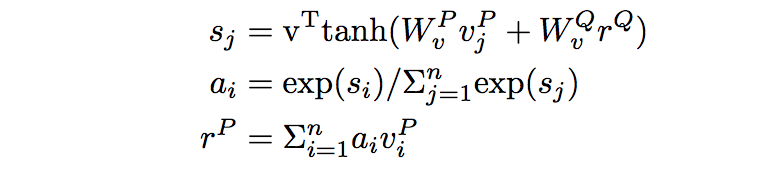
接着
和
经过两层全联接,得到一个匹配得分:
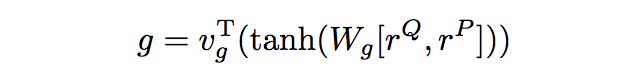
目标函数:
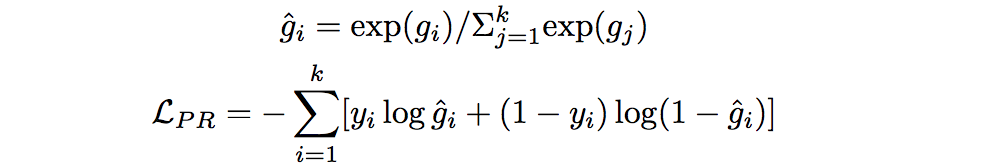
k表示文档的数量,
表示第i篇文档是和答案有关的
最后联合学习:

试验部分也说明了联合学习比先排序,选出top-3文档再进行span prediction效果好。即使这部分的联合学习是把所有的文档连接起来在去预测span。
3.3 ANSWER SYNTHESIS
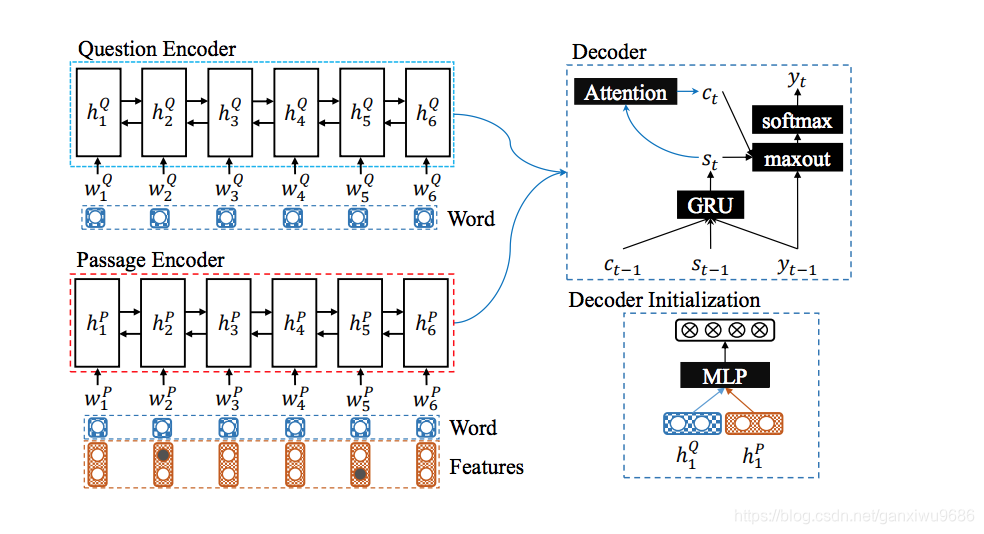
(在第二个模型里 ,start和end作为feature输入,此时的文档是span所在的一篇文档)
将evidence的feature和文档问题共同作为seq2seq模型的输入,
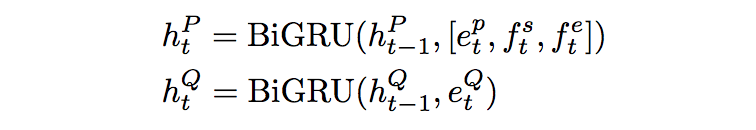
解码部分为带有attention的gru。解码时刻t,使用t-1时刻的词向量、上下文向量作为输入,得到gru的隐状态更新。gru的初始状态使用一个前馈网,h1表示backward的最后一个状态:

表示问题和文档的encoder,再对所有的隐状态加权求和得到
上下文表示
: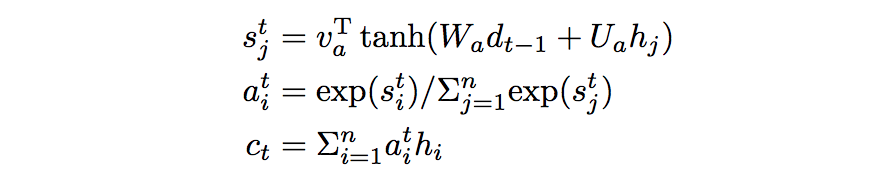
最后,开始预测答案通过softmax预测出最有可能的词。
的解释并不是很懂。放出原文:
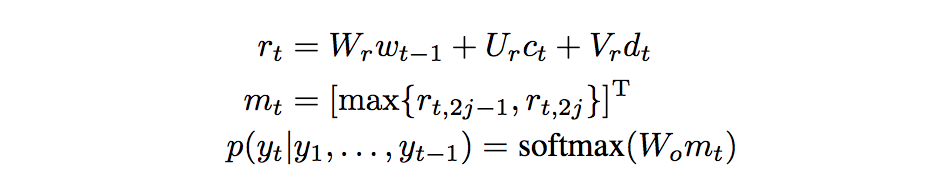

最大似然作为loss fun:

4、Experiment
1、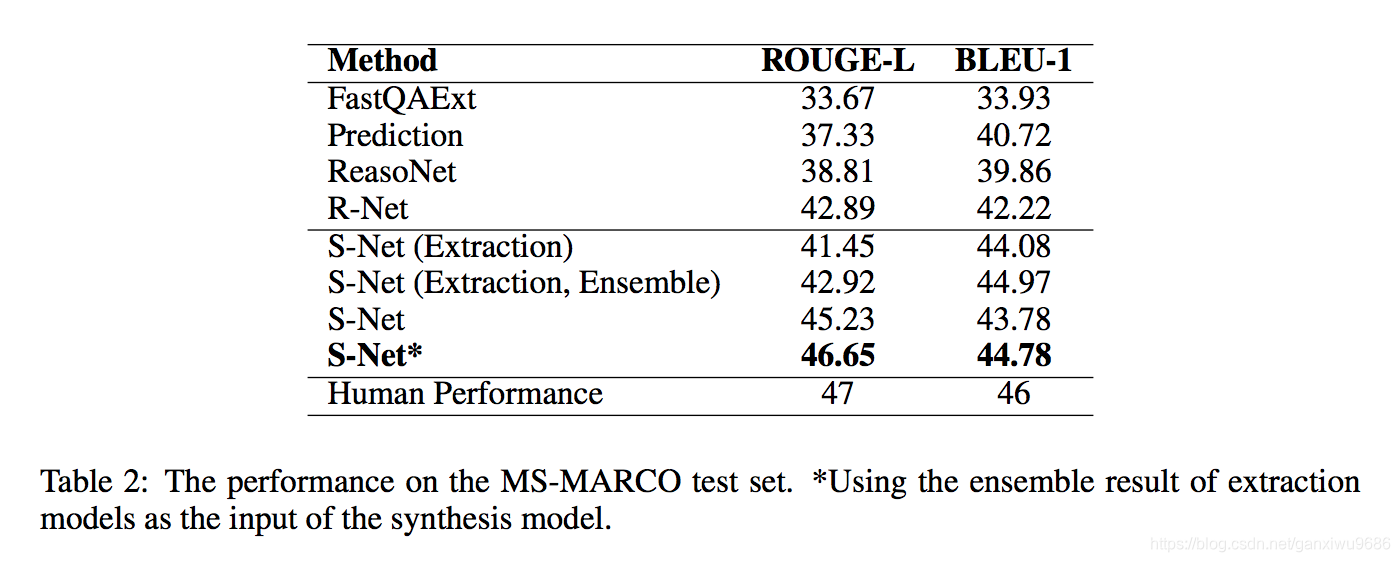
S-Net (Extraction): the model that only has the evidence extraction part
实验结果说明,针对MARCO数据集,生成式的S-net效果确实比抽取式的好。
2、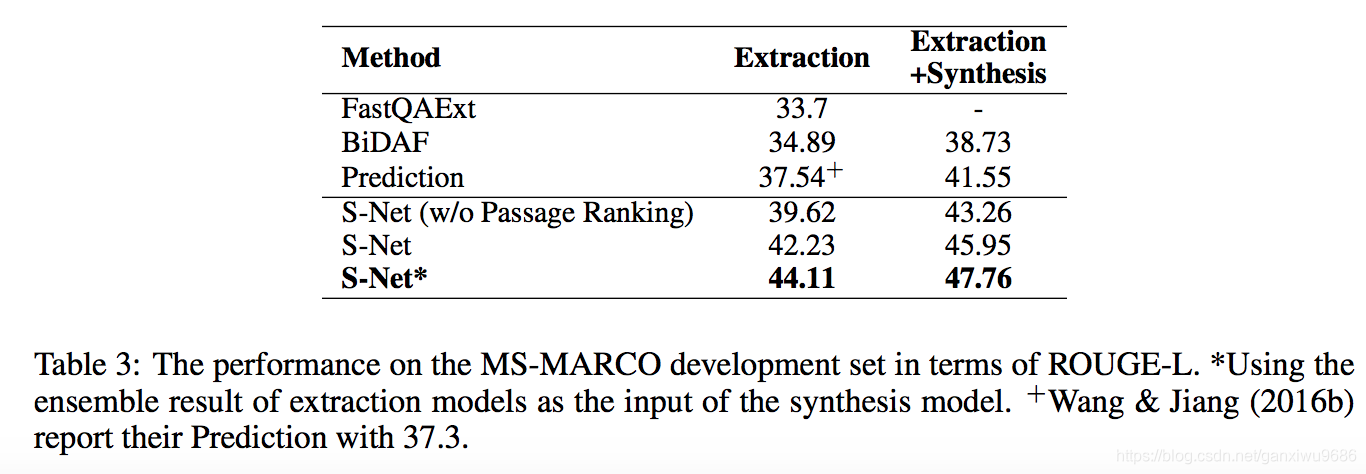
验证集上的Rouge指标,在其他模型上增加了综合答案生成,效果确实也提升了。
3、
这个效果说明了多任务学习的重要性。解释性就是在预测span的时候提供了监督信号。
4、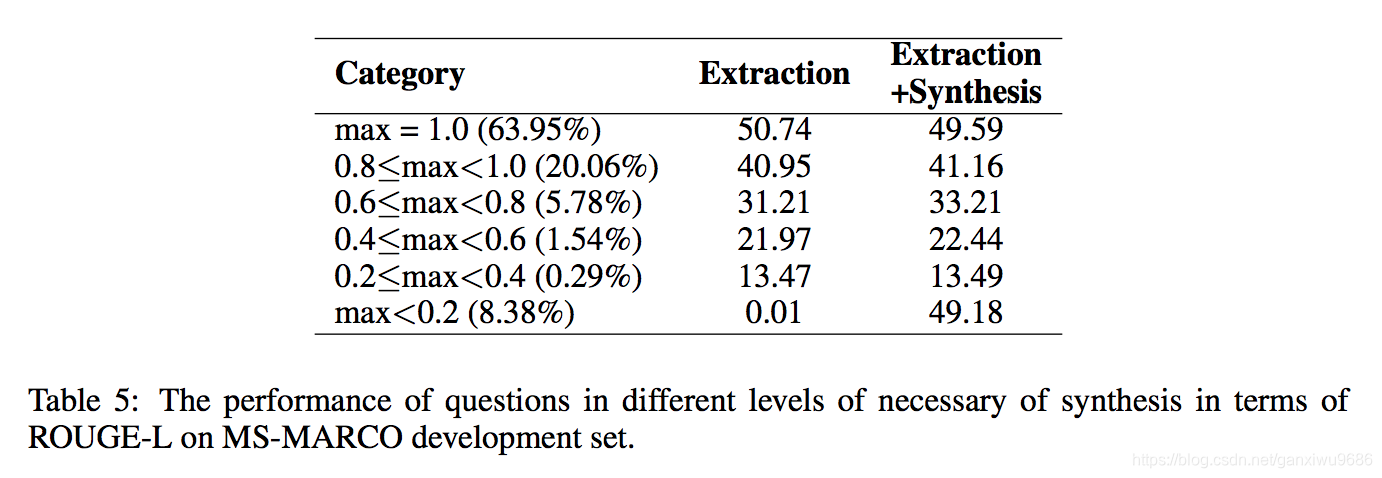
答案和文中的span完全匹配(max=1),非常不匹配(max<0.2)可以看到在这些实例中,通过生成式的方法,效果显著提高。
5、Discussion
这篇文章的思路还是很不错的,就是有部分感觉写的不是很清楚。如:既然想解决多文档的问题,为什么在第一个模型的时候把所有的文档连接起来然后预测一个span。第二,还有些公式有问题。第三,公式和图某些部分不匹配。
[1]Wenhui Wang, Nan Yang, Furu Wei, Baobao Chang, and Ming Zhou. Gated self-matching networks for reading comprehension and question answering.