英文题目:
MACHINE COMPREHENSION USING MATCH-LSTM AND ANSWER POINTER
作者:Shuohang Wang, Jing Jiang
论文出处:ICLR 2017
中文题目:
使用match-LSTM与回答指针的机器理解
论文原文下载:pdf下载
一、科学问题
1.1 本文所涉及科学问题
自然语言处理中的机器阅读理解方向。首先向机器显示一段文本,比如一篇新闻文章或一个故事。然后,机器将回答与文本相关的一个或多个问题。
1.2 同行专家如何解决
将一个问题可以看作是一个选择题,其正确答案是从一组提供的候选答案中选择出来的,例如Richardson(2013年)与Hill(2016)等人。Rajpurkar在2016年提出的SQuAD数据集中,其正确答案可以是从给定文本中的任意符号序列。Hermann(2015)与Hill (2016)等人的数据集的问题和答案是用完形填空的方式自动创建的。Hermann(2015)、Kadlec(2016)、Cui等人(2016)是假设回答是一个单一的符号(a single token)
1.3 本文所解决的问题
(解决什么问题,效果如何,一般摘要及总结中都会有)
使用SQuAD数据集来研究文本的机器理解。SQuAD中的answers不是来自一小组候选答案,且它们的长度是可变的。本文为本问题提出新的模型来应用SQuAD数据集实现机器理解。
1.4 本文解决方案效果
提出一种端到端的模型结构。该模型使用match-LSTM与Pointer Net。在模型中分别应用了两种Pointer Net的使用方式。实验证明着两种模型的效果是胜出Rajpurkar在2016年提出人工提取特征的逻辑回归模型的最好实验结果
二、研究内容
2.1 理论与方法介绍
(论文主要研究内容的提出,主要技术路线、理论与方法介绍)
主要技术理论:
- match-LSTM
match-LSTM于2016年首次被Wang & Jiang提出,并应用于自然语言处理中的文本蕴含任务。在文本蕴含任务中,给定两个句子,其中一个句子设为前提,另一个句子设为假设,任务的目标是预测前提是否蕴含假设。Match-LSTM模型是有序地遍历假设的特征单元(可为词、短语等),在假设的每一个遍历位置上,使用注意力机制获得前提的加权向量表示。这个加权前提向量与当前假设的位置上的特征单元的向量表示相结合为一个向量,然后将该向量输入LSTM中。这就是match-LSTM模型结构
- Pointer Net
Pointer Net是Vinyals在2015年提出并应用于产生的输出序列受输入序列的约束。Pointer Net是使用注意力机制作为指针去选择输入序列中的一个位置作为输出符号。
该论文模型结构:
两种模型结构都包含三层结构,两者的不同是在于第三层答案指针层。
第一层:预处理层
该层分别使用标准单向LSTM结构处理了passage与question
![]()
其中,![]() ,
,![]() 是词向量的维度
是词向量的维度
第二层:match-LSTM层

其中,![]() ,
,![]() 是注意力加权向量。与passage结合为
是注意力加权向量。与passage结合为

然后将![]() 输入到LSTM中,
输入到LSTM中,
![]()
该过程还需要反向的match-LSTM,其过程与上面一样,其反向过程中的参数![]() 与上面式(2)相同,即是同一参数。
与上面式(2)相同,即是同一参数。
设![]() 是
是![]() ,同样
,同样![]() =
=![]() ,最后获得
,最后获得

第三层:答案指针层
![]() 作为答案指针层的输入,该层使用了两种Pointer Net:序列模型与边界模型。
作为答案指针层的输入,该层使用了两种Pointer Net:序列模型与边界模型。
- 序列模型
序列模型生成一个答案标记序列,但这些标记在原始passage中可能不是连续的。![]() ,
,![]() 是1到P之间的整数,即是passage中的位置。设
是1到P之间的整数,即是passage中的位置。设![]() ,k取值1到P+1,当k=P+1,时,停止产生答案。即
,k取值1到P+1,当k=P+1,时,停止产生答案。即![]() (k=P+1)为答案结束标记位。
(k=P+1)为答案结束标记位。
为获取答案![]() ,使用注意力机制,
,使用注意力机制,

定义下列:
![]()
![]()
答案序列:![]()

然后可以将生成答案序列的概率建模为
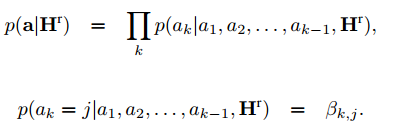
训练模型,最小化以下损失函数:

- 边界模型只生成答案的开始标记和结束标记,然后将原始段落中这两个标记之间的所有标记视为答案。
边界模型的基本原理与序列模型一样,只有预测概率那里不一样,边界模型只需要预测


2.2 验证分析与实验效果
(论文中的实验分析和实验效果)
数据集:![]()
训练集:87599问答对 开发集:10570问答对 测试集:隐藏
使用GloVe模型训练词向量。词向量维度设置为150或300,使用![]() 的
的![]() 来优化模型。
来优化模型。
模型性能评估,两种评估方法:将预测答案中的标记与基本真实答案中的标记进行比较时,与基本真实答案中的标记精确匹配的百分比,以及单词级F1得分进行评估。
结果:

三、论文存在问题及后续研究重点
3.1 论文存在问题
该论文提出的模型对于较长的答案更难预测。对于‘为什么’这样的问题,模型较难作出答案。
3.2 后续研究重点
计划进一步研究不同类型的问题,并关注那些目前表现不佳的问题,比如“为什么”问题。还计划测试我们的模型如何应用于其他机器理解数据集。
四、该问题相关研究成果
4.1 相关论文一
(1)题目:Teaching machines to read and comprehend.
(2)作者介绍:Karl Moritz Hermann
(3)摘要: Teaching machines to read natural language documents remains an elusive challenge. Machine reading systems can be tested on their ability to answer questions posed on the contents of documents that they have seen, but until now large scale training and test datasets have been missing for this type of evaluation. In this work we define a new methodology that resolves this bottleneck and provides large scale supervised reading comprehension data. This allows us to develop a class of attention based deep neural networks that learn to read real documents and answer complex questions with minimal prior knowledge of language structure.
4.2 相关论文二
(1)题目:Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
(2)作者介绍:Kumar
(3)摘要:Most tasks in natural language processing can be cast into question answering (QA) problems over language input. We introduce the dynamic memory network (DMN), a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers. Questions trigger an iterative attention process which allows the model to condition its attention on the inputs and the result of previous iterations. These results are then reasoned over in a hierarchical recurrent sequence model to generate answers. The DMN can be trained end-to-end and obtains state-of-the-art results on several types of tasks and datasets: question answering (Facebook's bAbI dataset), text classification for sentiment analysis (Stanford Sentiment Treebank) and sequence modeling for part-of-speech tagging (WSJ-PTB). The training for these different tasks relies exclusively on trained word vector representations and input-question-answer triplets.
4.3 相关论文三
(1)题目:Text understanding with the attention sum reader network.
(2)作者介绍:Kadlec
(3)摘要:Several large cloze-style context-question-answer datasets have been introduced recently: the CNN and Daily Mail news data and the Children's Book Test. Thanks to the size of these datasets, the associated text comprehension task is well suited for deep-learning techniques that currently seem to outperform all alternative approaches. We present a new, simple model that uses attention to directly pick the answer from the context as opposed to computing the answer using a blended representation of words in the document as is usual in similar models. This makes the model particularly suitable for question-answering problems where the answer is a single word from the document. Ensemble of our models sets new state of the art on all evaluated datasets.