来源
arXiv 2016.10.31
问题
当前的 RC 模型都是生成单个实体或者单个词,不能够根据问题动态生成答案。基于此,本文提出了 end2end 的 chunk 抽取神经网络。
文章思路
Dynamic Chunk Reader 这一模型分成四步:
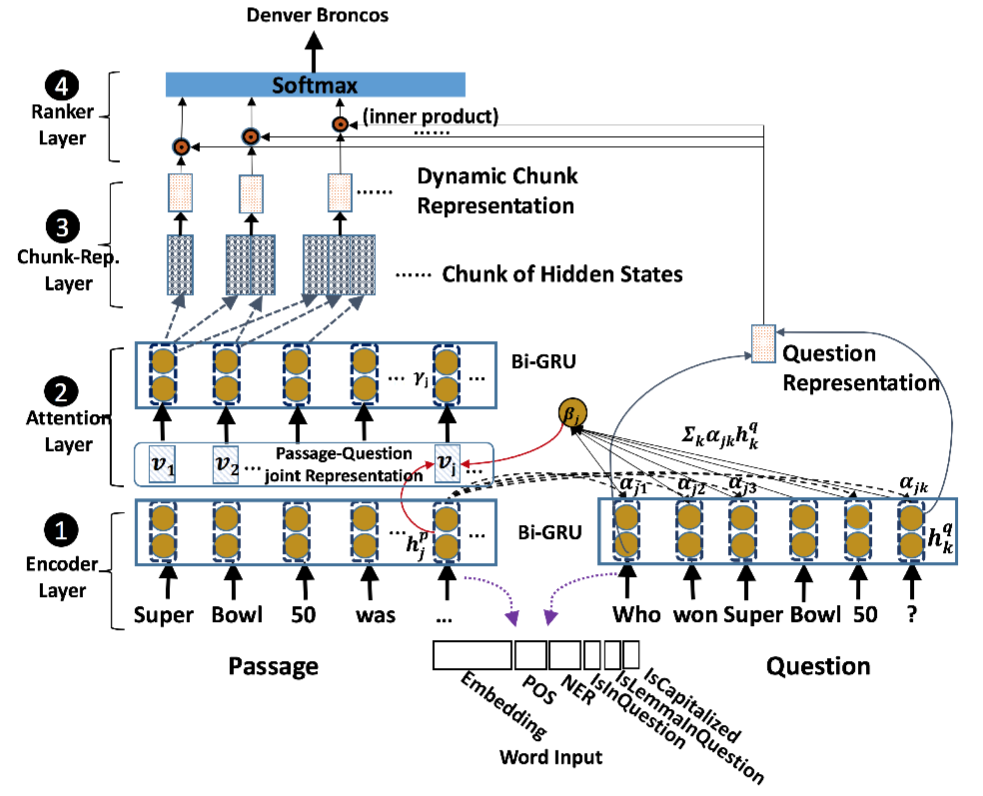
- encode layer 分别使用 bi-GRU 对 passage 和 question 进行编码,这里面的每个词的表示是由 word embedding 和 word features(POS、NER、IsInQuestion、IsLemmaInQuestion、IsCapitalized) 组成。
- attention layer 利用如下公式计算 passage 和 question 的相关性
αjk=hpj⋅hqkβj=∑k=1|Q|αjkhqkvj=[hpj;βj]
从而得到 passage-question joint representation 向量 vj
- ,之后再次利用 bi-GRU 得到 context embedding。
- chunk representation layer 从给定 passage 中动态抽取 chunk,并构造 chunk 表示。具体是这样的:对于 passage 中每个词枚举所有 chunk 可能 (设置了 max chunk length),然后 chunk 中第一个词的前向 RNN 表示和最后一个词的后向 RNN 表示结合作为 chunk 表示。
- rank layer 将 question 的前向后向 last hidden state 拼接得到 question representation。把所有 candidate chunk 表示与 question represention 做点积后,经过 softmax 输出结果。
训练时,最小化如下 negative log likelihood
这里 i-th 训练实例只在 Ai 包含在对应的 candidate chunk set Ci
资源
论文地址:https://uk.arxiv.org/abs/1610.09996
数据地址:https://rajpurkar.github.io/SQuAD-explorer/
相关工作
- SQuAD
-
这篇论文给出了一个兼顾质与量的数据集,并且提出 Logistic Regression 的 baseline model,获得 51% 的 F-score,与人类的 86% 相比还有很大提升空间。
这一数据要求利用文中的一段文字来做回答,比 cloze-style 问题要难。将 536 篇文章随机划分成 training set(80%)、development set(10%)、test set(10%)。为了测试的鲁棒性,development set 和 test set 各有 3 个答案。
评测结果有两种标准
- Exact match 衡量预测结果和其中一个答案完全匹配的百分比
- (Macro-averaged) F1-score 计算预测和结果的平均重合率
简评
这篇文章以端到端的方式动态生成 candidate answer chunk,并结合 ranking 得到最终答案,解决了之前模型的一些问题,最终在测试集上取得了 71% 的 F1-score。但是这里的动态 chunk 生成在文中采取了两种方式:POS trie-based 方法和枚举窗口内所有 chunk 的方法。前者出现没见过的 POS pattern 就束手无策;后者生成了大量无效答案。所以 chunk 自动生成还有待思索。
另外文中提出了一种新的 passage 和 question 的 attention 机制,以及利用一些 word feature 强化模型效果,值得借鉴。