First published on indexfziq.github.io at 2019-04-10 17:00:00
Introduction
目前,本文是MARCO数据集NLG任务的第一名,作者是NTT公司的Nishina等人。文章突破了抽取式阅读理解模型的束缚,采用摘要的方式生成指定风格的答案,这两个突破算是GMRC的一个里程碑。在此篇文章之后,分析选手榜可以发现,沿用此方法的模型也都取得了比较好的效果。还有一点值得一提,本文没有用BERT,只用了Transformer和ELMo,效果就已经很不错了,说明BERT在生成式阅读理解上并不是那么的强大。
Background
本文针对的是MARCO数据集,简单介绍一下该数据集的特点。用一句话来概括就是——开放域、多文档、生成式的大规模阅读理解数据集,问题和答案都来自于真实数据,所有问题的答案都是人类生成的,有一定的答案还需要额外的人工评估,也就是well-formed的答案,这个在我的另一个MARCO分析上有详细的解释。数据集的质量很好,并且是很符合人类查找答案回答问题的过程,因为这个数据集的眼光是看的很远的,在此数据集上训练的模型应该很好地迁移到真实的用户场景中。
Motivation
作者发现,之前在MARCO上刷榜的模型大都是抽取式的模型。S-Net除外,但是先抽取再生成的pipeline框架是有点弱了。并且,现有模型不能根据给定的风格生成相应的答案,论文发现,通常Q&A任务的答案比较简短,NLG任务的答案比较详细。本文想从这两个点入手,提出了两个很新奇的点子:
- 把生成式阅读理解当作摘要问题来做,生成问题、段落的摘要作为最终的答案。
- 给定模型风格,训练模型使得其有能力生成相应风格的答案。
Contribution
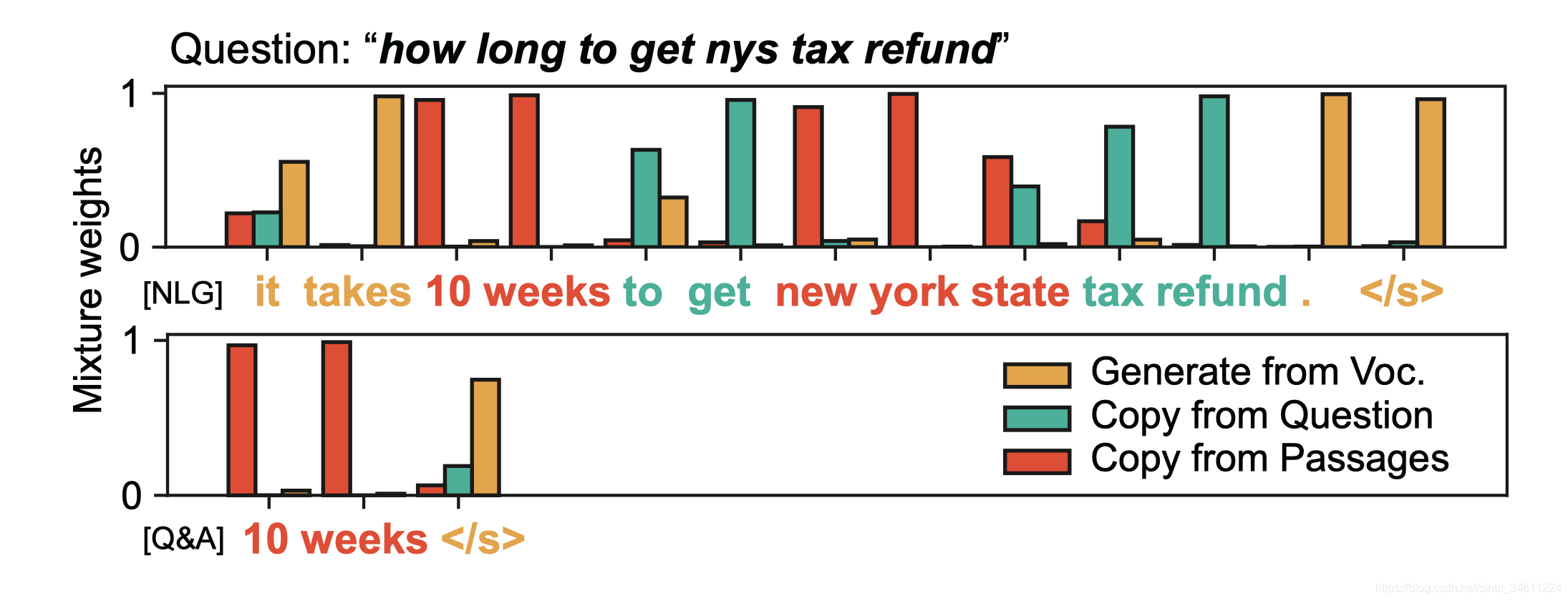
提出了一个端到端的模型——masque【风格可控的多源头摘要式模型】,模型根据给定的风格生成答案序列,生成词的来源可以是问题、段落和词表。下图是Masque生成答案的可视化样图:
Model
Overview
模型大体是Transformer和PG-Net的组合,并且利用了两个二分类任务来辅助生成答案序列,整个模型的框架如下图所示:
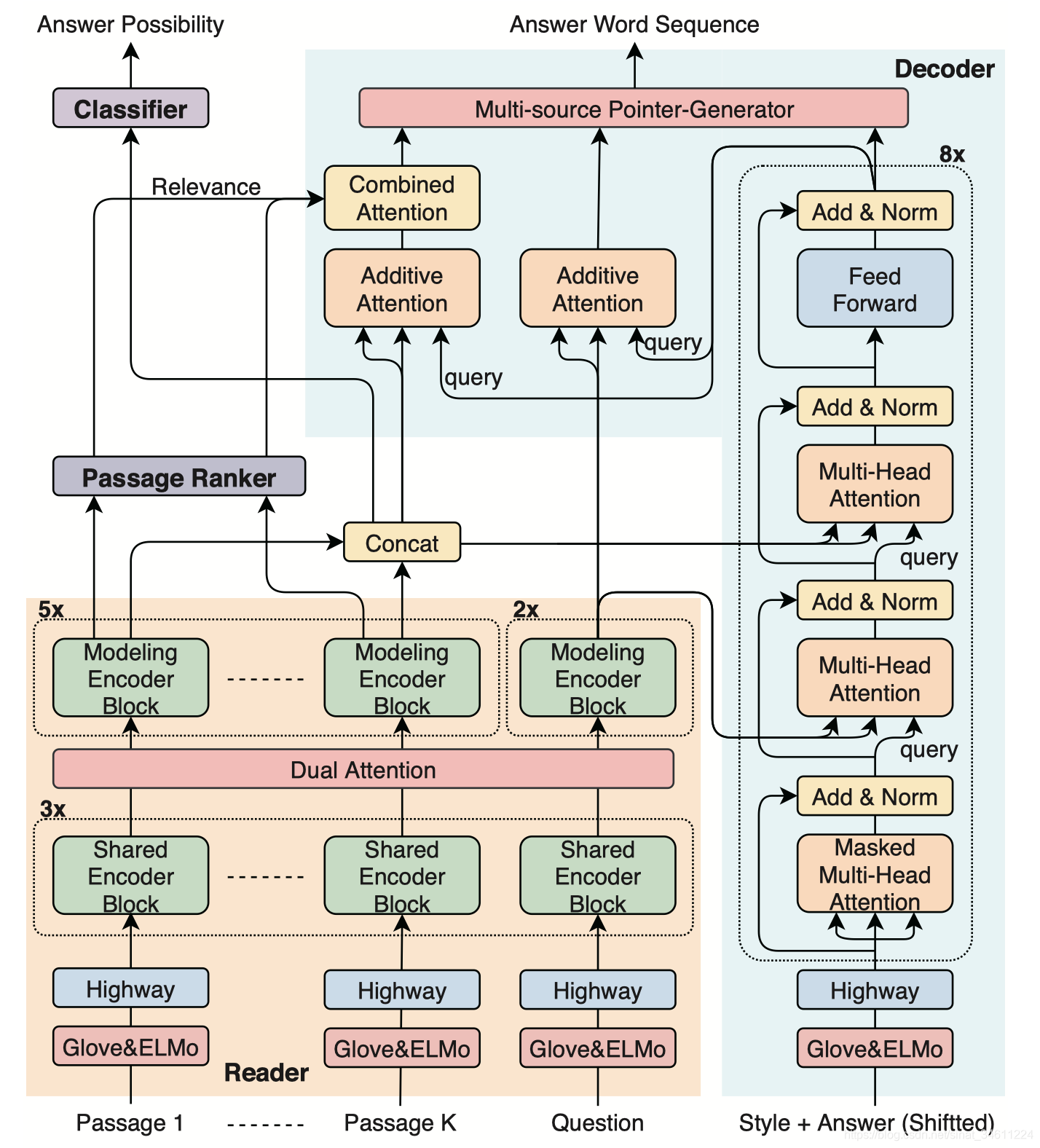
整个模型的输入是问题、所有段落、答案风格,输出是答案序列、段落是否用到的概率分布以及问题是否可回答的概率分布。
一共分为四个部分:
-
The question-passages reader: 建模问题与段落之间的关系;
-
The passage ranker: 找寻与问题相关的段落;
-
The answer possibility classifier: 识别出可回答的问题;
-
The answer sentence decoder: 根据给定的风格生成词序列。
question-passages reader
问题和段落的每个token取其Glove和ELMo词表示串联,因为ELMo是自带位置信息的,因此也就没用Position Embedding,过共享的Highway Net再经过线性映射到d维。把最后得到的向量用x表示。
之后,每个x过一个blocks=3的共享的Transformer Encoder,分别得到问题和段落的表示 , ,具体的运算不详细说明了,详见参考文献 [2]。d是词表示的维度,J和L分别是答案和段落的序列长度。这一层作用更多在于语义分析【词法、句法】。
Dual Attention层的运算比较复杂,不过大致是co-attention的运算,详见参考文献 [4]。首先算每个段落与问题的相似度矩阵,然后用相似度矩阵及其转置对问题和段落进行重表示,得到 , 。这部分更多在于计算交互信息,多角度地观察问题更关注段落的哪些部分。
最后问题和段落分别过blocks=2、blocks=5的Transformer Encoder,进行融合和降维,最终该模块的输出是问题表示 , 。
passage ranker
该模块是一个二分类器,输入每个段落初始时刻的隐藏层状态,过一个sigmoid函数得到每个段落与问题的相关程度 。算出来之后,一用来对段落做二分类,二用来加强段落的表示,这个在Decoder部分还要用到。
answer possibility classifier
该模块也是一个二分类器,输入每个段落初始时刻隐藏层状态的串联,过一个sigmoid函数得到问题是否可回答的概率 。
answer sentence decoder
核心部分,用Transformer代替Seq2Seq,输入词的表示与Encoder端的唯一区别是用的单向ELMo。
之后先过Masked多头Attention,接着分别对问题和段落的表示做多头Attention,最后过一个GLEU前馈。在得到Transformer Decoder的t-th时刻隐藏层状态 后,分别对Encoder得到的表示做加法式的Attention。
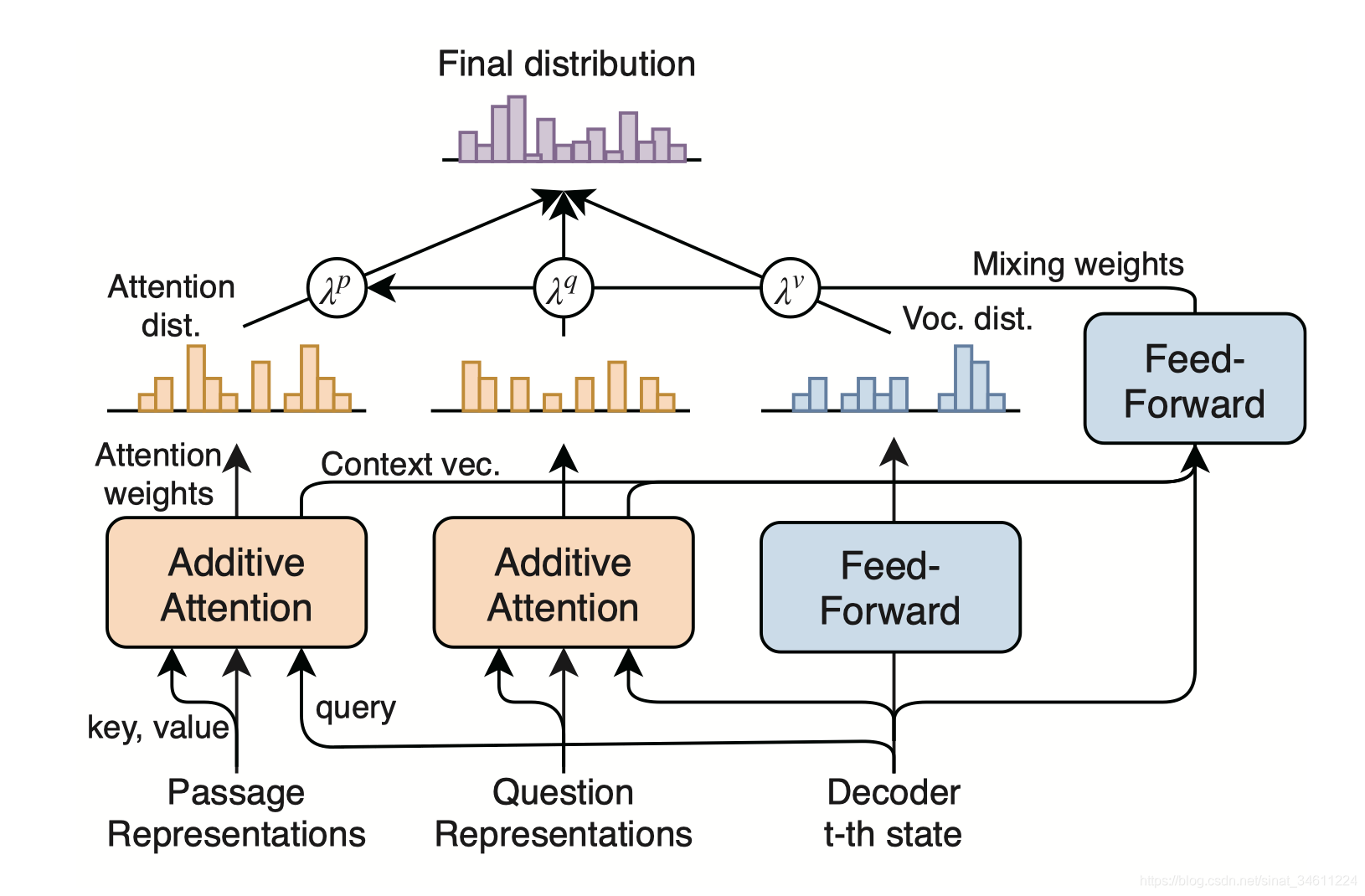
之后的运算稍微有点复杂,还是上公式吧:
这里段落的权重还要继续算一下,用passage ranker得到的每个段落与问题的相关程度再一次加强Attention,用的就是简单的标量乘和归一化。
最后得到PG-Net的联合概率分布:
其中 。
Training
模型训练的目标函数包括三个部分,decoder端的负对数似然和两个二分类交叉熵。
Experiment
Datasets
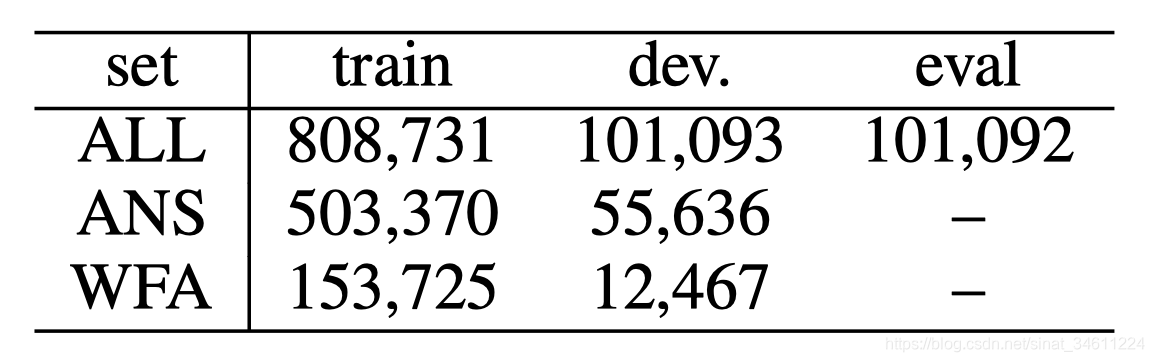
文章把数据集做了处理,分成三种:
- ALL: MS MARCO 2.1
- ANS: answerable questions
- WFA: answerable questions and well-formed answers
用来验证三个模块的性能。
作者把实验参数也列举的比较详细,batch大小为80,一共训练8轮,在8个P100型GPU上跑整个MARCO 2.1数据集花了6天,可见模型还是比较庞大的。
Results
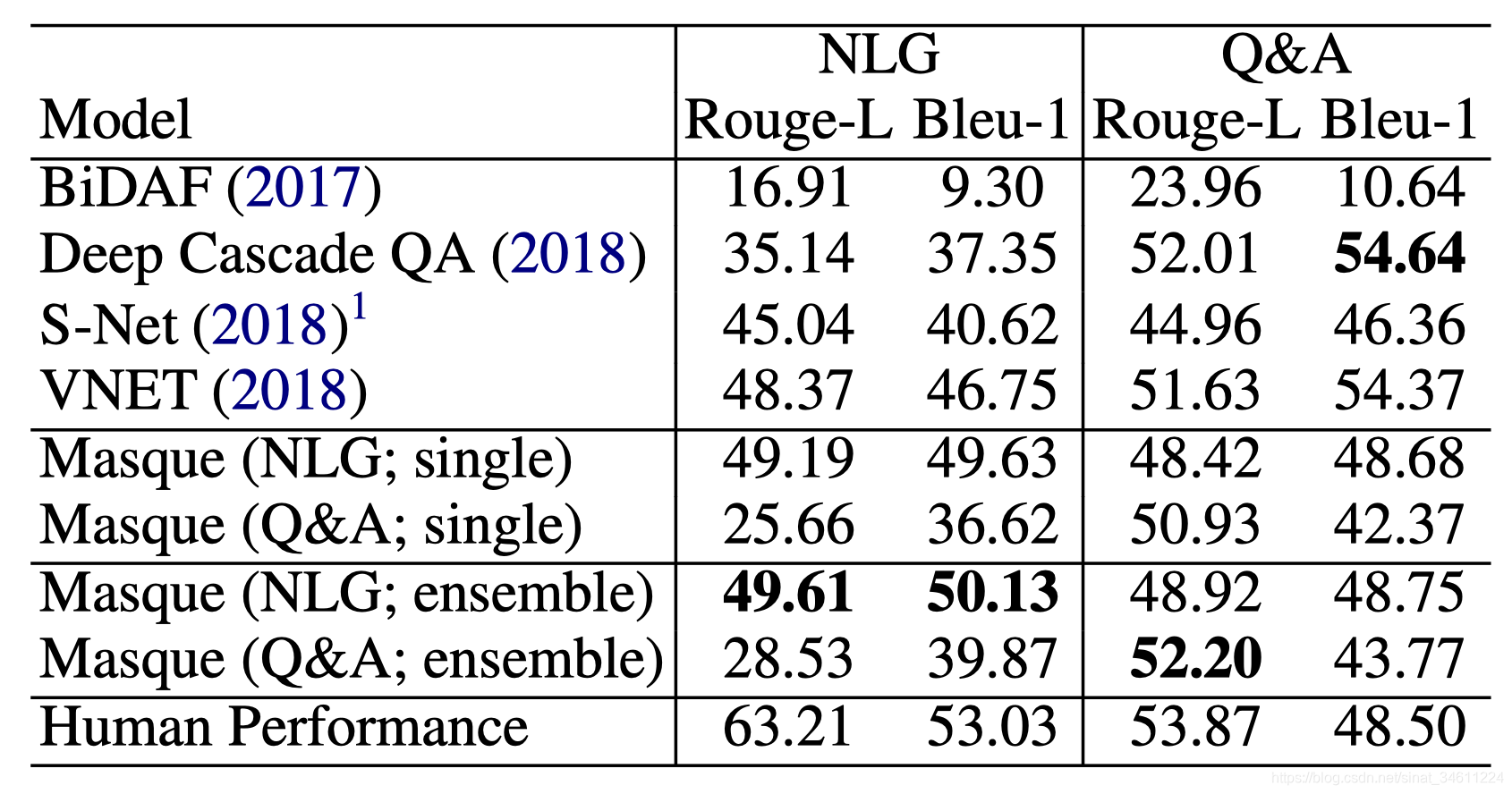
本文实验结果在MARCO两个任务上在发表的时候都是最高的,算是MARCO里程碑式的模型。
Analysis
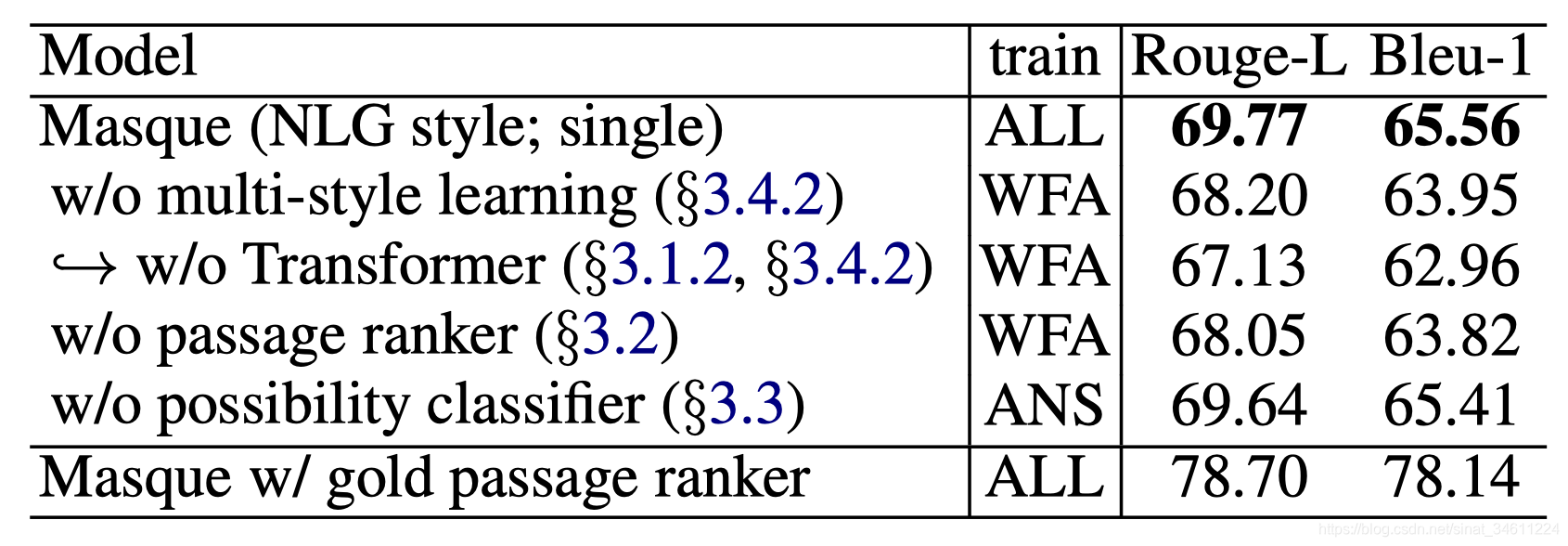
从去除实验可以分析到:
- 多风格学习改善了生成模型的效果;
- 基于Transformer的PG-Net改善了生成模型的效果;
- 辅助任务改善了生成模型的效果。
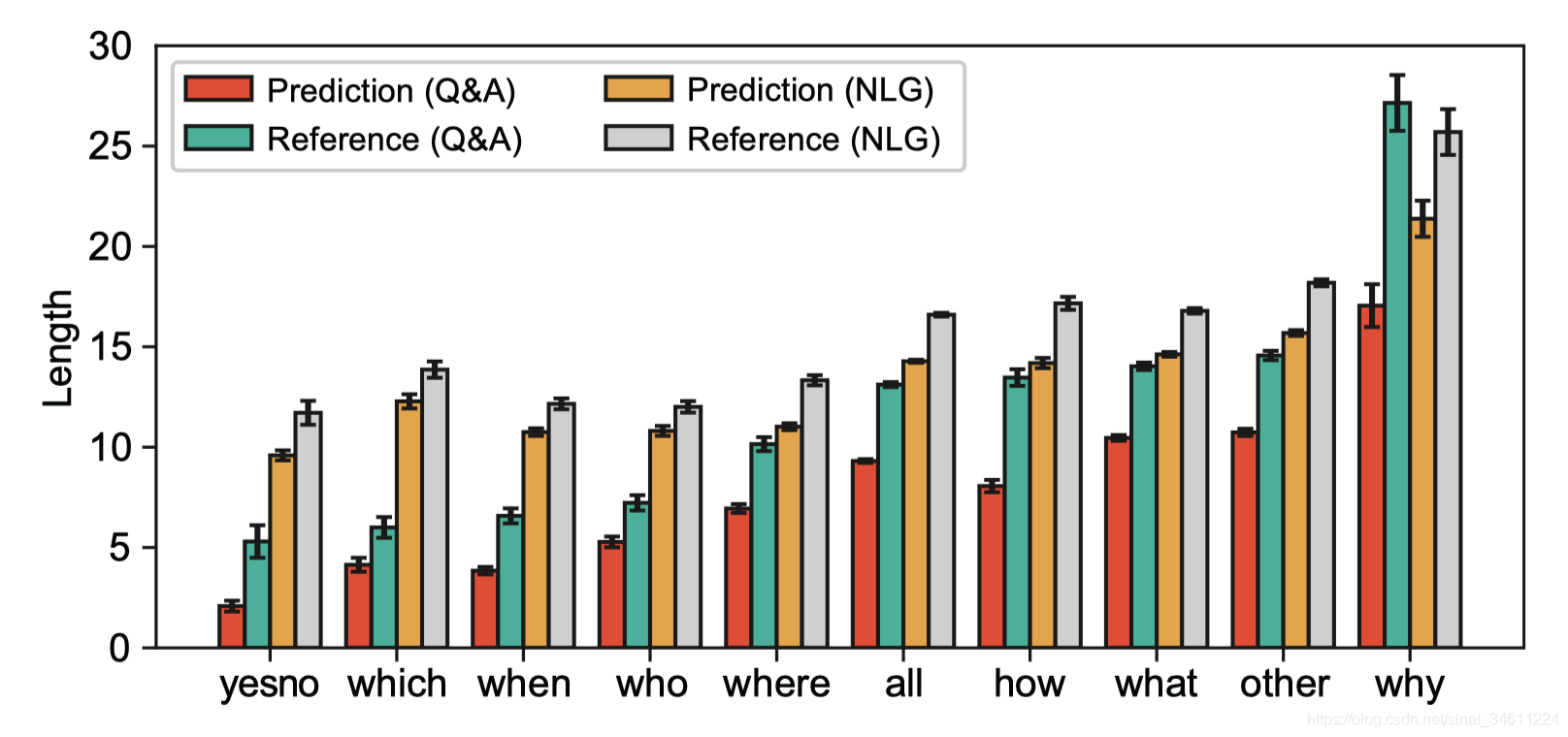
从上图可以看出,Masque可以有效地控制生成答案序列的风格。

Masque较适合回答 (a) natural language, (b) cloze-style, and © keywords questions这类问题。

Masque对 (d) The Q&A was incorrect. (e) The answers were not consistent
between the styles. (f) Copying from numerical words这类问题解决的不好,或者说模型不是很敏感这类问题。
Conclusion
- PG-Net较适合生成式阅读理解,把多文档阅读理解看作摘要问题解决;
- 选择适当的辅助任务,可以提升主任务的效果;
- 根据给定风格生成相应的答案,值得进一步探索。
References
- Multi-style Generative Reading Comprehension. Kyosuke Nishida, Itsumi Saito, Kosuke Nishida, Kazutoshi Shinoda, Atsushi Otsuka, Hisako Asano, Junji Tomita, https://arxiv.org/abs/1901.02262
- Attention Is All You Need. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. In NIPS, 2017.
- Get To The Point: Summarization with Pointer-Generator Networks. Abigail See, Peter J. Liu, Christopher D. Manning. In ACL, 2017.
- Caiming Xiong, Victor Zhong, and Richard Socher. Dynamic coattention networks for question answering. In International Conference on Learning Representations (ICLR), 2017.
- Nguyen, T., Rosenberg, M., Song, X., Gao, J., Tiwary, S., Majumder, R., & Deng, L. (2016). MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. CoRR, abs/1611.09268.
- https://github.com/dfcf93/MSMARCO
- https://github.com/IndexFziQ/MSMARCO-MRC-Analysis
- http://msmarco.org/leaders.aspx